







环境准备:
- 假设已经安装有Centos6.4服务器的vmware虚拟机,并且与本机win相互连通(安装不多说,百度一大把);
- jdk与hadoop版本:jdk-8u65-linux-x64.tar.gz,hadoop-2.7.1.tar.gz;
- 为了操作方便,我使用Xshell5远程连接Centos服务器,winscp用于传输文件到服务器上;
- 我服务器IP地址是192.168.8.100
文件下载链接:http://pan.baidu.com/s/1ntlIepV 密码:o441
#1.准备工作
开始之前,使用winscp(或者其他)登陆到服务器Centos,把需要文件传到相应目录:
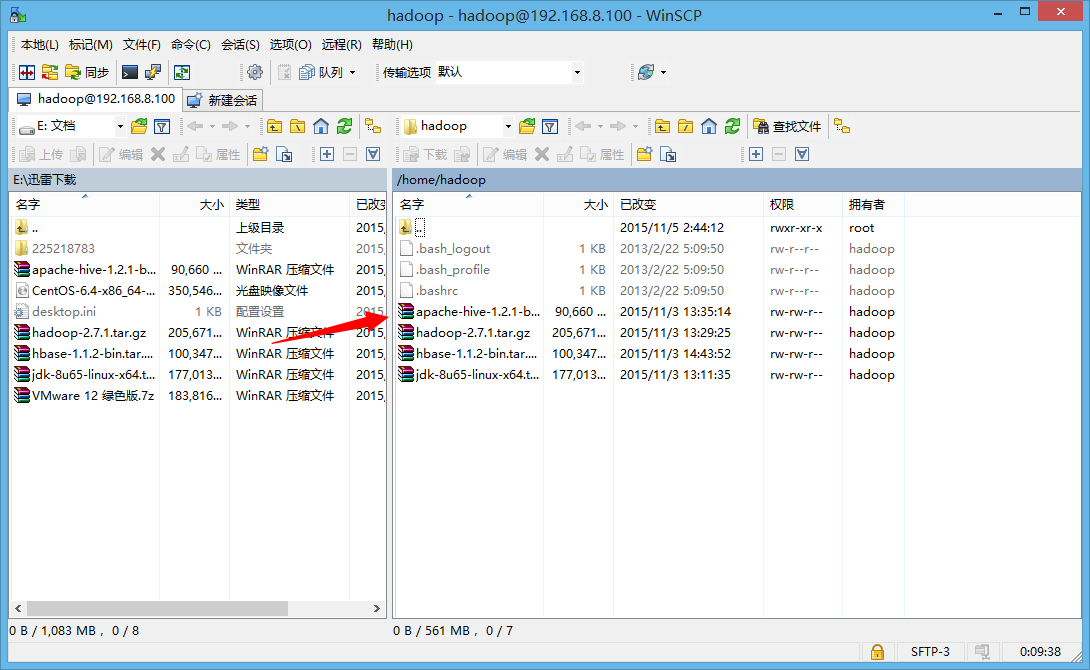
##修改主机名:
为了使用方便,我修改主机名(非必要)为“m”
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=m
##修改主机名和IP的映射关系:
修改好映射关系之后,m就等同于IP地址192.168.8.110
vi /etc/hosts
192.168.8.110 m
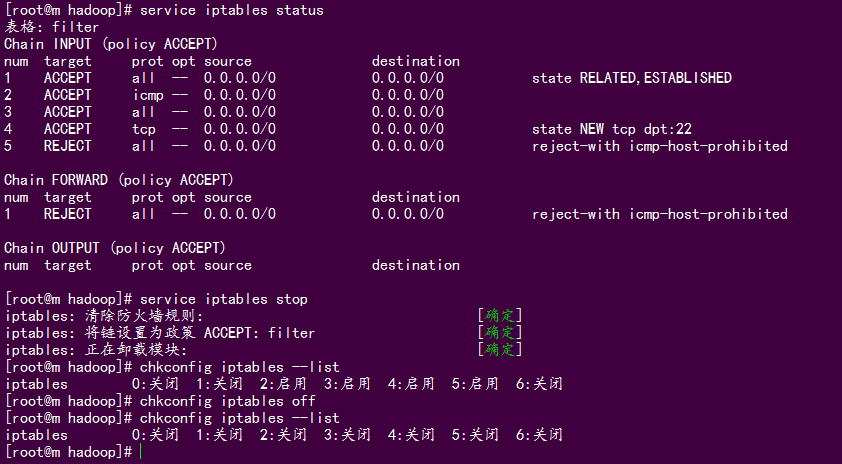
##关闭防火墙:
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
最后重启Linux
reboot
#2. 配置jdk环境变量
我使用的是jdk-8u65-linux-x64.tar.gz,配置方法见http://blog.csdn.net/songzhilian22/article/details/49045809
我的jdk位置是:/usr/java/jdk1.8.0_65
#3. hadoop伪分布式安装
##3.1 解压hadoop文件
#在usr下创建hadoop目录
mkdir /usr/hadoop
#解压hadoop文件到刚刚创建的目录
tar zxvf hadoop-2.7.1.tar.gz -C /usr/hadoop/
##3.2 修改配置文件
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置
# 进入到hadoop2.x的配置文件目录
cd /usr/hadoop/hadoop-2.7.1/etc/hadoop/
####第一个:hadoop-env.sh
# 找到“export JAVA_HOME=${JAVA_HOME}”改为
export JAVA_HOME=/usr/java/jdk1.8.0_65
####第二个:core-site.xml
vi core-site.xml
<configuration>
<!-- 制定HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://m:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.1/tmp</value>
</property>
</configuration>
注意:hdfs://m:9000中的m可以是IP地址192.168.8.100
####第三个:hdfs-site.xml
vi hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量,这里是伪分布式,所以填1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
####第四个:mapred-site.xml
配置文件中没有mapred-site.xml文件,需要把mapred-site.xml.template改为mapred-site.xml,再进行配置
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
####第五个:yarn-site.xml
<configuration>
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>m</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
##3.3 把hadoop添加到环境变量
vim /etc/proflie
#HADOOP_HOME
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile #使配置立即生效
#4. 格式化namenode(是对namenode进行初始化)
hdfs namenode -format
# 或者
hadoop namenode -format
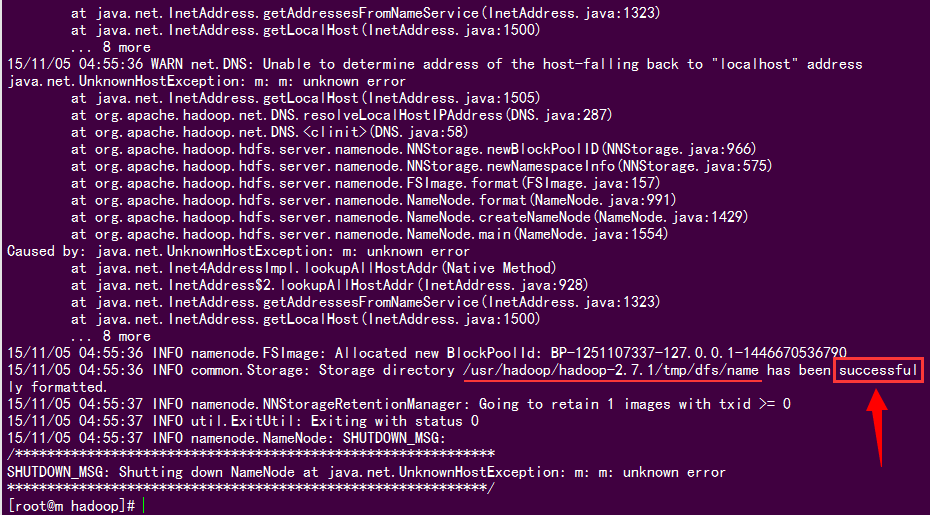
如果看到“Storage directory /usr/hadoop/hadoop-2.7.1/tmp/dfs/name has been successfully formatted.”,说明格式化成功
#5. 启动hadoop
# 先启动HDFS
start-dfs.sh
# 再启动YARN
start-yarn.sh
# 或者单独使用
start-all.sh
#6. 验证是否启动成功
使用jps命令验证:
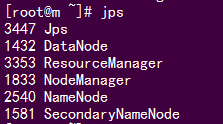
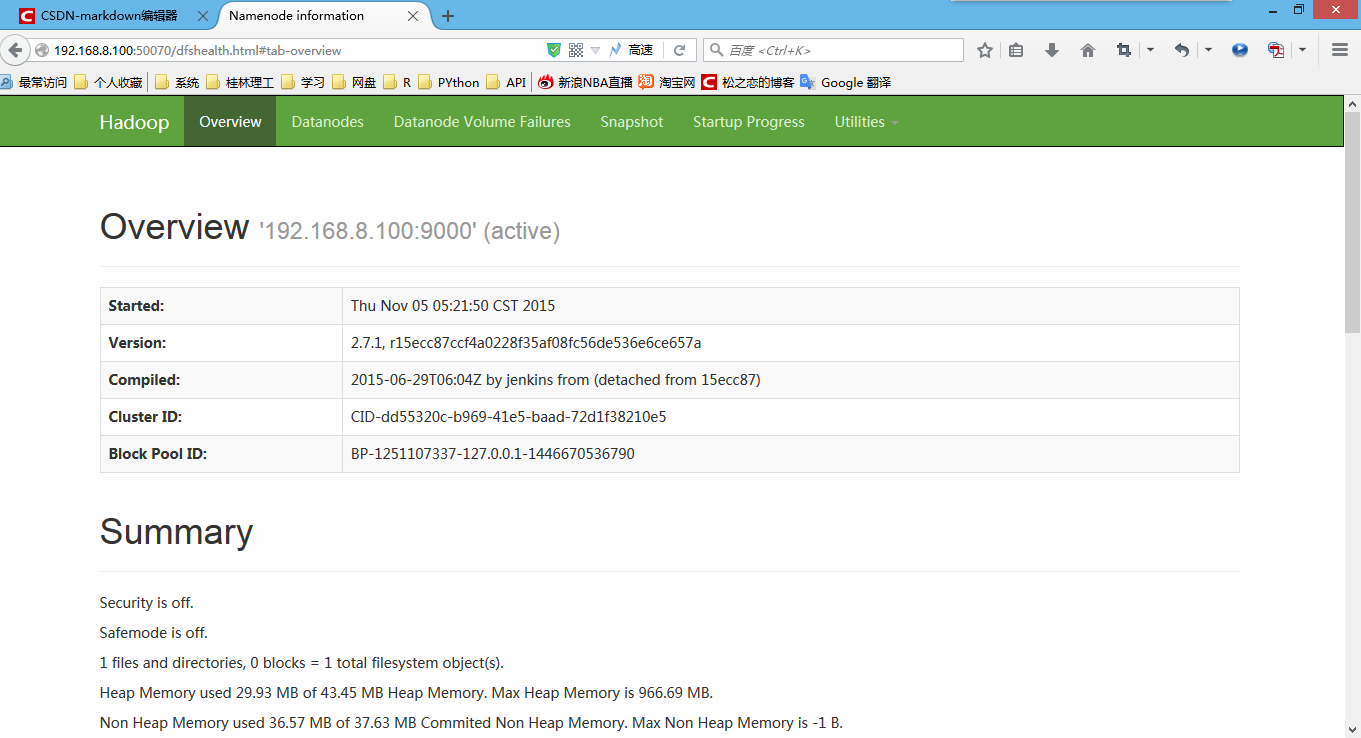
http://192.168.8.100:50070 (HDFS管理界面)
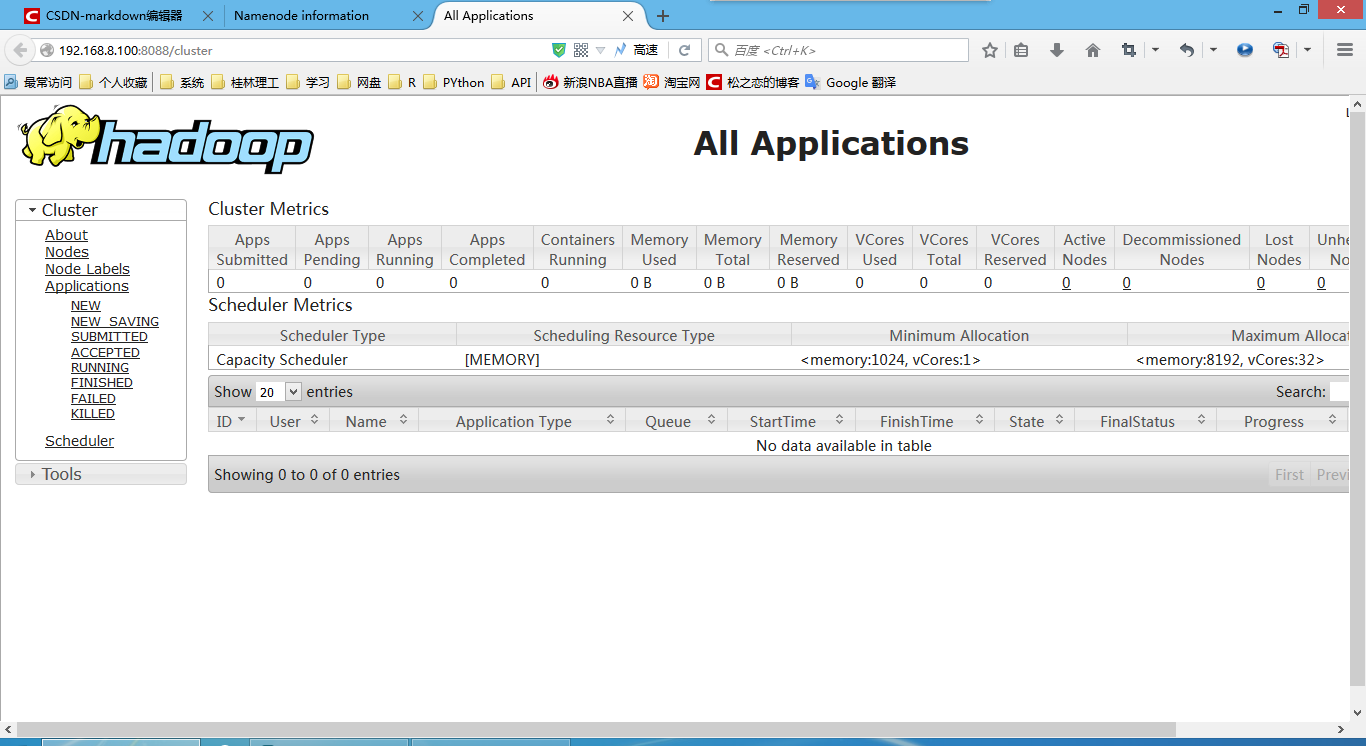
http://192.168.8.100:8088 (MR管理界面)
欢迎访问我的个人站点:http://bgods.cn/














 62
62











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









