







首先介绍下强权外交游戏,6位玩家扮演1914年一战时的欧洲列强国家,每一回合之前有一段谈判时间,各国利用此时与其他国家沟通、合作或结盟。谈判之后玩者们要写下自己要如何调动部队(分为海军和陆军)。大家都书写完毕后再一起亮出纸条、一起移动。你必须与其他利益相同的强权合纵联横,对抗其他有利害冲突的国家。欺骗、背叛与出卖在本游戏中都是被许可的,最后占领欧洲一半面积的玩家获胜。
在网络版本的强权外交中,由于玩家之间可以私下聊天,这个博弈可以理解为结合语言沟通的多人非完美信息博弈游戏,类似德州扑克。这种结合强化学习训练大语言模型的方式非常适用于一些特定任务,例如销售,竞价等。在强权外交中2022 年 8 月 19 日- 10 月 13 日,从Cicero开始投入使用,在其进行的40多场游戏里,成绩可以在所有玩家高居前10%。并且在所有 40 场比赛中,Cicero的平均得分为 25.8%,82 名对手平均得分为12.4%。
国内中文环境对这个关注比较少,光芒大部分被chatgpt掩盖了,由于本人的工作之前和德州扑克相关,研发德州ai libratus战胜职业玩家的noam brown 最近也转投了openai,貌似现在利用rl训练大语言模型也是比较前沿的方向。在这里简单的对论文和代码做一些解析
论文参考这篇
Human-level play in the game of Diplomacy by combining language models with strategic reasoning
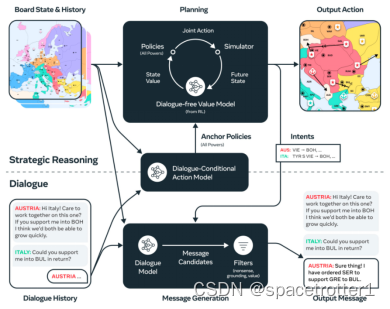
重点关注Dialogue-Conditional model ,这个模型是通过大量人类数据模仿学习得来,输入对话和历史状态,输出Anchor Policies ,类似与德州扑克ai中的蓝图策略,可能不是很强但是可以作为更强的参考,强化学习经常使用这种策略来提升效果。
Dialogue-free Value model 这个是借鉴Dialogue-Conditional model 的人类策略通过强化学习找到更强的策略。这是网络的基本架构
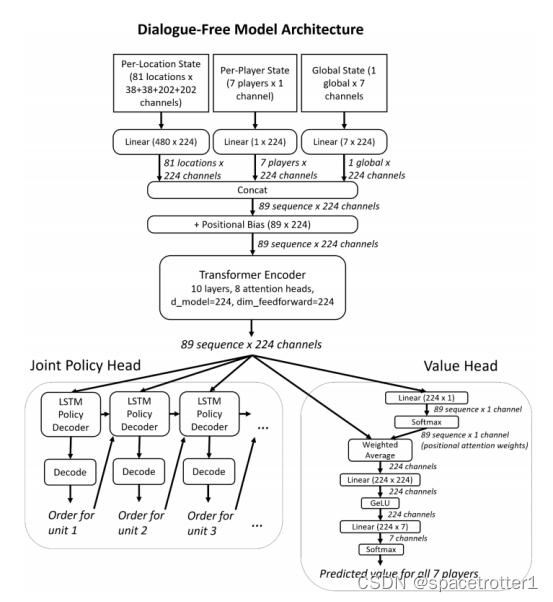
Joint Policy Head输出当前每个单位的策略,Value Head 显示当前状态价值函数。
网络的训练是通过Rl实现的,具体使用一个叫PIKL的算法实现。
PIKL算法参考这篇论文
Modeling Strong and Human-Like Gameplay with KL-Regularized Search
他的核心是首先通过模仿学习计算一个策略,后续通过rl学习的时候,对和模仿学习策略偏差过大的时候给一个惩罚,这样出来的策略回更像人类的策略,论文还说明了这个既可以用于完美信息博弈的MCTS也可以用于非完美信息博弈。
![]()
下面我们看代码
https://github.com/facebookresearch/diplomacy_cicero/
Conf 目录为配合heyhi使用的脚本配置文件,prototxt文件为

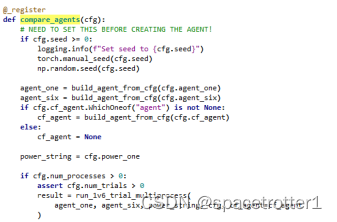
传入这个参数就可以直接调用run.py中的compare_agents函数
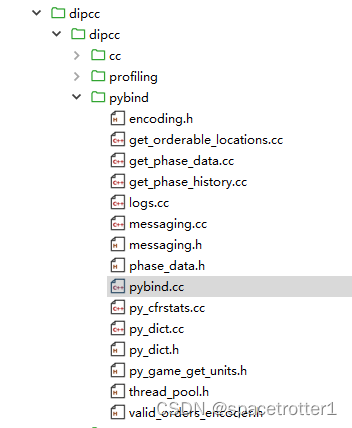
Dipcc为一个使用c++实现的强权外交游戏,强化学习需要模拟非常多的游戏次数,所以底层需要c++实现,通过pybind.cc定义接口来和python交互,由于是非完美信息博弈,还提供了cfr函数的一些实现。
Parlai_diplomacy目录使用了ParlAI框架,他类似于OpenAI的Gym或者DeepMind的Lab。
Slurm目录是Slurm集群管理的配置目录。
主要的内容在fairdiplomacy目录中
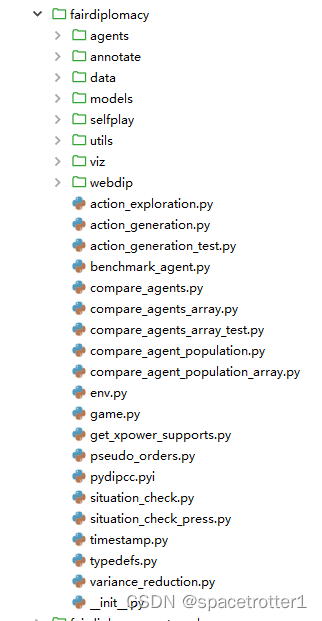
agents目录主要看base_search_agent.py 和searchbpt_agent.py目录,他们分别为模仿学习的基础agent和rl训练后的searchBot_agent.
重点关注exploit函数,这是核心训练rl的函数。
总结,整体工程看下来对GPU的需求不小,需要256个GPU训练,对代码速度的需求很高,但是这么来看,对比从文本中学习,利用强化学习的方式更符合我们人类学习的方式对特定任务的识别也会更精准,自从Noam Brown大神加入了openai后twitter也宣布在数学上达到了78%的准确率,应该是利用了类似强化学习的学习方式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









