






参考数据挖掘十大算法(六):PageRank算法原理与Python实现_梦想总是要不可及,是不是应该放弃的博客-CSDN博客
PageRand算法:
历史上,PageRank算法作为计算互联网网页重要度的算法被提出。PageRank是定义在网页集合上的一个函数,它对每个网页给出一个正实数,表示网页的重要程度,整体构成一个向量,PageRank值越高,网页就越重要,在互联网搜索的排序中可能就被排在前面。
假设互联网是一个有向图,在其基础上定义随机游走模型,即一阶马尔可夫链,表示网页浏览者在互联网上随机浏览网页的过程。假设浏览者在每个网页依照连接出去的超链接以等概率跳转到下一个网页,并在网上持续不断进行这样的随机跳转,这个过程形成一阶马尔可夫链。PageRank表示这个马尔可夫链的平稳分布。每个网页的PageRank值就是平稳概率。
主要思想有两点:
1. 如果多个网页指向某个网页A,则网页A的排名较高。
2. 如果排名高A的网页指向某个网页B,则网页B的排名也较高,即网页B的排名受指向其的网页的排名的影响。

python实现:
实现迭代法,代码如下,需要用到Python的numpy库用于矩阵乘法:
import numpy as np
if __name__ == '__main__':
# 读入有向图,存储边
f = open('C:/Users/Administrator/Desktop/text912.txt', 'r')
edges = [line.strip('\n').split(' ') for line in f]
print(edges)
# 根据边获取节点的集合
nodes = []
for edge in edges:
if edge[0] not in nodes:
nodes.append(edge[0])
if edge[1] not in nodes:
nodes.append(edge[1])
print(nodes)
N = len(nodes)
# 将节点符号(字母),映射成阿拉伯数字,便于后面生成A矩阵/H矩阵
i = 0
node_to_num = {}
for node in nodes:
node_to_num[node] = i
i += 1
for edge in edges:
edge[0] = node_to_num[edge[0]]
edge[1] = node_to_num[edge[1]]
print(edges)
# 生成初步的S矩阵
H = np.zeros([N, N])
for edge in edges:
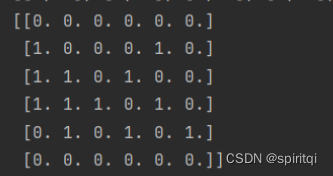
H[edge[1], edge[0]] = 1
print(H)
# 计算比例:即一个网页对其他网页的PageRank值的贡献,即进行列的归一化处理
for j in range(N):
sum_of_col = sum(H[:, j])
for i in range(N):
H[i, j] /= sum_of_col
print(H)
# 计算矩阵A
alpha = 0.85
A = alpha * H + (1 - alpha) / N * np.ones([N, N])
print(A)
# 生成初始的PageRank值,记录在P_n中,P_n和P_n1均用于迭代
P_n = np.ones(N) / N
P_n1 = np.zeros(N)
e = 100000 # 误差初始化
k = 0 # 记录迭代次数
print('loop...')
while e > 0.00000001: # 开始迭代
P_n1 = np.dot(A, P_n) # 迭代公式
e = P_n1 - P_n
e = max(map(abs, e)) # 计算误差
P_n = P_n1
k += 1
print('iteration %s:' % str(k), P_n1)
print('final result:', P_n)
且我们输入的文本text912的内容为(看图为前者指向后者):
1->2、1->3、1->4、2->3......
故矩阵为:
1 2
1 3
1 4
2 3
2 4
2 6
3 4
4 3
4 6
5 6
6 2
6 4
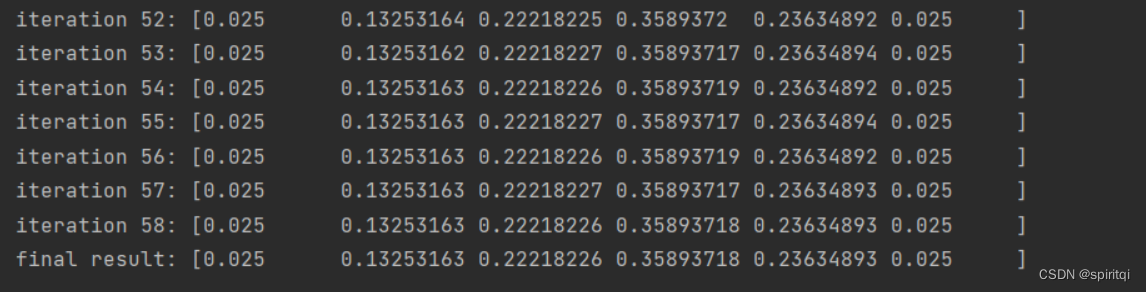
PageRank从高到低:
4
3
2
5
1、6
















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











