







通过游戏编程学Python
通过游戏编程学Python(5)— 猜成语(下)
通过游戏编程学Python(4)— 猜成语(上)
通过游戏编程学Python(3)— 赌大小
文章目录
前言
大家好,五一放假了,问哥决定更新勤快点,另一方面,也是因为上节课的猜成语小游戏引发了一些思考:我们怎么样扩展我们已开发的项目,添加更多的功能和乐趣。就比如猜数字、赌大小这样简单的入门小游戏,一样可以放在一个大的项目里,作为某个小的环节。比如,有朝一日我们开发了一款RPG,就可以给玩家角色去赌大小、猜数字的机会,获取游戏中的金币,进而有更多的交互项目等等。而且,当以后我们学了GUI图形化编程后,这些不起眼的小游戏也都可以用另一种形式焕发新生。
说到GUI,迄今为止,我们一直在Python的终端下开发文字游戏,而且问哥计划在介绍GUI编程之前还要继续用文本介绍几个经典小游戏,于是问哥觉得还是有必要稍微介绍一下终端的运行方法。
此外,为了下节课做准备,今天也会简单介绍一下文本文件的读取方法,正好也用得到。
如此一来,虽然是一节“番外篇”,并没有新的游戏,但它却含有不少干货,也希望大家都能有所得。
一、知识点
- Python自带的编程环境
- 读取txt文本文件
- r字符串与f字符串
- 列表生成式
- random.shuffle()方法
二、猜成语小游戏的扩展
1. 玩法简介
游戏的整体框架基于上节课的内容,但是在成语的提示上由提示词改为乱序显示成语的每个字,由玩家输入正确的成语;修改猜错单词的机会为3次(6次实在太多了哈)。此外还加入了计分功能,在游戏结束后统计玩家一共猜对了多少个成语。
游戏截图如下:

2. 游戏流程
3. 程序代码
全部代码:
附上我使用的200个成语的TXT文件下载链接,用于练习。
import random
# 从TXT文本文件中读取成语组成词库
# f = open(r'C:\Coding\word.txt', 'r', encoding="utf-8")
# WORD = f.readlines()
# f.close()
with open(r'C:\Coding\word.txt', 'r', encoding = 'utf-8') as f:
WORD = f.readlines()
# 列表生成式
WORD = [i.strip() for i in WORD]
def 猜成语(猜过啥, 词长):
# 确保玩家输入正确字数,且不会重复输入错误的词,然后返回玩家猜的汉字
while True:
print('猜猜看,这是什么成语呢?')
print()
猜 = input()
if len(猜) != 词长:
print(f'请输入{词长}个字的成语')
print()
elif 猜 in 猜过啥:
print('这个词你已经猜过了,换一个试试吧')
print()
else:
return 猜
def 再玩一次():
# 如果玩家输入yes或y,则游戏从头再来,否则游戏结束
print('还要继续玩吗?(yes-是,no-否)')
return input().lower().startswith('y')
def 乱序(原词):
# 把原有的词序打乱,组成新的词序
乱序 = list(原词)
random.shuffle(乱序)
# 检查乱序后的成语是否凑巧和原词相同,如果相同则再次打乱
while ''.join(乱序) == 原词:
random.shuffle(乱序)
# 返回乱序后的字组成的列表
return 乱序
# 游戏从这里开始
print('《 开 心 猜 成 语 2》\n')
错词表 = []
游戏结束 = False
电脑选词 = random.choice(WORD)
乱序选词 = 乱序(电脑选词)
# 定义一个新的变量用于记录猜对的次数
correct = 0
while True:
# 乱序显示要猜的成语
for i in 乱序选词:
print(i, end=' ')
print()
# 请玩家猜一个四字成语
猜 = 猜成语(错词表, len(电脑选词))
if 猜 == 电脑选词:
# 如果猜对了游戏结束
print('没错!就是“' + 电脑选词 + '”!你赢了!')
correct += 1
游戏结束 = True
else:
print('不对哦~\n')
错词表.append(猜)
# 检查玩家是否猜错太多次
if len(错词表) == 3:
# 显示状态(提示字, 电脑选词)
print('很遗憾,你已经猜错' + str(len(错词表)) + '次,游戏结束。' + '正确的成语是“' + 电脑选词 + '”。')
游戏结束 = True
# 询问玩家是否再玩一次
if 游戏结束:
if 再玩一次():
错词表 = []
游戏结束 = False
电脑选词 = random.choice(WORD)
乱序选词 = 乱序(电脑选词)
else:
break
print(f'您本轮一共猜对了{correct}个成语,再接再厉!')
3. 代码简析
相比较上节课的程序而言,有以下主要变化:
- 使用open方法从txt文件里读取成语建立词库(200个成语),而不用在Python里输入;
- 增加了一个新的自定义函数乱序(),接收一个参数,返回一个把成语打散汉字后的列表;
- 原有的自定义函数猜成语() 增加了一个形参词长,用来告诉函数比较玩家输入的字符长度是否等于系统选中的词(因为有可能是三字、五字成语或更长),如果不等则要求玩家重新输入;
- 增加了一个变量correct,每当玩家猜对成语后它的值增加1,当游戏结束后在屏幕上显示出玩家总共猜对多少成语。相当于一个简单的计分系统;
- 将玩家猜错的机会从6减成3——丰俭由君,当然你也可以改成任何数;
- 删掉不需要的自定义函数和变量。
三、知识点
1. Python自带的IDLE
如果不是经常需要编程,使用Python自带的编译器就完全足够了。以问哥电脑Win10系统安装的Python3.10.4版本为例,从官网下载好Python安装包以后,在开始菜单就可以找到类似下图的软件:
打开它,就是Python自带的命令行窗口了。(我们在Windows或Unix/Linux系统的命令行下敲击python回车,也可以进入控制台环境。)
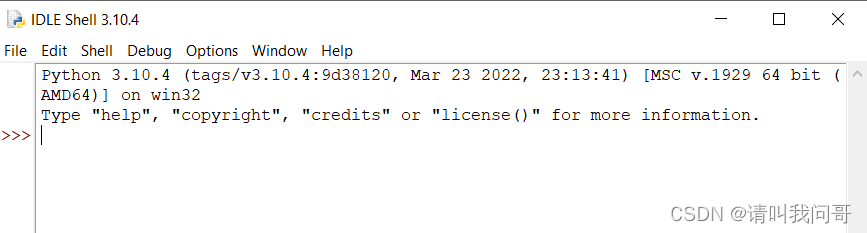
Python是解释型语言,逐条运行语句,所以我们可以在控制台里像一问一答一样和Python交互,如:
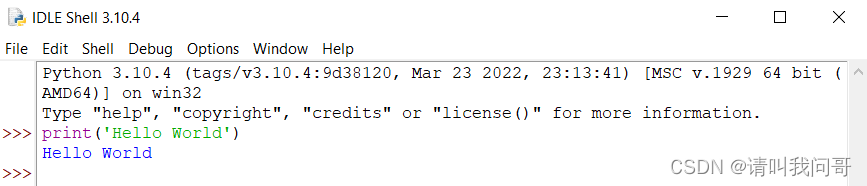
同样,我们也可以把所有语句都写到文本文件里,后缀改成py,也就是python程序文件,交给编译器运行。打开左上角的File菜单,新建New File,或打开Open已有的py文件都可以。
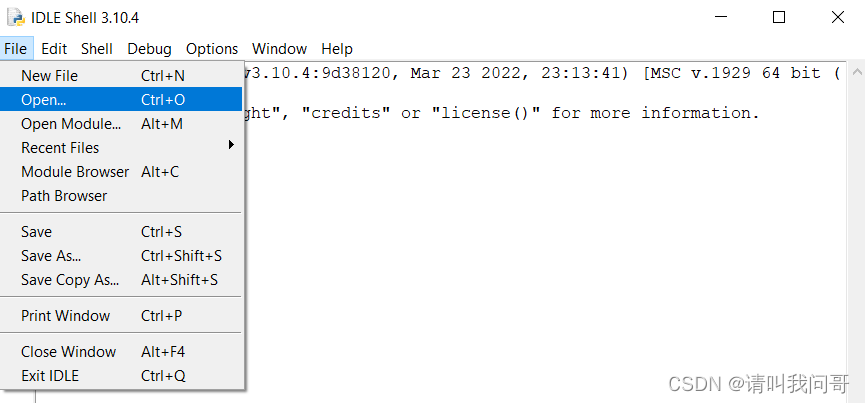
然后在新跳出的窗口里输入代码(或已有代码),点击菜单栏的Run运行程序,或者F5快捷键,就可以运行程序了。
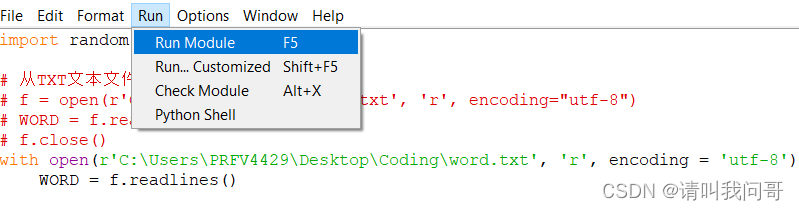
程序运行过程中生成的所有的文本输入输出信息(如print() / input())都会在控制台输出。
2. txt文本文件的读取
在Python里常用的读取txt文件的方法是open()方法,接收的必选参数有文件所在路径,以及打开方式(本例中是’r’,read-only只读)等,都是字符串格式。可选的参数有编码方式encoding,这里使用’utf-8’的编码方式读取txt文件。编码方式就像一把钥匙,如果钥匙不对,程序可能会报错或者读取出一串乱码。
open()方法返回一个文件类型的对象,我们将它赋值给变量f,然后在后面的程序里就可以操作它了。
f = open(r'C:\Coding\word.txt', 'r', encoding="utf-8")
WORD = f.readlines()
f.close()
注意:操作完该文件后,必须使用文件对象的close()方法将其关闭,不然它一直会存在内存里。如果没有正常关闭的话,文件将无法被修改。
readlines()方法
文本文件类型的对象也有很多方法,今天我们先认识和学习一下readlines()方法,该方法就是逐段读取txt文件的全部内容,以换行符为界,然后将每个段落的字符串作为元素保存在一个列表里返回。
观察一下txt文件里的内容:

再比较一下常量WORD接收的readlines()方法返回的列表的内容,会发现txt里每一段(这里就是每个成语)都是列表里的一个元素字符串,而且换行符\n也作为字符串的一部分读取了进来。

with open() as …
问哥在示例中先给出了直接调用open()方法打开文件的语句,然后又将其注释掉,是因为我更加推荐使用with open…as的语句来调用。在这条语句里open()的使用方法和实现的效果与直接调用相同,但是with open…as却有个很重要的优点,就是它会生成一个局部作用域,接收txt文件对象的f变量变成了一个局部变量。它像while语句,if语句,for语句一样,后面跟上冒号“:”,然后代码块里的语句缩进。
with open(r'C:\Coding\word.txt', 'r', encoding = 'utf-8') as f:
WORD = f.readlines()
当代码块结束的时候,局部变量f自动消失,文件也自动关闭了,省去了前面使用f.close()关闭文件的步骤。这样,我们再也不用担心忘记写f.close()而把文件留在内存里了。甚至有时候读取文件出错,程序意外中断,with open…as也会自动把文件关闭,省去了不少烦恼。
3. r字符串与f字符串
不知道大家有没有在程序里注意到,我在使用open()语句的时候,文件路径的字符串前面有个小写的“r”,而在后面的print()语句里,我在字符串的前面又有个小写的“f”。
print(f'您本轮一共猜对了{correct}个成语,再接再厉!')
下面我们来简单聊一下这两种字符串的作用。
r字符串
r字符串的“r”是英文单词raw的意思,代表了后面跟着的引号里的字符串是以原始文本输入,不作转义。问哥在程序里使用r字符串也是因为,open()方法里需要用字符串提供文件的路径,但是windows操作系统的路径符为“\”,而我们之前说过Python会把“\”字符转义,所以不能正常识别。于是我在字符串的前面写上一个r,就表示不要转义“\”,于是程序就可以正常识别路径字符串了。
当然Windows也可以识别“/”的路径符,把“\”改成“/”就可以,或者再加一个“\”将反斜杠再转义回来,问哥这里为了介绍r字符串就没这样做了。而且问哥觉得r字符串最省事,所以强烈推荐。
f字符串
f字符串是在Python3.6版本才开始引入的。“f”是英文单词format的简写,它的出现帮助我们简化了字符串拼接变量的操作。比如在程序里有这么一句:
print('很遗憾,你已经猜错' + str(len(错词表)) + '次,游戏结束。' + '正确的成语是“' + 电脑选词 + '”。')
这里要打印一句话,里面有固定的字符串(引号里的内容),也有变量(电脑选词),还有语句(str(len(错词表))),要把这三种不同形式的内容拼接成字符串,我们有以下几种办法:
- 使用“+”将它们连接起来,就想例子里的那样。但是这样会显得整个语句十分臃肿,而且还需要将非字符串的变量,比如数字,先转换成字符串。当变量和语句过多的时候,很容易输错。
- 很多C语言过来的同学会使用一种字符串插值的表示方法。使用%加一个英文字母占位,比如%s代表字符串,%d代表数字等等,然后在字符串的后面跟上%( ),并在括号里按顺序放进变量名。比如上面这个例子可以写成下面这样:
print('很遗憾,你已经猜错%d次,游戏结束。正确的成语是“%s”。'%(len(错词表),电脑选词))
- Python为字符串的对象提供了一种format()方法。在字符串里变量出现的位置用大括号{ }代替,括号里可以放入变量名,也可以放入编号,也可以不填,只要后面跟上format()方法,小括号里再按顺序放入变量名。这种方式其实就是函数的传参,大家多看几遍就能明白。
print('很遗憾,你已经猜错{}次,游戏结束。正确的成语是“{}”。'.format(len(错词表),电脑选词))
- 最后一种方法就是Python3.6版本以后为我们提供的 f 字符串,它的使用方法和format()方法类似,只不过是直接把变量放入了大括号{ }里,使得字符串变得更加可读,也是问哥极力推荐的一种方法。比如本例可以写成下面这样:
print(f'很遗憾,你已经猜错{len(错词表)}次,游戏结束。正确的成语是“{电脑选词}”。')
这样一来,其他位置的 f字符串就很容易看懂了。
4. 列表生成式
先出一道思考题,如果有一个列表a = [1, 2, 3, 4, 5],我们想把列表里的每个元素按顺序拿出来计算平方,然后将平方值放在一起组成一个新列表,就像[1, 4, 9, 16, 25]。使用Python,我们要怎么做呢?
一般情况下,无外乎以下三步:
- 创建一个空列表b;
- for i in range(a) 循环遍历列表a;
- 使用列表b的append()方法将 i 的平方加到列表b里。
写成语句就像下面这样:
b = []
for i in a:
b.append(i**2)
Python觉得这样可能不够简洁,于是给我们提供了一种根据已有列表(或range()来决定列表长度)来创建新列表的方法,叫做列表生成式。上面三行语句使用下面一条语句就可以解决:
b = [ i**2 for i in a ]
注意看生成式里的位置,第一部分i**2是原来三行语句里的append()里的内容,第二部分for i in a就是照搬原来三行语句里的第二行,然后生成式两边用中括号[ ]括起来。如此便是生成式的格式了。别急,强大的列表生成式还支持if判断语句,只要把它作为第三部分放在后面就可以了。
比如我想得到列表a里所有奇数的平方组成的列表,也就是[1, 9, 25],用生成式就可以这样写:
b = [ i**2 for i in a if i%2 == 1]
注意:生成式里不能出现逗号“,”和赋值等号“=”
列表生成式还可以配合range()生成固定长度的列表,比如下例就生成了一个由5个字符0组成的列表:

大家多观察,多用心体会一下列表生成式的规则,其实并不复杂。以后我们再写列表的时候,可以先用append()方法写一遍,然后再试着把它变成生成式的写法,用不了几次就没问题了。而且这种写法确实更省事,熟练了以后,你会爱上它的(笑)。
此外,列表生成式也支持嵌套判断,从外向内依次并排放入判断语句即可,比如下面这个例子,先写外循环i,再写内循环j:

但是因为嵌套判断的生成式使用的也比较少,初学者并不用太着急掌握。列表生成式甚至自己也可以嵌套,这里就不详细展开了。我们只要掌握最实用的,其它的只要见到能认识就够了。
字符串的strip()方法
另外,如前面展示的,本例中从txt文件里直接读出的词库里每个元素都带有一个“\n”换行符,这里我们就可以使用字符串的strip()方法,将其左右的空格、换行符等统统删除掉,然后得到一个新的列表,方便我们后面对这些成语做进一步的字符串处理。
5. random.shuffle()方法
我们已经学习了random模块里不少方法,今天再加一种,shuffle()方法。
shuffle英文就是“洗牌”的意思。顾名思义,该方法将一个列表中的所有元素就地随机打散重新排列。一定要注意“就地”两个字,因为该方法不返回任何值,而是直接修改原列表。
本例为了实现将成语的汉字打乱的效果,自定义了函数乱序(),其中便使用了random.shuffle()方法。而为了使用该方法,首先要把原本成语的一个字符串拆成由它的字组成的列表。于是我们使用list()函数直接就可以将字符串转变成列表。
def 乱序(原词):
# 把原有的词序打乱,组成新的词序
乱序 = list(原词)
random.shuffle(乱序)
# 检查乱序后的成语是否凑巧和原词相同,如果相同则再次打乱
while ''.join(乱序) == 原词:
random.shuffle(乱序)
# 返回乱序后的字组成的列表
return 乱序
当然,由于shuffle()方法是随机打乱列表元素,所以是有概率打乱后的列表看起来并没有变化(尤其是只有四个元素的时候,大概1/24的机会没有变化),于是我们需要检查一下打乱后的列表中字的顺序是否与原词相同。而为了将列表与字符串比较,我们需要先统一格式。我们既可以使用list()函数将字符串变成列表,也可以将列表转换为字符串。注意,可不是使用str()函数哦。
字符串的join()方法
本例中使用了字符串的join()方法将一个列表转换为字符串。join()方法的小括号里放入一个全字符串元素的列表,意思就是“使用该字符串将列表中的所有字符串元素连起来”。比如:

而如果使用空字符串,比如本例,就相当于把列表中的所有元素“无缝”连接起来了。于是,我们就可以用它来和原词进行比较,看看是否改变了顺序。
四、进一步扩展:猜单词
这样我们就完成了一个新版本的猜成语游戏,虽然它看起来好像更简单一些,但借着这个版本,我们又学习到不少新的方法。尤其是我们还可以将其进一步扩展,比如,猜单词:

没有用到任何新的知识,只是把词库换成英文单词,然后把显示的“成语”两个字换成“单词”,就可以变成一个新游戏——猜单词。但是由于语言习惯的不同,乱序猜英文单词,要比猜成语难得多,所以也可以增加更多试错的机会。
因为代码高度雷同,问哥就不贴出来了,大家可以做一个课后练习题,动手改改看。
我们甚至还可以再进一步,比如为了避免同样的字母可以组成多个单词,也是为了降低难度,我们可以固定单词的首尾字母不变,只是乱序中间的其他字母,如果这样的话,程序要怎样改呢?也请大家开动脑筋,思考一下吧。
总结与思考
问哥抛砖引玉,希望大家能够发掘出更多有趣的点子,不管是玩法上,还是形式上,比如字体排版等等,都可以把老游戏改成自己喜欢的样子。在这个过程中,大家也能更加熟练掌握Python的知识。
另外,问哥想指出一点,有时候为了实现某个功能,我们可以通过不同的代码来实现。这其实没有多少差别,尤其在我们这样的小游戏上,差别可谓不值一提。但是在比较大的程序里,不同的代码所实现功能的速度,可能就天差地别了。这里和算法与数据结构相关,并不是问哥这个《通过游戏编程学Python》系列的范畴。
但是,如果看到别人提供的不同实现方法,我们应该持积极开放态度,因为它可能会为我们带来新的启示,甚至让我们学到新的知识。
比如,本例中乱序成语/单词的方法,问哥为了偷懒,使用了random的函数shuffle(),但是还有另一种字符串切片的方法实现乱序的效果,如下:
while 原词:
位置 = random.choice(range(len(原词)))
乱序词 += 原词[位置]
原词= 原词[:位置] + 原词[(位置+ 1):]
print('乱序后的词语:', 乱序词)
这里就不展开讨论了,大家感兴趣的话也可以学习一下。
好了,问哥要接着准备Python的新知识点——字典了,毕竟上节课说好的。今天内容也不少,就先到这里啦,大家别忘记练习哦。下节课我们会做个实用一点的小程序,因为我们真的会做一个字典(笑)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











