







深度学习前夜
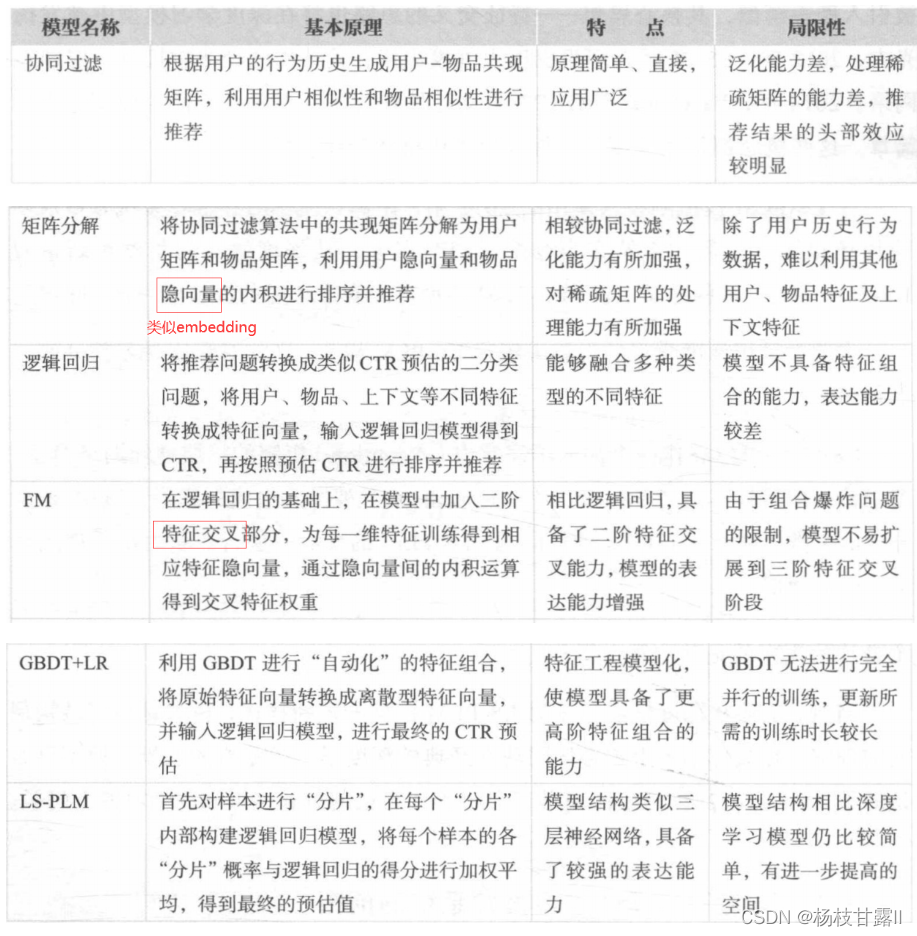
协同过滤CF
UserCF
常用的用户相似度计算:余弦相似度、皮尔逊相关系数(用 用户平均分/物品平均分 来修正各评分,减小用户评分偏置的问题)
最终结果的排序:相似用户评分的加权和
缺点:用户数>物品数,user相似度矩阵存储开销大;用户历史数据稀疏
更适合新闻推荐这种兴趣点比较分散的场景
ItemCF
更适合电商平台这种兴趣点比较稳定的场景
发展
协同过滤泛化能力弱(无法把两个物品相似推广到其他物品上),导致长尾现象--由此产生了矩阵分解、逻辑回归模型等等
矩阵分解MF
将协同过滤的邻接矩阵分解为m*k的用户矩阵和k*n的物品矩阵(k是隐向量的维度)

矩阵分解的求解过程:特征值分解(只能用于方阵)、奇异值分解(要求矩阵稠密,计算复杂度高)、梯度下降
梯度下降的正则化:是为了让权重更小,使得拟合的曲线波动更小
相比协同过滤的优点:
由于隐向量的存在,任意的用户和物品之间都可以得到预测分值。而隐向量的生成过程其实是对共现矩阵进行全局拟合的过程,因此隐向量其实是利用全局信息生成的,有更强的泛化能力;而对协同过滤来说,如果两个用户没有相同的历史行为,两个物品没有相同的人购买,那么这两个用户和两个物品的相似度都将为0。空间复杂度;更好的扩展性和灵活性,和深度学习的embedding思想不谋而合
消除打分偏差:
不同用户的打分标准不同,不同物品的衡量标准不同,常在矩阵分解时加入用户和物品的偏差向量来消除用户和物品打分的bias

最终的优化目标:

逻辑回归LR
可以综合用户、物品和上下文等不同的特征,生成较为全面的推荐结果。(感知机也用于分类问题,但是输出离散值,逻辑回归输出连续值)将推荐看作分类问题,通过预测为正样本的概率对物品进行排序。将推荐问题转换成了点击率问题CTR
一般利用梯度下降、牛顿法、拟牛顿法进行模型训练
伯努利分布=两点分布
缺点:
表达能力弱,无法进行特征筛选、特征交叉等操作,会造成信息损失甚至是错误--衍生出因子分解机等复杂网络
辛普森悖论:在分组比较中都占优势的一方,在总评时有时候反而是失利的一方
FM-->FFM 自动特征交叉的解决方案
POLY2 暴力将特征两两交叉,也是线性模型
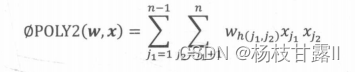
缺点:让特征向量(一般采用one-hot编码)更加稀疏;训练复杂度太大
FM模型-隐向量特征交叉
10年提出,用两个向量的内积代替了单一的权重系数,相当于为每一个特征学习了一个隐向量权重,和MF用用户隐向量和物品隐向量有异曲同工,泛化能力大大提高,复杂度降低,解决稀疏问题
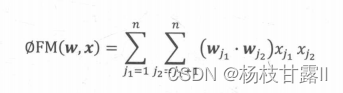
FFM模型-引入特征域
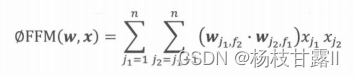
隐向量的变化,意味着每个特征对应的是一组而不是一个隐向量。
整体缺点:组合爆炸问题导致难以应用于高阶特征交叉
GBDT+LR--特征工程模型化的开端
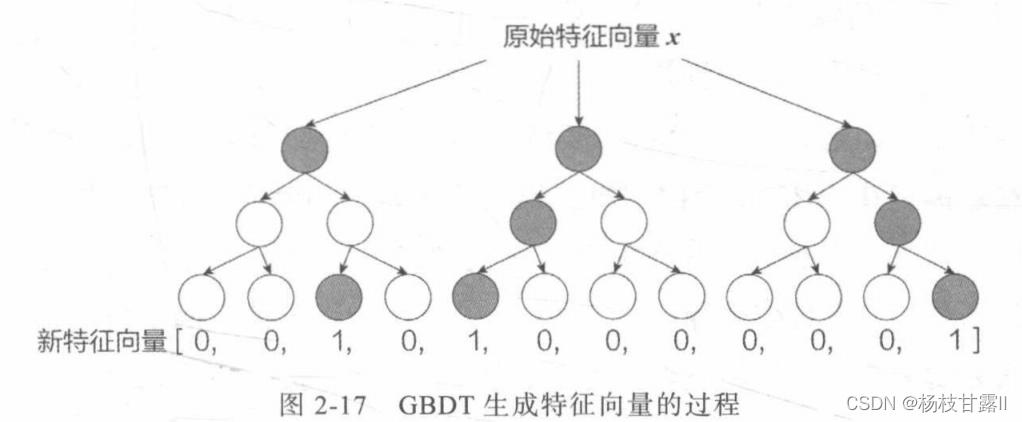
利用GBDT自动进行特征筛选和组合,生成新的离散特征向量,输入到LR模型,预估CTR
两部分独立学习,不需要梯度回传
GBDT是决策树组成的树林,学习方式是梯度回升,通过逐一生成决策子数的方式,无限逼近拟合函数,是一个自然的特征选择的过程。决策树的深度决定了特征交叉的阶数。但是容易过拟合。
LS-PLM--阿里前主流推荐模型(MLR混合逻辑回归)
(大规模分段线性模型-与加了注意力机制的3层神经网络相似)
先用聚类函数对样本进行分片,再在样本分片中应用逻辑回归进行CTR预估。然后将二者相乘后求和。

端到端指的是输入是原始数据,输出是最后的结果,非端到端不是直接的原始数据,而是在原始数据中提取的特征喂给模型去训练。
优点:端到端的、模型稀疏性强,轻量级
l1比l2范数更容易产生稀疏解。
总结















 2427
2427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









