







1.推荐计算 — UserCF & ItemCF
源代码地址:
Movielens_Recommend
1.1 基于用户的协同过滤(UserCF)
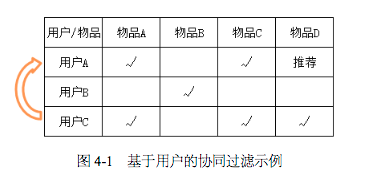
中心思想:基于用户对物品的偏好找到相邻用户,然后将相邻用户喜欢的物品推荐给当前用户
- 1.1 计算向量: 将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度
- 1.2 根据相似度找到K个相邻用户之后,根据相邻用户的相似度权重以及他们对物品的偏好,预测当前用户喜欢的物品,计算得到一个排序的物品列表进行推荐
通过计算用户的相似度和多用户对目标物品的得分,进而计算不同用户对目标物品的推荐得分,对不同用户的推荐得分排序进行推荐
1.2 基于物品的协同过滤(ItemCF)
中心思想:基于物品被用户喜欢的频率找到相邻物品,然后将相似度高的物品推荐给当前用户
- 1.1 计算向量: 将所有用户对一个物品的偏好作为一个向量来计算用户之间的相似度
- 1.2 根据相似度找到K个相邻物品之后,着眼于当前用户没有标注的物品,计算得到一个排序的物品列表进行推荐
通过计算物品的相似度和当前用户对多物品物品的得分,进而计算当前用户对不同物品的推荐得分,对不同物品的推荐得分排序进行推荐

2.相似度计算
在介绍详细的推荐算法之前我们对推荐算法中常用的相似度计算进行了解
2.1 同现相似度
其实就是计算同时喜欢A物品和B物品的用户数占喜欢A物品的用户数的比率:
w A , B = ∣ N ( A ) ∩ N ( B ) ∣ / ∣ N ( A ) ∣ w_{A,B} = |N(A) \cap N(B)|\;\; /\;\;|N(A)| wA,B=∣N(A)∩N(B)∣/∣N(A)∣
- N(A)是喜欢A物品的用户数, N(B)是喜欢B物品的用户数
但是如果B是热门物品,那么同时喜欢B物品的用户会很多,那么 w A , B w_{A,B} wA,B会接近于1;那么任何物品与热门物品的相似度都很高,这样推荐便没有什么意义,所以我们这样计算同现相似度:
w A , B = ∣ N ( A ) ∩ N ( B ) ∣ / ∣ N ( A ) ∣ ∣ N ( B ) ∣ w_{A,B} = |N(A) \cap N(B)| \;\;/\;\; \sqrt{|N(A)||N(B)|} wA,B=∣N(A)∩N(B)∣/∣N(A)∣∣N(B)∣
2.2 欧几里得距离
欧几里得距离是比较常用的衡量多维空间距离的公式,当然可以认为是两个坐标点直接的绝对距离:

d ( x ) = ∑ ( x i − y i ) 2 d(x) = \sqrt{\sum(x_i - y_i)^2} d(x)=∑(xi−yi)2
那么我们可以认为距离越短,这两个目标点就越相似,即相似度越大,所以欧几里得相似度可以这样定义:
s i m ( x , y ) = c o u n t / 1 + d ( x ) sim(x,y) = count\;\;/\;\;1+d(x) sim(x,y)=count/1+d(x)
2.3 Cosine相似度—— 余弦相似度
这个相似度其实是通过两个向量的夹角来反应数据的相似性

c ( x , y ) = X Y / ∣ ∣ X ∣ ∣ ∣ ∣ Y ∣ ∣ = ∑ x i y i / ∑ x i 2 ∑ y i 2 c(x,y) = XY\;\;/\;\;||X||||Y|| = \sum x_iy_i \;\; /\;\;\sqrt{\sum x_i^2} \sqrt{\sum y_i^2} c(x,y)=XY/∣∣X∣∣∣∣Y∣∣=∑xiyi/∑xi2∑yi2
2.4 皮尔逊相关系数
皮尔逊稀疏一般用于计算两个定距变量间联系的紧密程度,他的取值范围是[-1,1]:
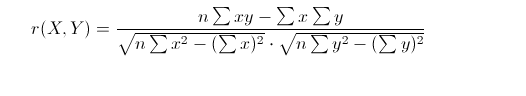
3.协同过滤算法实现(ItemCF实现)
3.1 数据源:
下载Movielens 1M数据集ml-1m.zip
目录中有: movies.dat ratings.dat users.dat
3.2 同现相似度计算

- 对数据进行 物品-物品 的同现频次的分组处理,然后利用同现相似度公式 w A , B = ∣ N ( A ) ∩ N ( B ) ∣ / ∣ N ( A ) ∣ ∣ N ( B ) ∣ w_{A,B} = |N(A) \cap N(B)| \;\;/\;\; \sqrt{|N(A)||N(B)|} wA,B=∣N(A)∩N(B)∣/∣N(A)∣∣N(B)∣计算同现相似度,得到物品相似矩阵,如上图所示
3.3 欧几里得相似度 & 余弦(Cosine)相似度

-
欧几里得相似度:同理对数据进行 物品-物品 的同现频次的分组处理,同时通过每组两个物品的得分,根据 s i m ( x , y ) = c o u n t / 1 + d ( x ) sim(x,y) = count\;\;/\;\;1+d(x) sim(x,y)=count/1+d(x)计算两个物品之间的欧几里得相似度矩阵,如上图所示
-
Cosine相似度:同理对数据进行 物品-物品 的分组处理,计算每组物品的 x y xy xy, ∣ x ∣ 2 |x|^2 ∣x∣2, ∣ y ∣ 2 |y|^2 ∣y∣2并依次累加,然后根据 c ( x , y ) = ∑ x i y i / ∑ x i 2 ∑ y i 2 c(x,y) = \sum x_iy_i \;\; /\;\;\sqrt{\sum x_i^2} \sqrt{\sum y_i^2} c(x,y)=∑xiyi/∑xi2∑yi2计算得到两个物品的余弦相似度矩阵个,如上图所示( x , y x,y x,y是每个物品对的得分)
3.4推荐
相似度计算出来之后,根据物品相似度模型,用户评分和指定最大推荐数量进行用户推荐,如下所示:


上面两个图比较明了的解释了推荐的计算过程:
- eg: 用户2对物品1的评分是1,而物品1和物品2的相似度是0.67,则对用户2推荐物品2的得分:
s c o r e = 评 分 ∗ 相 似 度 = 1 ∗ 0.67 = 0.67 score = 评分 * 相似度 = 1 * 0.67 = 0.67 score=评分∗相似度=1∗0.67=0.67
- eg: 用户2对物品1的评分是1,而物品1和物品2的相似度是0.67;用户2对物品3的评分是2,而物品3和物品2的相似度是0.33,则对用户2推荐物品2的得分:
s c o r e = 评 分 ∗ 相 似 度 = 1 ∗ 0.67 + 2 ∗ 0.33 = 1.33 score = 评分 * 相似度 = 1 * 0.67 + 2 * 0.33 = 1.33 score=评分∗相似度=1∗0.67+2∗0.33=1.33
也就是说推荐结果就是:
当前用户对不同用户评分乘以不同用户与同一物品相似度的叠加之和就是当前用户对该物品的推荐分数
s
c
o
r
e
目
标
物
品
=
∑
对
i
物
品
的
评
分
∗
i
物
品
与
目
标
物
品
相
似
度
score_{目标物品} = \sum 对i物品的评分 * i物品与目标物品相似度
score目标物品=∑对i物品的评分∗i物品与目标物品相似度
以下链接是源码代地址,感谢阅读;
Movielens_Recommend















 3409
3409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









