







1 SVN
1.1 SCM常见模式与反模式
一句话总结:不要提交能根据现有文件自动生成的文件。
表3‑1 常见的SVN模式与反模式
| 不提交能基于代码库自动生成的文件 减少svn库大小,提高checkout时间,加速CI的时间,因此也减少了发现bug的时间 | 典型的分成如下几类: 1. 与开发工具相关的文件,例如eclipse的.setting文件、.classpath文件、.project文件、自定义class Variable 2. 不会被他们共享的文件,例如不会重复执行的test data相关的resources文件; 3. 历史SCM工具残留文件,例如cvs的残留 .vssc,vssver2.scc文件 |
| 提交时必须写日志,日志必须有意义 log的作用: 1. 能发现当初你提交这个版本时的意图的log; 2. 在你需要找到任何一个历史版本的时候,方便你搜索,所以log要类似于关键词的作用,要有区分性
| 典型的log pattern: 1. 修改bugxx,增加了空指针判断; 2. 增加了xx功能,避免xx问题; 3. 增加了xx类的单元测试,测试了xx接口; 4. 提交了测试的resoures文件,避免单元测试重复执行时报错。 5. 修改了xx文件错误的配置。
典型的log的anti-pattern: 1. 修改了xxx文件,modified by xxx(svn的log状态就能发现是谁提交时删除还是更新了xx文件) 2. 长期使用last log(日志相同) 3. 在data(其实在maven下应该是test/resources)提交了大量的PDF、word等作为测试文件,但是单元测试代码中仅仅使用到了很少的部分 4. 把SVN当成软件共享服务器,将大文件,如IDE工具、XXX服务器软件、XXX工具软件都作为配置管理项目都提交到svn上。 5. 提交了能通过word文档自动生成的帮助文件脚本 6. 未提交数据库的初始化脚本。 |
| 长时间不更新 或者 琐碎的提交 | 正常的更新节奏:
琐碎的提交: 1. 思路不清楚时,将svn当成“垃圾回收站”,任何一次细小的修改都要提交到svn上,因为“指不定什么时候我又会需要它” |
1.2 不仅仅是SVN,而是整个SCM
需要解决如下问题;
1) 如何保证多条产品线同时开发,并且多条产品线之间还有组件的依赖关系?
2) 如何保证产品在开发新特性的时候,不影响产品的稳定性?不影响其他依赖该产品组件的其他产品的开发?
3) 如何响应不可预知时间的客户发布版本的请求?
4) 内部的测试版本应该如何发布?
5) 对外发布版本应该是谁来做?与对内发布版本流程应该一样吗?
6) 一个产品的发布与几个产品一起打包发布流程应该是一样的吗?一个产品单独发布与几个产品一起打包发布有什么不同?license是逐个产品控制还是每个安装包只做一次?
7) 产品的license控制,是发布时做还是编译时做?
“可重现性”(reproducibility)为什么是如此重要?我们需要哪些方面的可重现性?
1) 测试人员发现了一个bug,开发人员确认该bug的确存在。涉及到2个问题:
1) 测试人员是在什么环境下测试的?
2) 包括产品的安装版本、安装的操作系统的环境、出现该bug的页面操作流程、具体的bug表现的现象。
2) 系统上线后,在客户现场出现了问题,客户让派人去现场定位问题:
现场人员需要定位问题,这涉及到如何在运行时进行故障诊断的问题,或者更严重点,系统挂掉了之后,“尸体”是否保存完整的问题——当时出异常的位置和完整的调用堆栈,甚至包括当时的调用的参数等环境信息是否能完整地保存到log日志当中。
1.3 分支模型(策略)
几种常见的分支模型:稳定trunk模型(MainLine Model)、基于trunk开发模型(Trunk Based Development)、短生命周期分支(Short LivedFeature Branches Model)、级联模型(cascade)等。
1.3.1 MainLine Model
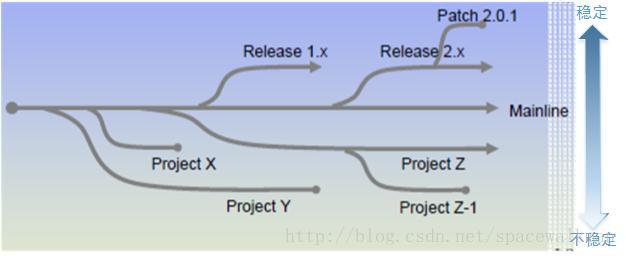
图3‑1 主干模型
推荐选用,具有如下特点:
1) 保持主干稳定,主干的代码经过严格测试,随时可以对外发布;
2) 经过主干打出的分支,分成2种类型:
a) Release分支,代码也经过严格测试,代码稳定,基于该分支已经向最终客户发布产品了,客户已经在使用了,但是也可能存在小bug。
b) ProjectX分支:为了验证某种特性,实现某个功能或者为了某个具体项目而打的分支,代码不稳定,甚至没有经过单元测试,作为merge到主干前,开发人员代码的临时存储地。
3) 分支的“可靠程度”,从上到下依次递减。
FAQ:
1) 何时打project类型的branch?
先回答这个问题——预计在这个分支上做的修改,是否要持续数周,并且会在完成时一次性全部提交到SVN上吗?如果是,那么就应该打分支。
2) 何时打release类型的分支?
内部计划的产品发布,向测试组发布测试版本;客户临时的茶品发布请求,后者需要评估是否原来的发布的产品能满足客户的要求(是否遗留有严重的bug,客户正好要使用;是否有新功能,该版本并没有包含),如果能,尽量不重新发布新版本。
3) 为什么要分支与主干同步
分支的代码最终是要merge回主干的,分支和主干是并行演化的,长时间不保持与主干同步,待到分支完成时一次性merge回主干,merge时冲突多,甚至是不可能完成的任务。
4) 如何保持分支与主干的同步?
表3‑2 保持分支与主干同步的原则

总之保持如下原则:
1) 经常merge比你当前工作分支更稳定的分支的代码;
2) 永远不要merge比你当前工作分支不稳定的分支的代码;
分解成如下几种情况:
1) 从Release->MainLine,要经常进行;
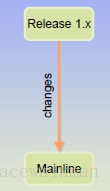
图3‑2 Rlease到MainLine的merge要经常进行
2) 从MainLine向Release1.x,禁止;
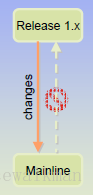
图3‑3 MainLine到Rlease的merge要禁止
3) 从Release1.x向project类型的分支,要经常进行,并且要逐级进行,不能越级;
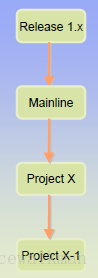
图3‑4 Rlease到Project的merge要经常进行,并且逐级完成
4) 从project向MainLine,仅在特定的时间点进行,就是“功能完成”的时刻。需要特别注意“完成”标准的定义,必须非常严格,其他时间不允许。
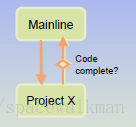
图3‑5 Project到MainLine的merge仅限于在“完成”时进行
1.3.2 Trunk Based Development Model
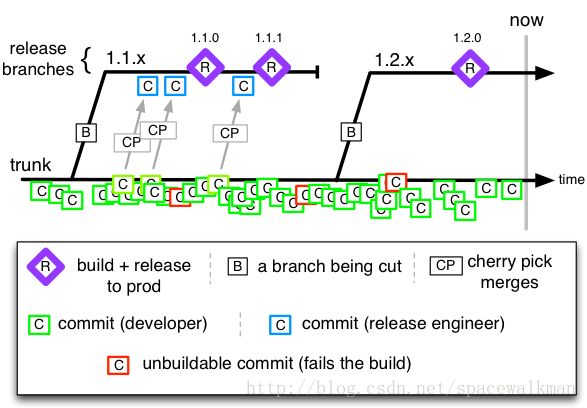
图3‑6 Trunk-Based开发模式
关键问题在于:主干很难达到release的标准。很可能为了release需要暂停新功能开发。
1.3.3 Short-lived Feature Branch

图3‑7 Short-lived Feature Branch
可以与MainLine模型配合,project类型的分支与Short-lived分支有共同点,关键在分支生命周期长短的定义。
但是随着CI的出现,这种模型越来越不被推荐使用。CI的理念是既然代码是所有人都基于一个分支工作,将保持该分支稳定的工作交给CI。
1.3.4 Cascade Model
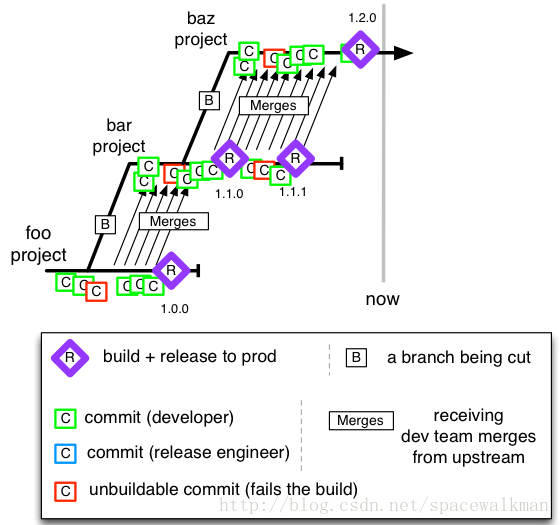
图3‑8 Cascade Model
复杂程度较高,有大量的分支之间merge的操作,日常维护工作量较大。一般很少使用。
1.4 SVN服务器细粒度权限控制
当与maven配合时,svn可以进行逐个目录的权限控制,实现模块化并行开发,并且最大限度的进行源代码隔离,例如前台开发不需要看到后台代码,或者由于对知识产权保护,核心代码不对外包人员公开等。以下是一个例子实现trunk下的目录waibao(外包人员) &qiantai(前台开发人员)只能看到docs目录和projectA_web目录,配置要点如下:
1) 在根目录(或者trunk目录)配置2人只读;
2) 在不允许其访问的子目录中,使用*= 让其不能访问(但是需要注意会阻断路径权限继承,需要对一些特殊的用户或者用户组,单独添加进来,例如@admin用户组);
3) 在允许其访问的子目录中,使用waibao= rw &qiantai= rw允许其读写。
[projectA:/trunk]
@admin = rw
#此处省略了其他人员配置
qiantai= r
[projectA:/trunk/projectA_model]
@admin = rw
#此处省略了其他人员配置
*=
[projectA:/trunk/projectA_service]
@admin = rw
#此处省略了其他人员配置
[projectA:/trunk/projectA_web]
#此处省略了其他人员配置
qiantai= rw
[projectA:/trunk/docs]
#此处省略了其他人员配置
qiantai= rw
1.5 FAQ
1) 如何设置必须提交日志?
日志、作者、文件和路径都是可以作为检索条件的,典型的log用途:
a) 作为日后后悔时的索引,方便在多次提交的记录中快速定位某次提交;
b) 可以记录设计思想和项目架构演化的痕迹;
2) 常见的忽略都有哪些?
常见的忽略有:
build.propertiestarget dist *.log *.project *.classpath *.checkstyle
bin .cloverjunit*.properties .settings .fbprefs .pmd lib
.externalToolBuildersmaven-eclipse.xml *.iml .idea
3) 如何设置递归忽略?
2种递归设置svn忽略的方式:
svn propsetsvn:global-ignores '*.o' .
svn propsetsvn:ignore '*.o' . --recursive
4) 如何进行代码冻结(freeze)?
使用svnadmin freeze PATH
5) 如何移动代码?
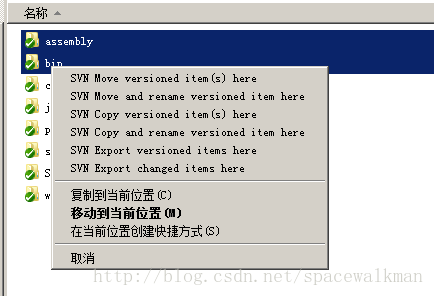
图3‑10 使用TortoiseSVN移动已经versioned的文件夹
右键按住需要被移动的source文件夹,拖动到destination文件夹,然后释放右键,在弹出的菜单上选择第一项。
6) 为什么有些时候更新SVN的Working Copy的时候需要进行clean up?
因为一些原因,有时候会导致一个svn update失败,典型的造成WorkingCopy Locked的操作有:
a) 在update的过程中,手工cancel了update;
b) 在update的过程中,由于网速慢,更新失败;
c) 运行external的diff程序(非tortoiseSVN自带的diff程序)
7) eclipse kepler安装SVNConnector
参见 http://www.polarion.com/products/svn/subversive/download.php
2 UnitTest
2.1 为什么要有UnitTest
1) 开发人员证明自己的确做到了,也是在出现问题时,将自己的“责任摘干净”的有力工具;
2) 开发人员已然做过这个事情,为什么不作为代码库的一部分提交到SVN呢,让大家都知道你测试过,并且是怎么测试的;
3) 将单元测试看成你自己的“好伙伴”,它时时刻刻守护你的代码,无论是你有意的重构,还是代码被无意的修改,单元测试通过Fail来给你提示;
4) Learn by Unittest,既为自己,也为第三方开发人员(为什么API doc不行?因为API doc是以单个方法为粒度的,而为了完成一个用户视角的功能,往往需要多个方法进行过程式的调用,而这个如果没有进行用户友好的封装,往往需要调用者自己进行)。
2.2 遵循的原则
1) 没有Assert的测试不是单元测试;
2) 单元测试既要有面向内部开发人员的单个方法级别的测试,也需要面向第三方开发人员的业务功能级别的单元测试(有点“集成测试”的含义);
3) 单元测试要写到什么程度为止:方法的边界、正常、异常值都测试到为止,客观的评价指标:分支覆盖、条件覆盖、语句覆盖等,单元测试的覆盖率要达到一定的程度(在以往应用系统的开发中我们后台代码的单元测试覆盖率要达到75%以上),具体标准前台后台标准不一,产品和项目标准也不一样,团队要找到适合自己的阈值。
4) 单元测试要“就近测试”,单元测试代码与项目的主代码应该放到一起,并且一起作为产品代码提交到SCM管理;
5) 单元测试代码和相关的数据库、测试资源文件都必须提交到svn,保证其能重复、自动执行。并且一个单元测试不会给其他单元测试(包括其自身)带来任何后续的影响(如一个单元测试执行完成之后,忘了清理数据库,在数据库中遗留了一条记录,下次另一个单元测试又会假定该记录在该表是空的,最典型的是getById(int));
6) UnitTest中涉及到路径的地方使用相对路径,而不是绝对路径。
7) 针对算法的测试,需要根据算法理论,选取合适的数据集(保证提交到SVN或者保证在测试库中始终存在),验证手工推导的结论与算法实际执行结果是否一致,保证算法的每一步都严格按照预想的执行。不能只测试最后的准确度或者算法是否执行过,没有报错(这个甚至都不能叫“集成测试”)。
8) 功能性的单元测试和性能单元测试要分开(例如使用Junit的category分组),因为实际在CI时,这2种类型的测试最好是分开执行,保证功能性单元测试短时间内快速执行完毕,性能测试往往要长时间运行,几小时甚至几天。
9) 一些减少bug的“闲话”:
常见的null pointer异常与“防御式编程”。开发人员采用谨慎的态度,对函数输入参数,进行合法性检查,保证排除所有异常情况后才执行正常流程。对一切输入都持“怀疑”态度,特别是UI界面的输入和开放给第三方用户调用的API接口。
2.3 maven下单元测试的编码规范
1) “就近测试”,测试代码跟主代码都提交到一个工程下;
2) src/main/java文件夹下,package为com.xxxx.yyy下的ClassA的测试类的方法methodA,相应的测试类的package保持不变,位置放置到src/test/java下面,测试类的命令遵循“原类名+Test后缀命名法,命名为ClassATest,测试方法采用“test+原方法名”前缀命名法,命名为testMethodA。
参考文献
[1]. http://paulhammant.com/2013/12/04/what_is_your_branching_model/
[2]. 《代码大全》2nd
[4]. 《maven实战》
[5]. http://www.infoq.com/cn/articles/road-of-automated-unit-testing-practices














 2512
2512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









