










最近发现在大火的llm之外ai博弈也有了很多的进展,Noam 做完Pluribus 后又利用博弈强化学习结合llm技术研发了Cicero,在强权外交这样的聊天桌游中学会插科打诨合纵连横取得前10%的成绩,并且对手完全没意识到是在和Ai对战。最近这个大神也跳槽去了OPENAI,估计是研发Q* ,相信强化学习结合博弈论和大语言模型等算法会在游戏,自动驾驶,机器人规划等方向上落地更多的方向,在这我也就结合德州这个环境分享下Pluribus的原理,技术难点等。
应该会写七八章,里面会用一些德州扑克的概念来辅助理解纳什均衡(我除了让Ai打自己从来不打),也会列一些虚拟遗憾值算法的论文,代码实现。
1如何理解纳什均衡
说起纳什均衡大家先想到的肯定是囚徒困境,囚徒困境的均衡解为两人都坦白,第一次看自然会把纳什均衡和厚黑学和联系在一起,这里咱们换个角度从德州诈唬比例和数学的角度帮助大家解释纳什均衡,他的定义是任何一位玩家在此策略组合下单方面改变自己的策略(其他玩家策略不变)都不会提高自身的收益,不要神话纳什均衡,他不能帮你求得整体利益最大化,也不能帮你求得个人利益最大化,但是可以在不清楚对方具体策略时提供一个不吃亏的策略,通过对比对手的策略和对手的纳什均衡的偏移可以协助判断对手的行为习惯,从而制定剥削策略帮助我们求得整体利益最大化。
这里我举一个德州扑克中的示例,来介绍纳什均衡是如何落地德州扑克这个场景中:
假设德州扑克进行到河牌阶段,公牌为四张2带一张红桃三,当前底池为2,先行动的玩家50%拿到AA 50%拿到QQ,先行动玩家可以在check(过牌) 和bet(下注)1中做出选择,当先行动的玩家check(过牌)时,后行动的玩家可以在check(过牌) 和bet 1(过牌)中进行选择,当先行动的玩家bet 1时,对手可以在fold(弃牌)和跟注(进行选择)我们就有了下面的博弈树
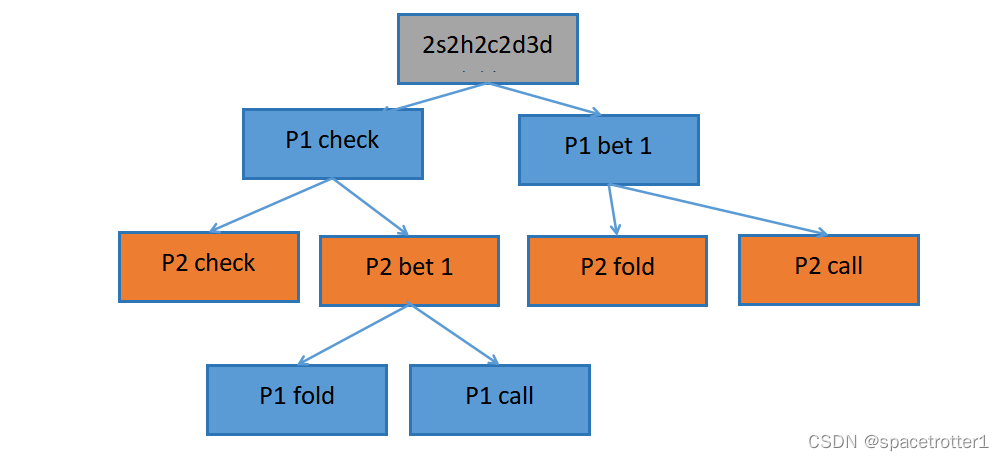
我们根据纳什均衡求解器求出的结果为
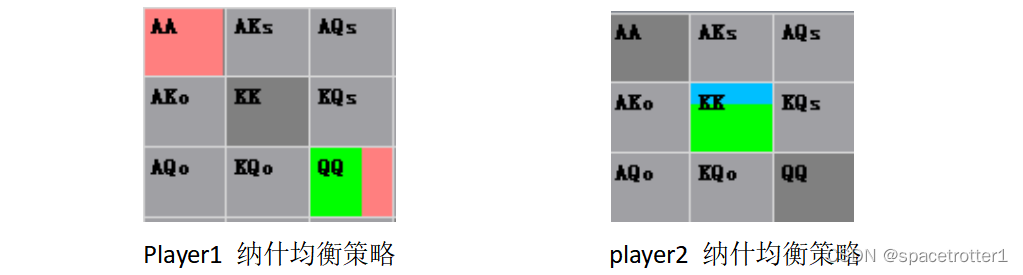
对于玩家1,如果拿到AA 100%下注1,如果拿到QQ 66% check 33% 下注1
对于玩家2, KK 遇到下注则66%跟注33%弃牌。
这里使用了bupticybee开源的solver,这大神的代码我们膜拜学习过,给了很多思路。https://github.com/bupticybee/TexasHoldemSolverJava
根据纳什均衡的定义,博弈双方单方面改变策略都不会增加收益。
首先讨论player1的行动,纳什均衡策略的数学期望为:
0.5*0.66*2(AA下注1对手CALL赢2)+0.5*0.33(AA下注1对手弃牌赢1)+0.5*0.33*0.66*-2(QQ下注1对手call输2)+0.5*0.33*0.33*1(QQ下注1对手fold赢1)+0.5*0.66*-1(QQcheck对手下注弃牌输1)= 0.33
如果玩家2面对纳什均衡策略调整为50%跟注50%弃牌则玩家1的下注数学期望为0.66
如果玩家2面对纳什均衡策略调整为100%跟注则玩家1下注的数学期望为0.33
玩家2面对玩家1的策略,如何修改策略都无法降低玩家1的数学期望,由于是零和博弈也无法增加玩家2自己的数学期望,其实还要算玩家1 check这条线的,这里简化先省略。
玩家1如果修改策略为,拿到AA 100%下注1拿到QQ就check,那么玩家2可以修改策略为面对下注100%弃牌那玩家1下注的收益为0,这在德州扑克中叫诈唬不足。
玩家1如果拿到AA 100%下注1拿到QQ也100%下注1,那么对方通过100%跟注,降低我们的数学期望为0,这在德州扑克中叫过度诈唬。
如果玩家1偏离纳什均衡策略,那么玩家2可以通过调整策略降低玩家1的数学期望。
有些聪明的朋友说了,使用纳什均衡策略是防守策略无法获取收益,实际在使用中对手会有很多不经意的自剥削情况,例如下注50%下注50%check的数学期望为2,而对手选择了30%check 70%下注 数学期望为1 ,自己剥削了自己。
真实的德州扑克的节点数有10的180次方,实际比赛需要30秒之内做出决策,所以就衍生出了各种花式cfr 和 海量的工程优化trick,后面我再慢慢介绍。
下一章介绍以下cfr虚拟遗憾值相关算法。

















 1937
1937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









