







一. 预备工具:
MemoTrace1.11、 Python3.10、 Tableau Public
二. 聊天记录的爬取
MemoTrace1.11的安装
安装无提示,双击后一会出现新的文件夹。
解密和聊天记录的导出
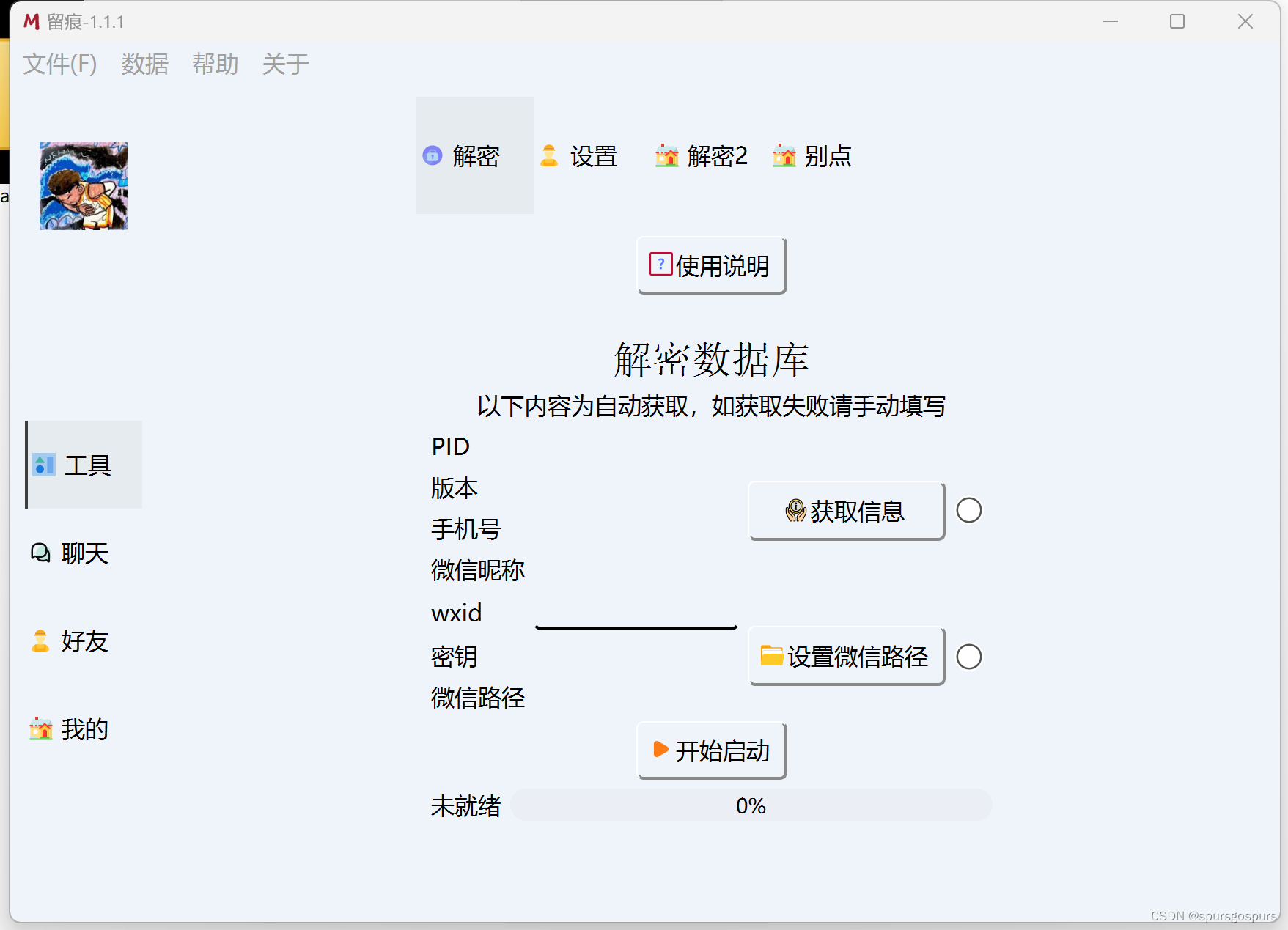
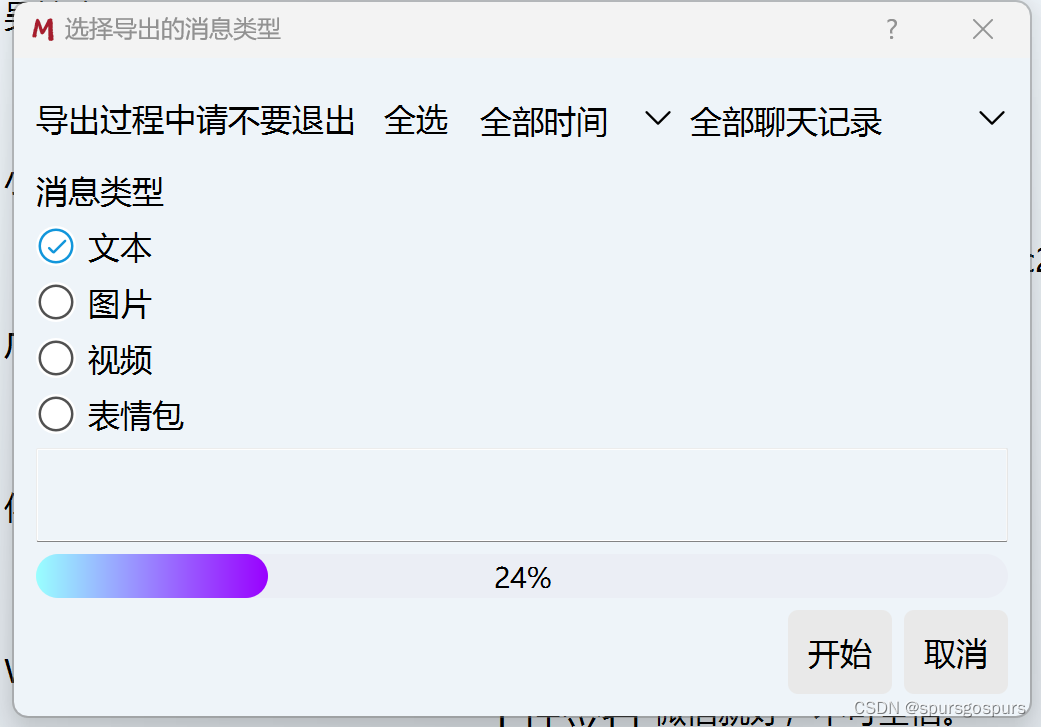
点击【获取信息】后自动出现相关信息,然后点击【开始启动】即可,完毕按要求重新启动软件
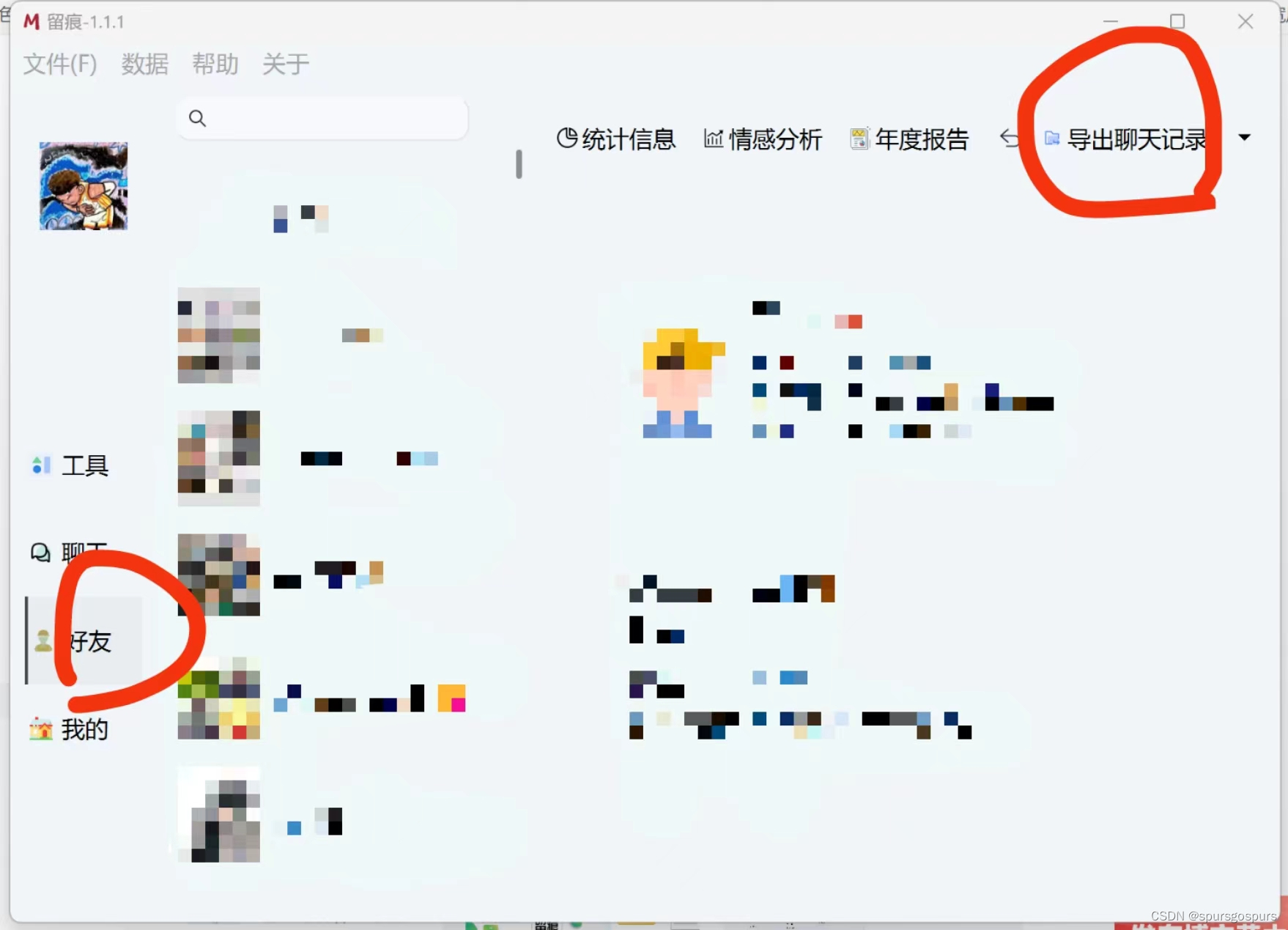
点击【好友】,选中对象,点击【导出聊天记录】,导出CSV格式的聊天记录,只选择文本,导出位置与exe文件在同一目录。
三. 利用Python3.10处理数据
自行安装python3.10版本,本文不再赘述。其他版本可能导致热力图生成出现bug。
自行选择词云所用背景图(注意:颜色形状复杂的图片可能运行失败)和包含字体
将背景图、包含字体、前面导出的聊天记录文件和下述代码放在同一个文件夹。

import pandas as pd
import jieba
from datetime import datetime
import datetime as dt
import time
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
from wordcloud import WordCloud, ImageColorGenerator
import os
from os import path
from imageio.v2 import imread
# 源csv文件的地址
ori_csv = r'聊天记录.csv'
# 下面3个分别是将源csv文件中Type为1的StrContent的内容提取出来的文件,第一个是双方共同的,第二个是0方的,第三个是1方的
out_txt = r"聊天记录.txt"
out_txt0 = r"聊天记录0.txt"
out_txt1 = r"聊天记录1.txt"
# 这下面这个是报错存储的文件地址,在这里可以看到整个过程的报错
err_file = "错误.txt"
# 这下面3个是词频统计后的输出文件地址,第一个是双方共同的,第二个是0方的,第三个是1方的
word_txt = r"聊天记录-词频统计.txt"
word_txt0 = r"聊天记录0-词频统计.txt"
word_txt1 = r"聊天记录1-词频统计.txt"
# 这下面3个是统计每天说话的字符数,第一个是双方共同的,第二个是0方的,第三个是1方的
word_day = r"聊天记录-具体的天.csv"
word_day0 = r"聊天记录0-具体的天.csv"
word_day1 = r"聊天记录1-具体的天.csv"
# 这下面3个是统计24h中说话的字符数,是所有天数的24h,第一个是双方共同的,第二个是0方的,第三个是1方的
word_hour = r"聊天记录-24h.csv"
word_hour0 = r"聊天记录0-24h.csv"
word_hour1 = r"聊天记录1-24h.csv"
# 下面这个是聊天所有字数的txt文件,分别包含总的和各自的
word_all = r"聊天记录-all.txt"
# 下面这个是设置热力图大小和颜色的
heatmap_r = 50
heatmap_l = 6
heatmap_dpi = 300
heatmap_color_l = '#ecd7dc'
heatmap_color_r = '#e7385c'
# 下面设置背景图的文件地址
back_path = r'背景图.jpg'
# 这下面是3个用于指定时间,比如,0-2点的每小时的字符数,第一个是双方共同的,第二个是0方的,第三个是1方的
word_hour_spe = r"聊天记录-spe-hour.csv"
word_hour_spe0 = r"聊天记录0-spe-hour.csv"
word_hour_spe1 = r"聊天记录1-spe-hour.csv"
# 这下面两个是设置指定时间的,0和1表示0-2点,最多能到23
hour_start = 0
hour_end = 1
# 这个函数负责将text中的内容写到报错文件里面
def write_err(text):
with open(err_file, "a") as f:
f.write(text + '\n')
# 这个函数负责生成out_txt,out_txt0与out_txt1
def out_txt_create():
f = open(out_txt, "w", encoding="utf-8")
f0 = open(out_txt0, "w", encoding="utf-8")
f1 = open(out_txt1, "w", encoding="utf-8")
data = pd.read_csv(ori_csv)
# 这里只选择了Type为1的,要进行其他选择可以在下面这里改
for index, row in data.iterrows():
if row["Type"] == 1 and row["IsSender"] == 0:
try:
f0.write(str(row["StrContent"]) + '\n')
except Exception as e:
write_err(f'行: {index}, localId: {row["localId"]}, StrContent: {row["StrContent"]}, err: {e}')
elif row["Type"] == 1 and row["IsSender"] == 1:
try:
f1.write(str(row["StrContent"]) + '\n')
except Exception as e:
write_err(f'行: {index}, localId: {row["localId"]}, StrContent: {row["StrContent"]}, err: {e}')
if row["Type"] == 1:
try:
f.write(str(row["StrContent"]) + '\n')
except Exception as e:
write_err(f'行: {index}, localId: {row["localId"]}, StrContent: {row["StrContent"]}, err: {e}')
f.close()
f0.close()
f1.close()
# 词频统计,in_path必须是out_txt_create函数生成的文件,负责统计文件中的词语的数量,然后输出前num个的词语到out_path中,并且会将前num个词频高的词return
def word_count(in_path, out_path, num):
# 打开文本存储的txt文件
text = open(in_path, "r", encoding="utf-8").read()
# 输出词频统计的txt文件,可能需 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









