







背景
- 传统的服务治理一般通过rpc框架去解决,多年以来百度内部也衍生出多种语言的rpc框架,比如c++、go、php等等框架,基础服务治理能力和rpc框架耦合,rpc框架能力层次不齐,给公司整体服务治理能力和效率提升带来较多的痛点及挑战:
-
高级架构能力无法多语言、多框架复用。
-
架构容错能力治理周期长,基础能力覆盖度低。
-
可观测性不足,是否有通用机制提升产品线可观测性。
-
(一)容错治理效率
问题描述
多数模块对单点异常,慢节点等异常缺乏基础容忍能力,推动每个模块独立修复,成本高,上线周期长。
落地效果
- 产品线整体容错治理迭代周期从季度级缩短到月级
- 百度APP 2019年评论一级服务改造2个季度 ->百度APP业务线接入mesh一个月完成4个方向20+模块架构容错治理改造
- 模块治理迭代周期从周级别进一步缩短到分钟级别
- FEED&百度APP超时干预、动态重试、lb调整等日常治理策略,分钟级生效
(二)容错治理能力弱
问题描述
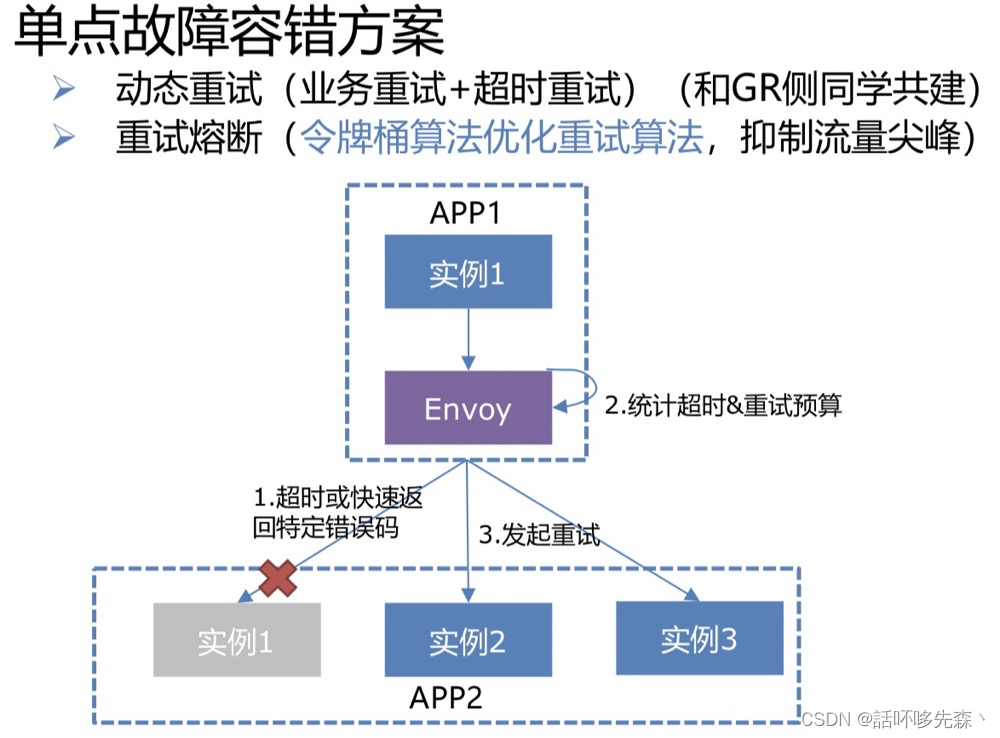
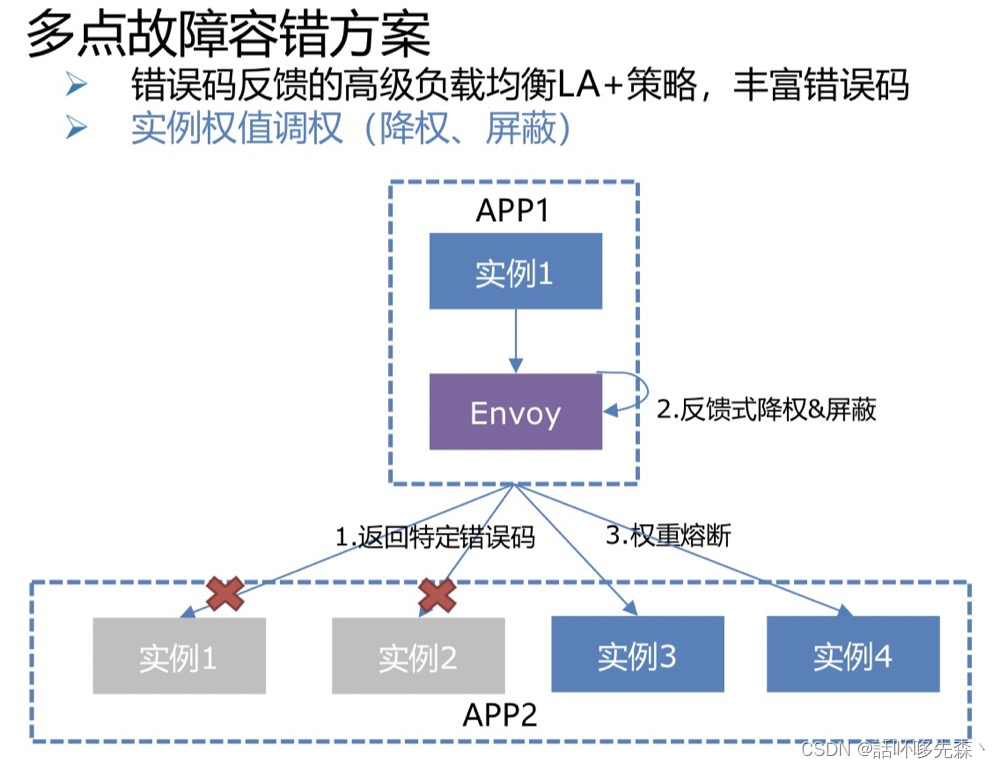
百度APP&Feed产品线单点、多点故障容错能力覆盖面不足,基础故障报警周级别占比10.4%,统一治理成本高。
解决方案
落地效果
- 【容错能力覆盖面提升】Feed队列&召回多点容错能力覆盖面从0->100%,手百一级模块基础容错能力覆盖度从 66.7% -> 100%,二级模块基础治理能力覆盖度从 0% -> 90%
- 【故障韧性能力提升】报警周级别占比由10.4%降低到<2% ,混沌实验下容忍20+基础故障场景,局部故障条件下日常SLA保持3个9以上。
(三)雪崩类问题
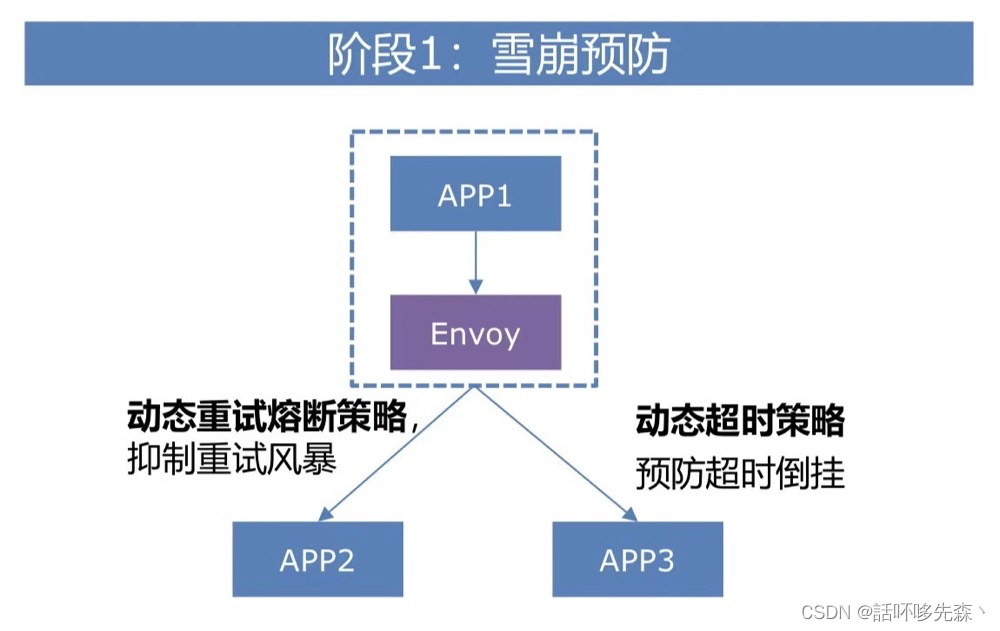
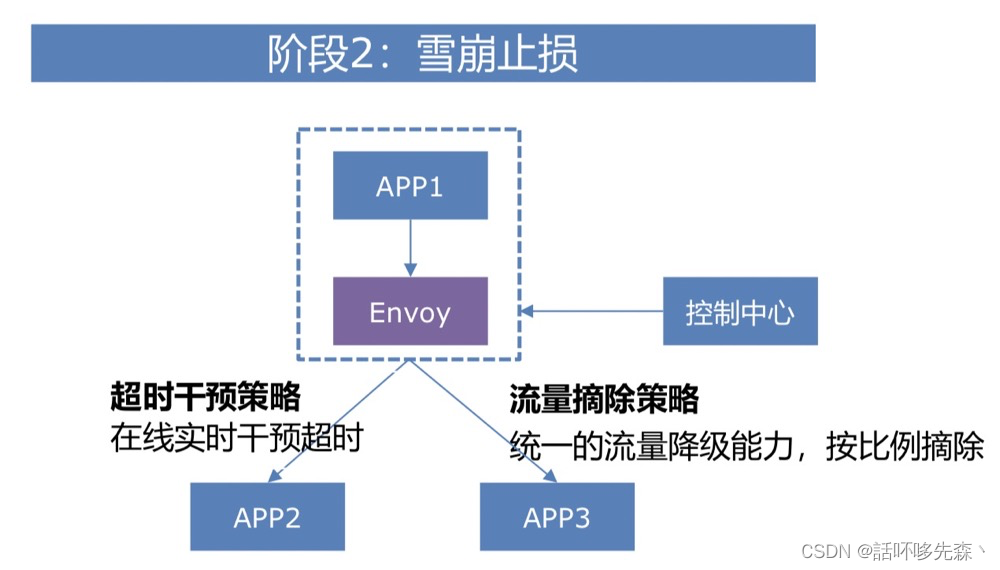
问题描述
百度APP&FEED&矩阵近3年来线上出现近30起雪崩Case(1.5亿PV损失),缺少统一的雪崩治理能力 ,90%的雪崩是因为重试风暴、超时倒挂、降级能力缺失(分别占 56%、19%、15%),统一治理成本高,周期长。
解决方案
落地效果
- 【雪崩整体损失量下降】2020年对比2019年,雪崩类Case核心接口损失环比下降44%
- 【故障韧性能力提升】混沌实验下,容忍20+基础故障场景,报警周级别占比由10.4%降低到<2%。
- 【历史Case覆盖面提升】覆盖近2年内雪崩90%+故障场景,可挽回 7200W+ PV损失,占比>47%。
(四)可观测性不足
问题描述
构建产品线模块上下游调用链一直缺乏通用的解决方案,大多数都是基于rpc框架或者业务框架定制,模块调用链覆盖率低。比如某重要产品线端到端涉及到2000多个模块,调用链关系十分复杂,具体流量的来源不够透明,严重影响运维效率。如机房搭建不知道上下游的连接关系,靠人肉梳理误差大,某产品线一次搭建周期将近2个月时间。另外故障定位、容量管理等由于全局的可观测性不足,往往只能依赖经验定位,效率十分低下。
(五)高级架构能力无法多语言、多框架复用
问题描述
如某产品线近2年发生数次雪崩case,底层依赖的php、golang等框架需要重复建设来定制动态熔断、动态超时等高级能力,而这些能力在其他rpc框架如已支持。
落地效果
| 编程语言 | Golang, C++, PHP |
|---|---|
| RPC框架 | GDP(1.0, 1.5, 2.0), BRPC, Ral、Phaster |
| 协议 | Nshead,HTTP, Redis,baidu_std |
(六) 治理标准不一致,运维成本高
问题描述
如常用架构降级、止损能力各个产品线重复建设,接口方案差异大,从运维层面,运维同学期望基础的架构止损能力在不同产品线之间能够通用化,接口标准化,降低运维成本。















 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









