






为什么不能用solver比赛
有很多朋友对我说,有了solver直接求解纳什均衡策略接入游戏就可以印钞啦,我只想说太天真了,首先德州扑克有四条街,solver使用的cfr算法需要建全树只能求解后面三条,并且只支持一对一,solver使用的cfr求解一个翻牌圈20分钟起步,我们实际使用不能超过30秒。所以一对一才有了libratus和deepstack还有rebel,一对多有了Pluribus。这一章我们主要介绍libratus和deepstack还有rebel这三个算法,Pluribus的算法后期专门介绍。
libratus和deepStack是第一批战胜顶尖人类的ai.
Libratus
先介绍libratus,他挑战顶尖选手游戏12万手牌,以14bb/h的巨大优势碾压获胜。(一般认为5bb/h已经意味着技高一筹)
Libratus的论文参考这两篇,具体没有实现过只谈自己的理解
Superhuman AI for heads-up no-limit poker: Libratus beats top professionals
Safe and Nested Subgame Solving for Imperfect-Information Games
libratus 在前两条街使用mccfr训练出的蓝图策略,后两条街使用subgame solving 策略,由于后两条街深度不大,他并没有使用深度有限,而是使用了一种叫reach Subgame Solving的算法。
论文首先介绍了一个Coin Toss游戏
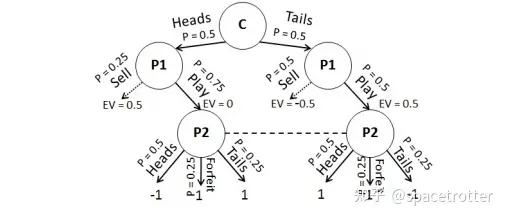
上面是游戏的决策树,P1可能投出硬币正面或反面,P1可以选择卖和不买,如果P1不卖则P2有多种选择,
假设我们用mccfr计算出了一个和上图所示概率一样的粗略的蓝图策略。现在轮到P2行动。
如果我们使用unsafe进行求解,我们会假设对手使用蓝图策略,并且根据贝叶斯公式计算出P1是正面还是反面的概率,避免有的朋友不清楚,下面类比狗叫的例子。

P(A)理解为p1选择不卖的概率也就是狗叫, P(B)理解为p1是正面的概率,我们还知道玩家的蓝图策略P(B|A)那么就可以根据对手不卖的动作和我们假设的蓝图策略推导出P1是正面或反面的概率也就是p(B|A)。然后按这个概率投硬币求解。
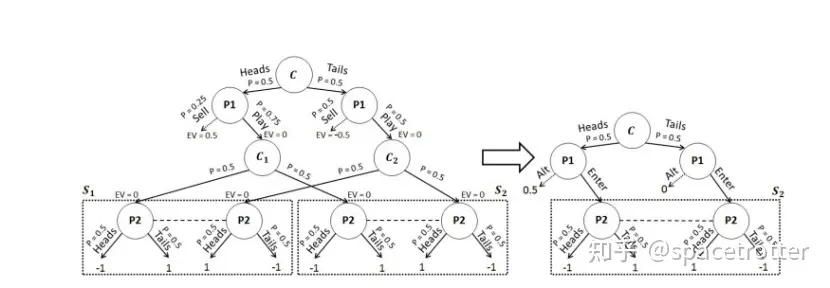
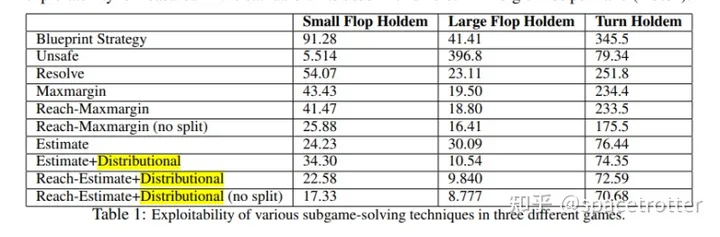
但是unsafe方式有一个严重的问题,对手可能不会根据蓝图策略行动,所以safe的方式求解更安全,但是实际应用中,safe需要从游戏根节点建树求解会很慢。论文提出了一种叫reach subgame solving的解决办法,在P2节点上新加入一个对手节点,并且给他一个退出机制,如果能很好的计算这个退出机制的ev,就可以保证P2实时搜索求解出的策略的可利用度小于默认的蓝图策略。下图是蓝图 ,unsafe ,reach 算法还有一些其他算法的可利用度。
论文还使用了Estimate和 Estimate+Distributional算法来降低可利用度。
Deepstack 和rebel
Deepstack 和rebel 放在一起介绍,好分析他们的不同。
DeepStack: Expert-Level Artificial Intelligence in Heads-Up No-Limit Poker deepstack论文
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games
两篇论文都是用mlp协助做深度有限搜索,什么叫深度有限搜索,真实应用中博弈树很大,只要我们可以准确的返回叶子节点的反事实值,我们就可以在限定前决策点固定深度内就可以更快的solving问题,下图红色部分就是深度内,一个Neural net 来确定叶子节点的反事实值。
下图红色部分事求解的区域,
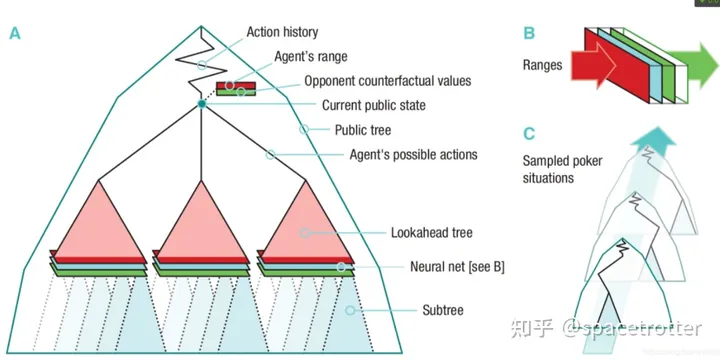
网络的结构如下,我们输入双方的range,和公牌筹码等情况,返回不同牌的cfr值。
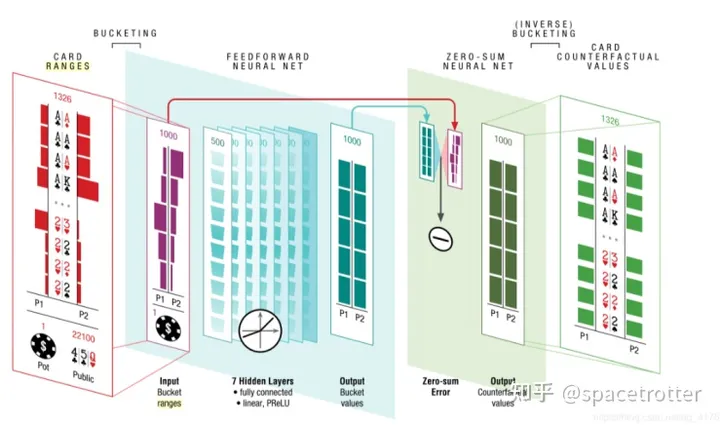
具体流程如下,re-solve就是我们的子游戏求解函数。他需要传入player的范围和对手的反事实值,然后利用VALUES函数设定叶子节点的cfv值,利用UPDATE SUBTREE STRATEGIES用类似cfr的算法更新策略,看代码是p1 regret 和p2regret是分开计算的,而且p2的range是动态变化,这个可能是cfr的变种。

deepstack使用的神经网络是通过随机模拟双方玩家的range 然后通过cfr训练的,这里可能存在问题。
rebel算法
参考下面论文
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games
知道你们喜欢代码哈哈,可惜是liar dice不是德州扑克的
https://github.com/facebookresearch/rebel

Noam后来提出了rebel,利用和alphazero类似的方式更好的解决了这个问题。大家可以对比deepstack算法,主要多了SAMPLE LEAF这个函数。在deep stack时我们介绍了,他的网络是随机生成range 训练的,rebel的区别主要是修改了规则游戏中玩家并不知道自己具体是什么牌,而是返回所有牌的策略,这样将非完美信息博弈转化为完美信息博弈,然后就可以使用类似alphazero的方式,抽样有价值的子节点进行搜索。

主要讨论下论文中最难看懂的这块谈下个人理解,v(s) 是信息集的价值,B是v(pbs)的价值,个人理解哈,pbs是包含了双方的范围的,p1可能有什么牌p2可能有什么牌。而信息集可 以简化为,当我是p1拿着AA这种情况面对对手的范围。pbs是自己拿所有牌的情况,s是信息集合是自己拿固定一套牌,因为我们的value net,是用cfr训练出的,cfr使用的是信息集,而我们用类似alphazero搜索时需要pbs的梯度,论文这里说他们是可以相互转化。
最后说一句没事不要玩这个方案,训练德州扑克使用了128台 8gpu的机器生成数据, 一台机器训练。
下一章介绍聚类

















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









