







 本文探讨了如何利用Hadoop和Spark构建高效股票分析与推荐系统,通过大数据处理、机器学习和深度学习技术,提升金融市场的效率、准确性,降低投资风险,以及增强金融机构的竞争力。研究内容包括数据采集、系统设计、功能实现和金融科技创新的推动。
本文探讨了如何利用Hadoop和Spark构建高效股票分析与推荐系统,通过大数据处理、机器学习和深度学习技术,提升金融市场的效率、准确性,降低投资风险,以及增强金融机构的竞争力。研究内容包括数据采集、系统设计、功能实现和金融科技创新的推动。
| 论 文 题 目 | 基于hadoop+spark的股票分析与推荐系统的设计与实现 | ||||
| 姓名 | 学院 | 数学与大数据学院 | 专业 | ||
| 班级 | 学号 | 选题性质 | 应用研究 | ||
| 指导教师姓名 | 韦萍萍 | 职称 | 副教授 | 预计字数 | 填自己要写的论文总字数 |
| 选题的原由: 1)说明本选题的理论、实际意义 理论意义
实际意义
2)综述国内外有关本选题的研究动态和自己的见解 国内 中国科学技术大学的学者们利用Hadoop和Spark构建了一个股票数据分析与推荐系统。他们采用了基于时间序列的股票数据分析方法,通过分析历史股价数据,预测未来股票价格的波动趋势,并利用推荐算法为投资者提供个性化的股票投资建议[7]。该系统的性能得到了显著提升,可以处理大规模的股票数据,并且能够实时更新推荐结果。 国外 微软亚洲研究院的研究人员利用Hadoop和Spark构建了一个股票市场趋势预测系统。他们采用了基于机器学习的股票预测模型,通过对历史股价数据进行特征提取和模型训练,预测未来股票价格的波动趋势。同时,他们还利用Spark的分布式计算能力,对预测模型进行并行化处理,提高了系统的性能和效率[8]。 另外,国外的一些大型互联网公司,如Google、Facebook等,也利用Hadoop和Spark构建了类似的大数据分析和推荐系统。这些系统可以处理海量的用户行为数据和社交媒体信息,并通过机器学习和深度学习技术进行数据挖掘和分析,从而为广告商和投资者提供更精确的推荐和预测服务[9]。 自己的见解 首先,随着大数据时代的到来,股票市场也面临着越来越多的数据挑战。传统的股票分析方法往往依赖于人工分析和专家的经验,已经无法满足投资者和金融机构的需求。因此,利用大数据技术对股票数据进行挖掘和分析,提高股票市场的效率和准确性,具有重要的实际意义。 其次,Hadoop和Spark作为当前大数据领域的两个重要技术,具有各自的优势和特点。Hadoop具有强大的分布式存储和处理能力,可以处理大规模的数据集;而Spark则具有高效的内存存储和计算能力,可以加速数据分析和机器学习算法的执行。将两者结合起来,可以充分发挥各自的优势,提高股票数据分析的效率和准确性[10]。 再次,股票分析与推荐系统是大数据应用的一个重要领域。通过分析历史股价数据和市场趋势,可以预测未来股票价格的波动趋势,为投资者提供个性化的股票投资建议。同时,结合推荐算法和机器学习技术,还可以为金融机构提供精准的客户服务和风险管理方案。这有助于提升金融业务的智能化水平,增强金融行业的竞争力[11]。 最后,随着人工智能和机器学习技术的不断发展,越来越多的学者和专家开始关注股票市场的数据挖掘和分析。通过引入先进的算法和模型,可以更好地揭示股票市场的规律和趋势,为投资者和金融机构提供更准确的决策支持。同时,随着金融市场的不断开放和金融科技创新的发展,大数据技术在金融领域的应用也将得到更广泛的推广和应用。 综上所述,《基于Hadoop+Spark的股票分析与推荐系统的设计与实现》这一选题具有重要的理论意义和实践价值。通过该领域的研究和应用,可以推动大数据技术在金融领域的应用和发展,提高股票市场的效率和准确性,降低投资风险,提升金融业务的智能化水平,增强金融行业的竞争力。同时,也有助于拓展机器学习和深度学习技术在金融领域的应用范围,推动金融科技创新的发展。 | |||||
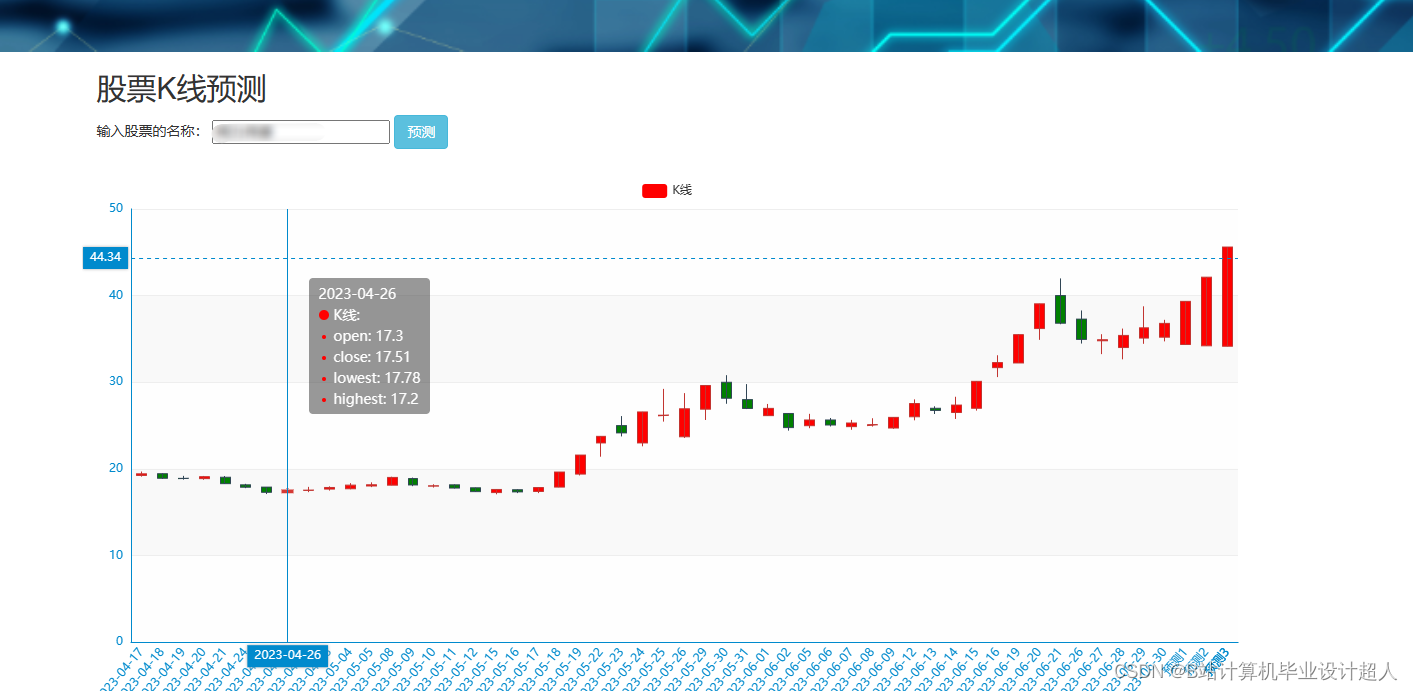
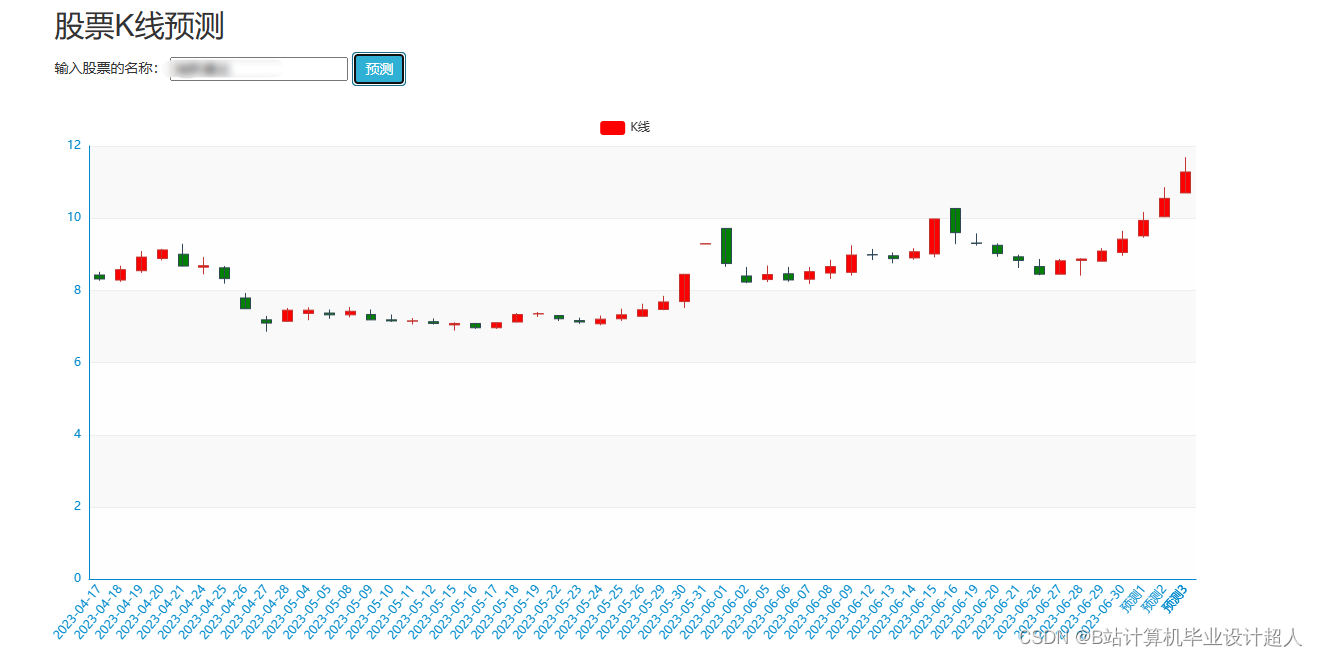
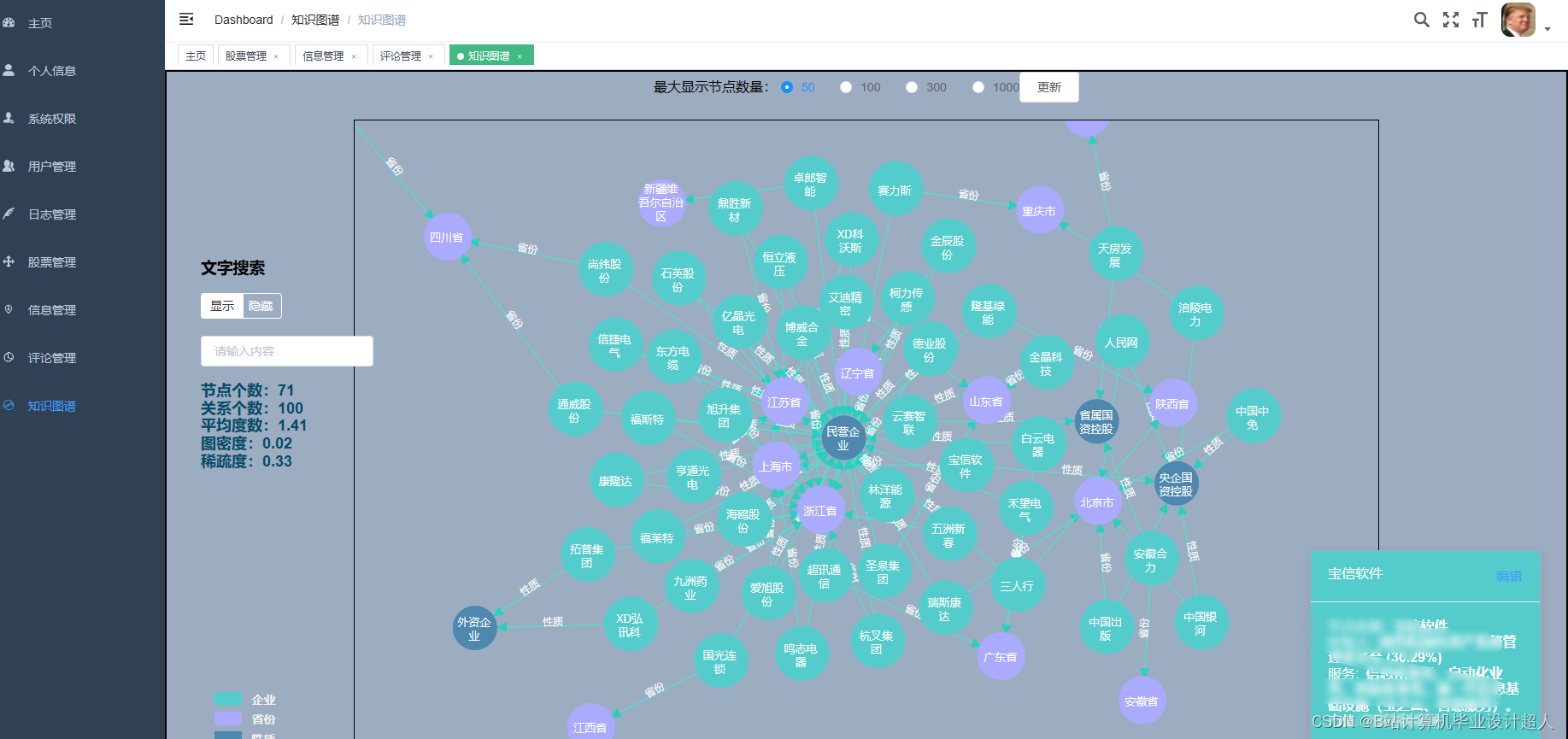
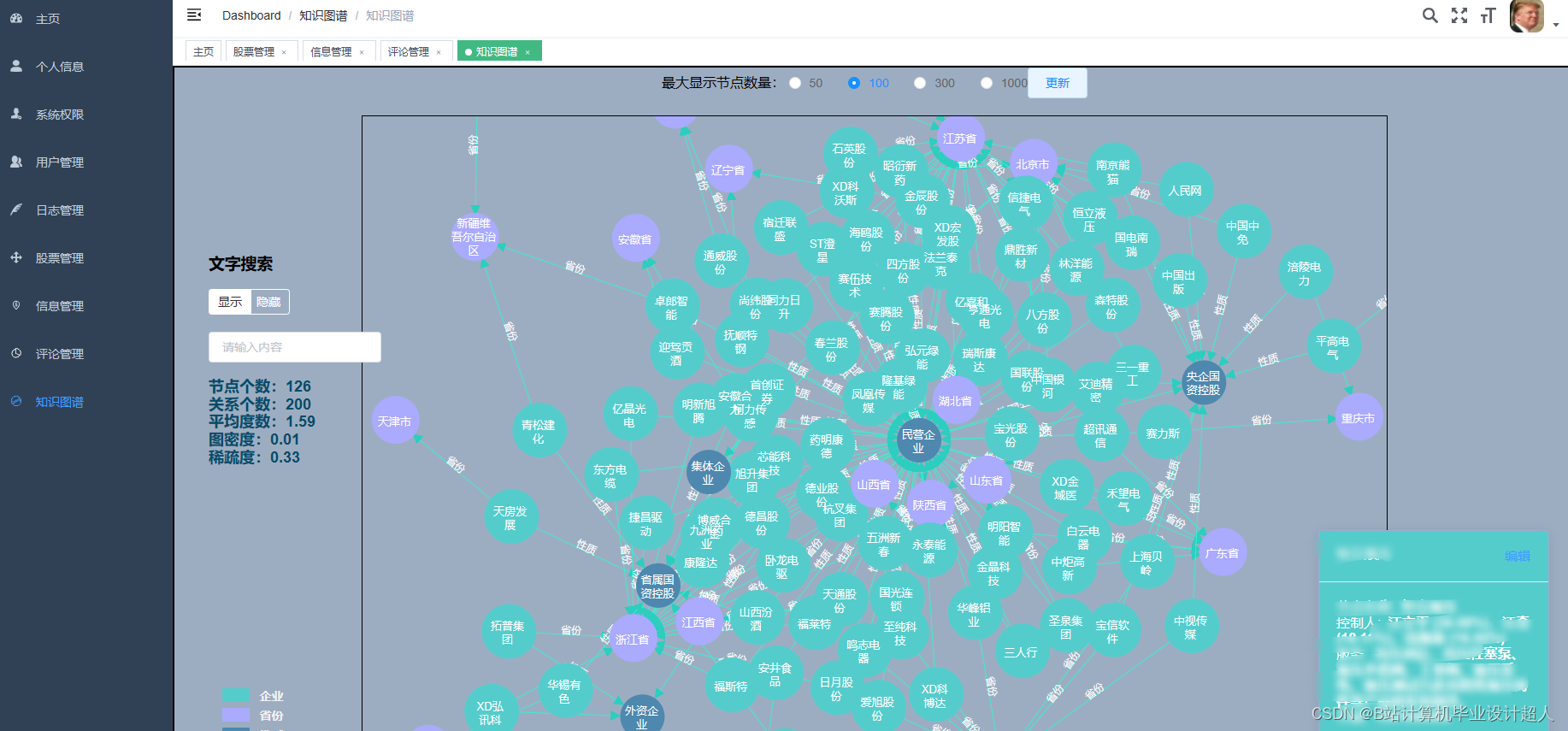
| 主要内容: 1、数据采集:收集股票市场的历史数据和实时数据,包括股票价格、成交量、财务指标等。 2、门户系统:首页股票信息展示;股票推荐(根据协同过滤基于用户、物品、SVD神经网络、MLP模型);股票K线预测(CNN卷积神经预测 );股票信息详情(股票代码,涨跌幅度,成交量,成交额,换手率,股票市值); 支付宝购买股票;订单管理;股票信息评论(lstm情感分析模型)。 3、后台管理系统:个人信息管理;系统管理;用户管理;股票信息管理;评论信息管理;知识图谱。 | |||||
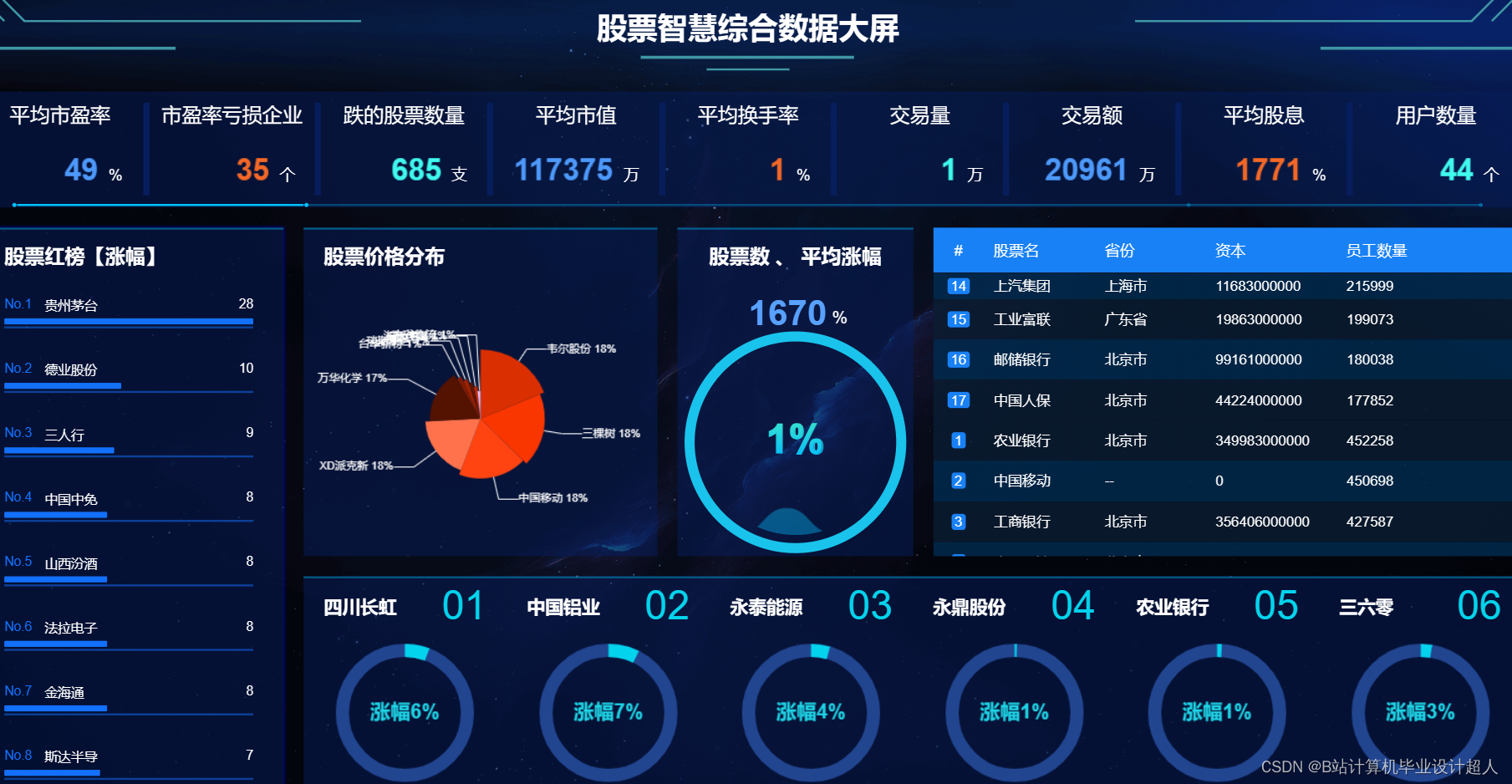
| 研究方法: 1.采集雪球网约50万股票数据存入.csv文件; 2.使用pandas+numpy或hadoop+mapreduce对mysql中的数据进行数据清洗并转存新的.csv文件,将文件上传到hdfs; 3.使用hive建表建库导入hdfs中的.csv数据集; 4.一半指标使用hive_sql进行离线计算分析,一半指标使用Spark之Scala语法进行实时计算分析; 5.分析结果使用sqoop导入mysql数据库; 6.使用flask+echarts搭建可视化大屏界面; 7.使用springboot+vue.js搭建web系统,实现智能推荐、股票预测、情感分析、知识图谱等业务功能。 | |||||
| 完成期限和采取的主要措施: 第1-3周:熟悉题目,调研技术,拟定功能,完成开题报告编写。 第4-5周:完成总体需求分析,根据系统需要建立数据库。使用Python爬虫采集股票数据,对数据进行数据清洗。 第6-9周:初步完成数据分析的全部功能,实现股票可视化大屏。 第10-12周:搭建web系统,完成推荐、预测、情感分析等功能。 第13-16周:根据系统设计过程中的记录文挡及其功能编写毕业论文。 | |||||
| 主要参考文献及资料名称: [1]周志华. 机器学习[M]. 清华大学出版社, 2021. [2]罗森林, 王晨, 王丽珍. Spark机器学习[M]. 机械工业出版社, 2022. [3]赵鹏飞, 王妍, 吴燕, 等. 基于Hadoop的金融数据处理技术研究[J]. 微型机与应用, 2023, 36(19): 5-8. [4]孟祥福, 王清毅, 张俊颖, 等. 基于Hadoop的金融大数据分析[J]. 计算机研究与发展, 2021, 55(4): 867-879. [5]王晓东, 王敏, 王秀峰. 基于Spark的金融数据挖掘与分析[J]. 计算机应用研究, 2022, 36(3): 605-608. [6]张志华, 王丽珍, 王晨. 基于Hadoop与Spark的混合计算模型研究[J]. 计算机科学与探索, 2022, 13(4): 633-642. [7]陈明忠, 黄丽丽, 王妍. 基于Hadoop与Spark的股票数据分析与推荐系统设计[J]. 信息技术, 2020, 44(1): 44-49. [8]王晓东, 王晨, 王秀峰. 基于Spark的股票数据挖掘与推荐算法研究[J]. 计算机应用研究, 2021, 38(1): 9-14. [9]张志华, 王丽珍, 王晨. 基于深度学习的股票预测与推荐系统设计与实现[J]. 软件学报, 2021, 32(5): 1369-1380. [10]王妍, 王清毅, 张俊颖, 等. 基于Spark Streaming的实时股票数据分析与推荐系统[J]. 软件学报, 2021, 32(6): 1709-1720. [11]陈明忠, 黄丽丽, 王妍. 基于Spark的股票趋势预测与推荐算法研究[J]. 中国管理科学, 2021, 29(7): 178-186. [12]王晓东, 王晨, 王秀峰. 基于Spark MLlib的股票分类与推荐算法研究[J]. 计算机应用研究, 2022, 39(1): 9-14. | |||||
| 指导教师意见: | |||||
| 指导教师签字: 年 月 日 | |||||

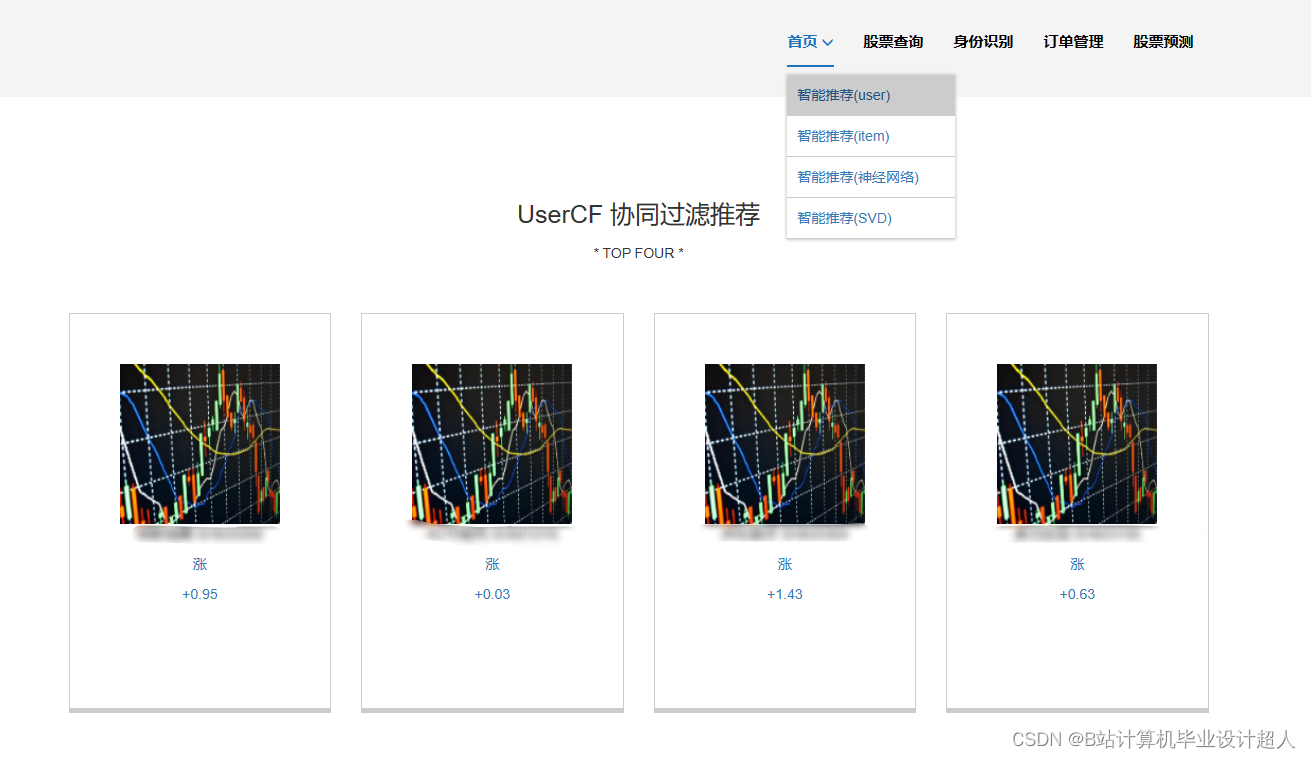
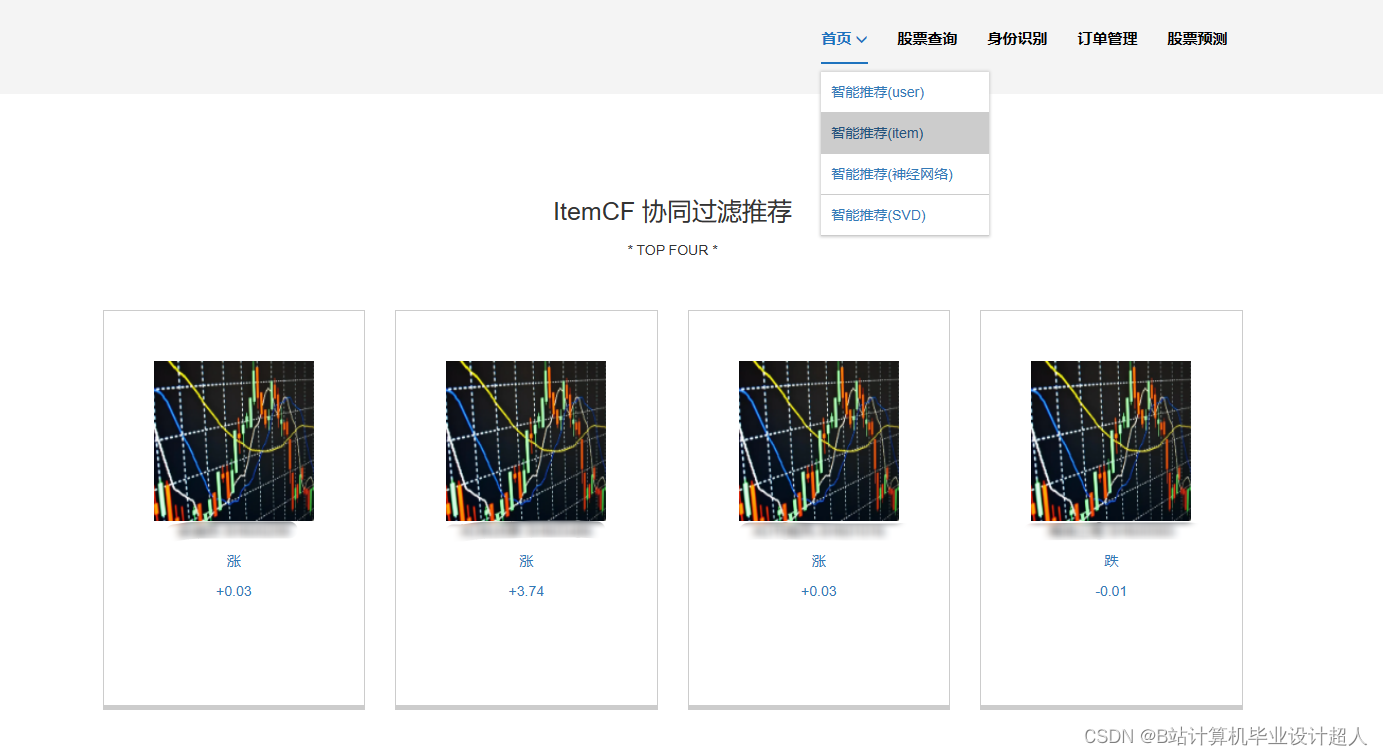
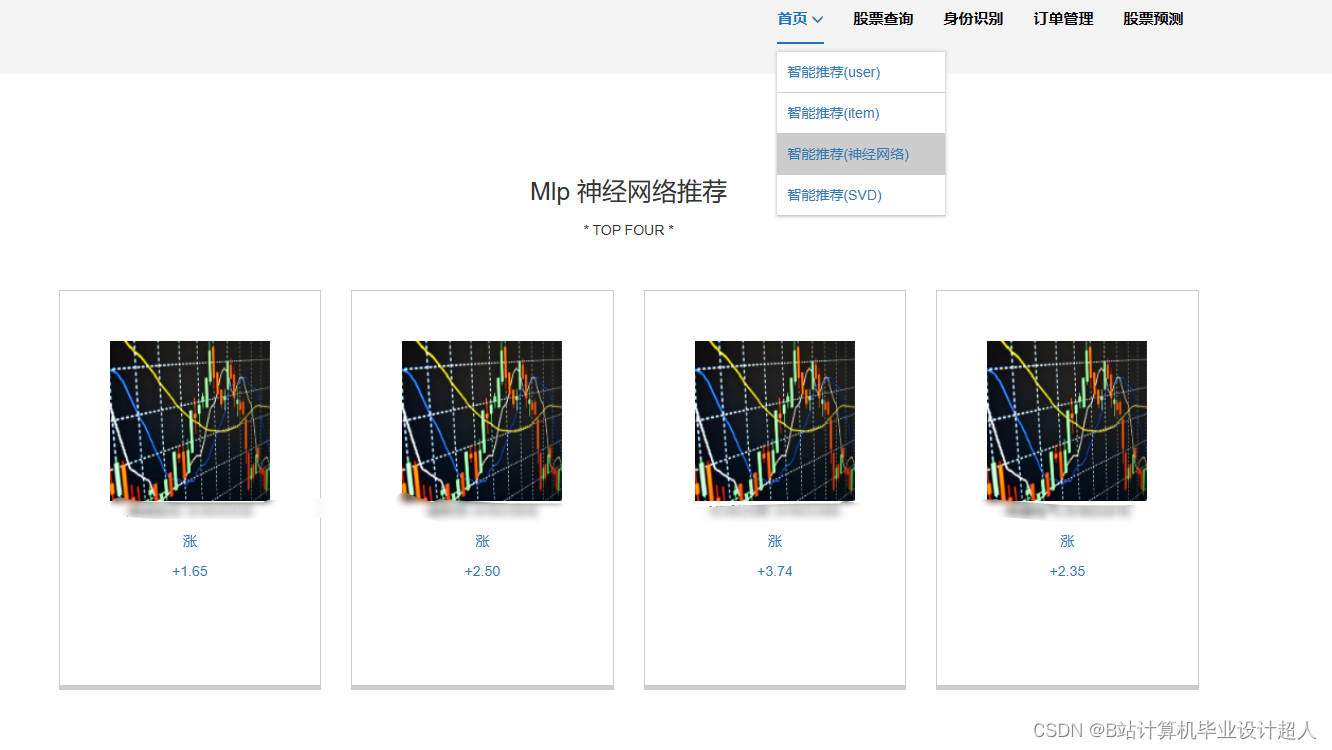
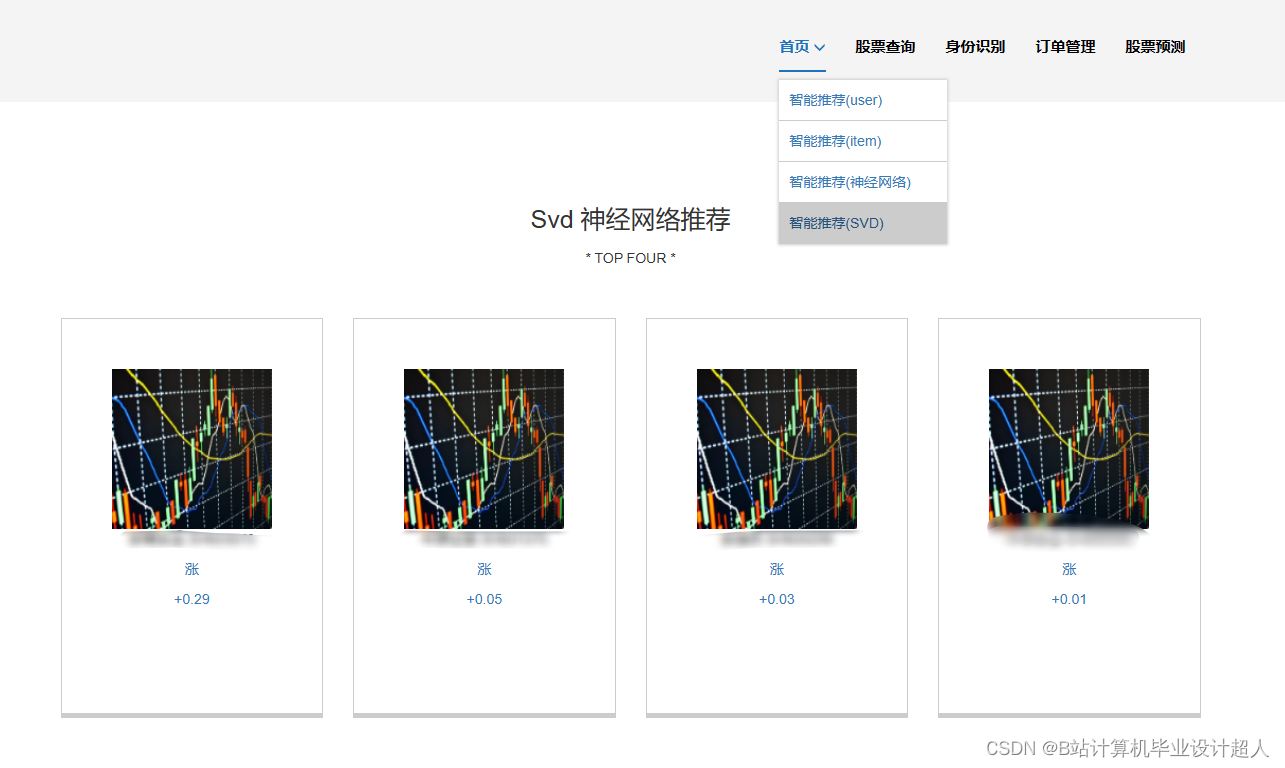
核心算法代码分享如下:
import sys
from db import cnn
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
def predict1(name):
sql = "select `name`, `open` as value from tb_flow" \
" where name='%s' order by sdate desc limit 7 " % (name)
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5, 6, 7]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
def predict2(name):
sql = "select `name`, `close` as value from tb_flow" \
" where name='%s' order by sdate desc limit 7 " % (name)
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5, 6, 7]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
def predict3(name):
sql = "select `name`, `high` as value from tb_flow" \
" where name='%s' order by sdate desc limit 7 " % (name)
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5, 6, 7]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
def predict4(name):
sql = "select `name`, `low` as value from tb_flow" \
" where name='%s' order by sdate desc limit 7 " % (name)
with cnn.cursor() as cursor:
cursor.execute(sql)
print(sql)
names = []
y = []
for line in cursor.fetchall():
# print(line)
y.append(line[1])
names.append(line[0])
y = y[::-1]
X = [1, 2, 3, 4, 5, 6, 7]
X = pd.DataFrame(X)
X = X.values
Poly_regressor = PolynomialFeatures(degree=2)
Poly_X = Poly_regressor.fit_transform(X)
regressor = LinearRegression()
regressor.fit(Poly_X, y)
p1 = regressor.predict(Poly_regressor.fit_transform([[8]]))
p2 = regressor.predict(Poly_regressor.fit_transform([[9]]))
p3 = regressor.predict(Poly_regressor.fit_transform([[10]]))
r = []
r.append(round(float(p1[0]),2))
r.append(round(float(p2[0]),2))
r.append(round(float(p3[0]),2))
return r
if __name__ == '__main__':
name = sys.argv[1]
ret = []
r1 = predict1(name)
r2 = predict2(name)
r3 = predict3(name)
r4 = predict4(name)
ret.append(r1)
ret.append(r2)
ret.append(r3)
ret.append(r4)
print(ret)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











