






引言
主成分分析(PCA)是一种线性降维技术(算法),可将一组相关变量(p)转换为较小的k(k<p)个不相关变量,称为主成分,同时保持变量的最大可变性。
主成分分析的一个用例是它可以用于图像压缩分析-- 这种技术可以最小化图像的字节大小,同时尽可能保持图像的质量。在这篇文章中,我们将通过使用 MNIST 手写数字的数据集来讨论这种技术。
让我们开始吧!
加载数据集
MNIST 数据集包含手写数字的图像数据。因为它是 CSV 文件格式,所以让我们使用 Pandas 的 read_CSV()函数来加载它。
import pandas as pd
mnist = pd.read_csv('mnist.csv')
mnist.head()

每一行包含一个图像的像素值。构成图像的像素可视为图像数据的尺寸(列/变量)。“ label”列包含数字(0-9)的值。我们的分析不需要这一栏,因为主成分分析是一个非监督式学习任务,不处理标签数据。所以,我们可以简单地删掉这一栏。
mnist.drop(columns='label', inplace=True)
mnist.head()

现在,数据集的维度是:
mnist.shape
#(60000, 784)
这个数据集包含60,000张28x28(784)像素的图像!
显示图像
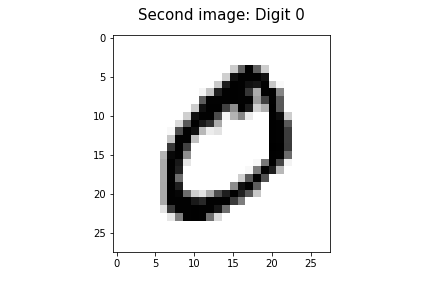
让我们显示 MNIST 数据集中的第二个图像(行)。此图像应包含数字“0”,因为第二行的标签列值为“0”。
import matplotlib.pyplot as plt
second_image = mnist.iloc[1].values.reshape([28,28])
plt.imshow(second_image, cmap='gray_r')
plt.title('Second image: Digit 0', fontsize=15, pad=15)
plt.savefig("Second image.png")
缩放
由于主成分分析对数据的尺度非常敏感,如果数据不是在相似尺度上测量的,那么在应用主成分分析之前必须进行特征尺度缩放。
在 MNIST 数据集中,每个图像的像素值范围从0到255(类似比例)。例如:
#2nd image
print(mnist.iloc[1].min())
print(mnist.iloc[1].max())
#0
#255
因为我们的数据是在一个相似的尺度上测量的,所以我们不需要为 PCA 做特征缩放。
应用 PCA
选择合适的尺寸
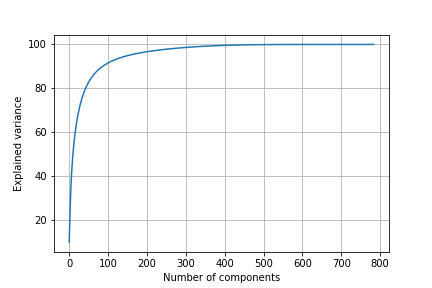
首先,我们需要选择正确的维度数(主成分数)。为此,我们将主成分分析应用于原始维度数(即784),并创建scree图,以查看主成分分析如何很好地捕获数据的方差。
import numpy as np
from sklearn.decomposition import PCA
pca_784 = PCA(n_components=784)
pca_784.fit(mnist)
plt.grid()
plt.plot(np.cumsum(pca_784.explained_variance_ratio_ * 100))
plt.xlabel('Number of components')
plt.ylabel('Explained variance')
plt.savefig('Scree plot.png')
让我们尝试使用前10个分量来压缩图像。这些分量不能捕获原始数据中的大部分可变性。所以,我们不会得到一个清晰的图像。
pca_10 = PCA(n_components=10)
mnist_pca_10_reduced = pca_10.fit_transform(mnist)
mnist_pca_10_recovered = pca_10.inverse_transform(mnist_pca_10_reduced)
image_pca_10 = mnist_pca_10_recovered[1,:].reshape([28,28])
plt.imshow(image_pca_10, cmap='gray_r')
plt.title('Compressed image with 10 components', fontsize=15, pad=15)
plt.savefig("image_pca_10.png")
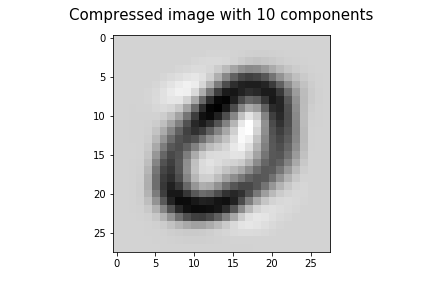
将此与我们之前获得的原始图像进行比较。该图像不是很清晰,并且缺少信息。
让我们尝试使用前184个分量来压缩图像。前184个分量捕获了原始数据中约96%的可变性。因此,这次,我们将获得非常清晰的图像,与原始图像非常相似。
pca_184 = PCA(n_components=184)
mnist_pca_184_reduced = pca_184.fit_transform(mnist)
mnist_pca_184_recovered = pca_184.inverse_transform(mnist_pca_184_reduced)
image_pca_184 = mnist_pca_184_recovered[1,:].reshape([28,28])
plt.imshow(image_pca_184, cmap='gray_r')
plt.title('Compressed image with 184 components', fontsize=15, pad=15)
plt.savefig("image_pca_184.png")
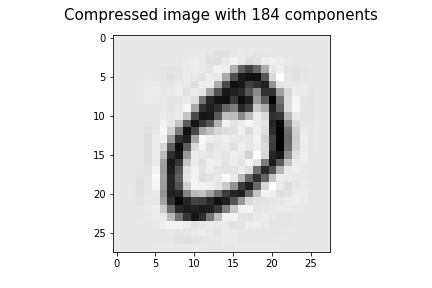
我们还可以计算184个分量的解释方差:
np.cumsum(pca_184.explained_variance_ratio_ * 100)[-1]
#96.11980535398752
是96.1% 。
将压缩图像与原始图像进行比较:
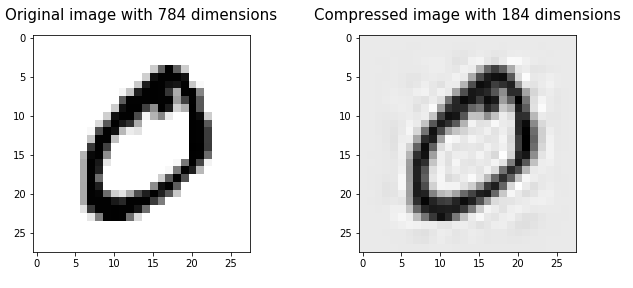
这就是我们如何使用 PCA 的图像压缩。左边的图像是784维的原始图像。右边的图像是184维的压缩图像。将 PCA 应用于图像数据后,维数降低了600维,同时保持了原始图像数据变异性的96% 左右!通过比较这两个图像,你可以看到有一个轻微的图像质量损失,但内容的压缩图像仍然是可见的!
总结
我们讨论了如何使用PCA进行图像压缩。当维度或分量的数量增加时,图像质量损失会降低。我们应始终尝试保持最佳数量的分量,以平衡解释的可变性和图像质量。pca对象的inverse_transform() 方法用于将缩小的数据集解压缩回784维。
· END ·
HAPPY LIFE
















 2890
2890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









