







将MNIST图片压缩成二维数据,这样也可以在直角坐标系上将其显示出来,让读者更加形象的了解自编码网络在特征提取方面的功能
实例描述
在自编码网络中使用线性解码器对MNIST数据特征进行再压缩,并将其映射到直角坐标系上。
这里使用4层逐渐压缩784维度分别压缩成256、64、16、2这4个特征向量。
如果想要得到更好的特征提取效果,可以将压缩的层数变得更多,但由于Sigmod函数“天生”缺陷,无法使用更深的层,可以使用栈式自编码器解决。
1.引入头文件,定义参数变量
建立4层网络,为每一层分配节点个数。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 导入 MINST 数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/data/", one_hot=True)
#参数设置
learning_rate = 0.01
# hidden layer settings
n_hidden_1 = 256
n_hidden_2 = 64
n_hidden_3 = 16
n_hidden_4 = 2
n_input = 784 # MNIST data 输入 (img shape: 28*28)
#tf Graph输入
x = tf.placeholder("float", [None,n_input])
y=x
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_4],)),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.random_normal([n_hidden_1, n_input],)),
}
biases = {
'encoder_b1': tf.Variable(tf.zeros([n_hidden_1])),
'encoder_b2': tf.Variable(tf.zeros([n_hidden_2])),
'encoder_b3': tf.Variable(tf.zeros([n_hidden_3])),
'encoder_b4': tf.Variable(tf.zeros([n_hidden_4])),
'decoder_b1': tf.Variable(tf.zeros([n_hidden_3])),
'decoder_b2': tf.Variable(tf.zeros([n_hidden_2])),
'decoder_b3': tf.Variable(tf.zeros([n_hidden_1])),
'decoder_b4': tf.Variable(tf.zeros([n_input])),
}
2.定义网络模型
下面代码定义编码和解码得额网络结构,这里使用了线性解码器。在编码的最后一层,没有进行Sigmod变换,这是因为生成的二维数据其数据特征已经变得极为主要,所以我们希望能够透传到解码器中,少一些变换能够最大的保留原有的主要特征。
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
# 构建模型
encoder_op = encoder(x)
y_pred = decoder(encoder_op) # 784 Features
cost = tf.reduce_mean(tf.pow(y - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
3.开始训练
一次取256条数据,将全部数据迭代训练20次
#训练
training_epochs = 20 # 20 Epoch 训练
batch_size = 256
display_step = 4
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples/batch_size)
# 启动循环开始训练
for epoch in range(training_epochs):
# 遍历全部数据集
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_xs})
# 显示训练中的详细信息
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("完成!")
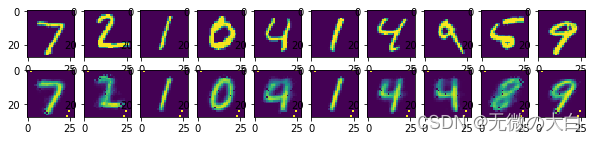
4.对比输入和输出
# 可视化结果
show_num = 10
encode_decode = sess.run(
y_pred, feed_dict={x: mnist.test.images[:show_num]})
# 将样本对应的自编码重建图像一并输出比较
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(show_num):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
执行上面的代码,生成如下的图片
5.显示数据的二维特征
将数据压缩后的二维特征显示出来
aa = [np.argmax(l) for l in mnist.test.labels]#将onehot编码转成一般编码
encoder_result = sess.run(encoder_op, feed_dict={x: mnist.test.images})
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=aa)#mnist.test.labels)
plt.colorbar()
plt.show()
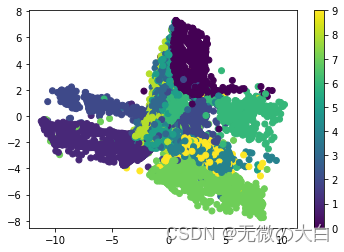
一般来讲用自编码网络将数据降维之后的数据更有利于分类处理
aa = [np.argmax(l) for l in mnist.test.labels]#将onehot编码转成一般编码
也可以不这样写:
mnist = input_data.read_data_sets(“/data/”, one_hot=False)
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









