







0 解与算符
对于线性反问题 G m = d \mathbf{Gm=d} Gm=d的方法,长度方法基于分析解的两个属性:预测误差和解的简单程度。而广义逆的方法,则希望通过研究算符矩阵来获得更多关于反问题的属性。
假设求解反问题 G m = d \mathbf{Gm = d} Gm=d,存在一个广义逆可求解模型估计, m e s t = G − g d \mathbf{m^{est}=G^{-g}d} mest=G−gd,这里的 G − g G^{-g} G−g为广义逆。
通过广义逆,可以求取:
1)数据分辨率矩阵
2)模型分辨率矩阵
3)单位协方差矩阵
1 分辨率和协方差
1.1 数据分辨率矩阵
假设:已知一个求解反问题
G
m
=
d
\mathbf{Gm=d}
Gm=d的广义逆,并求解出模型参数估计
m
e
s
t
=
G
−
g
d
\mathbf{m^{est}=G^{-g}d}
mest=G−gd
那么,这个模型参数的估计值
m
e
s
t
\mathbf{m^{est}}
mest对实测数据
d
o
b
s
\mathbf{d^{obs}}
dobs的拟合有多好呢?(即预测数据有多接近观测数据?)
通过将
m
e
s
t
\mathbf{m^{est}}
mest带入
G
m
=
d
\mathbf{Gm=d}
Gm=d中,可得到:
d
pre
=
G
m
est
=
G
[
G
−
g
d
obs
]
=
[
G
G
−
g
]
d
obs
=
N
d
obs
\mathbf{d}^{\text {pre }}=\mathbf{G m}^{\text {est }}=\mathbf{G}\left[\mathbf{G}^{-\mathbf{g}} \mathbf{d}^{\text {obs }}\right]=\left[\mathbf{G} \mathbf{G}^{-\mathbf{g}}\right] \mathbf{d}^{\text {obs }}=\mathbf{N} \mathbf{d}^{\text {obs }}
dpre =Gmest =G[G−gdobs ]=[GG−g]dobs =Ndobs
上式中:
上表pre,obs分别表示预测和观测;
N
=
G
G
−
g
\mathbf{N=GG^{-g}}
N=GG−g为数据分辨率矩阵,描述了预测值与观测数据匹配程度有多好
讨论:
N
=
I
\mathbf{N=I}
N=I,此时
d
p
r
e
=
d
o
b
s
d^{pre}=d^{obs}
dpre=dobs,那么预测误差为0;
N
≠
I
\mathbf{N \ne I}
N=I, 那么预测误差不为0,此时矩阵结构如下图:
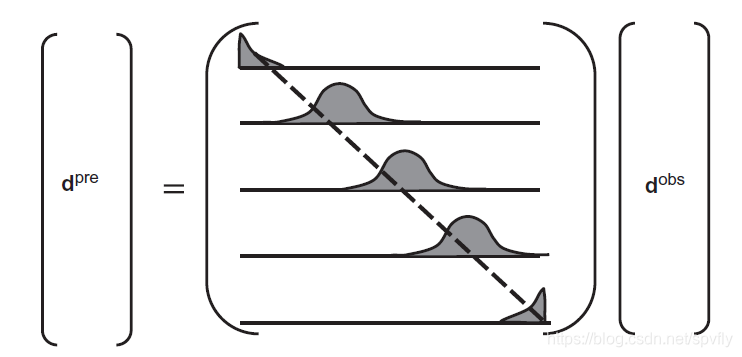
数据分辨率矩阵N的行,描述了相邻实测数据可以多大程度上独立地预测或求解。如在第
i
i
i行,这一行的元素的值为:
[
…
0
0
0
0.1
0.8
0.1
0
0
0
…
.
]
\left[\begin{array}{lllllllll} \ldots & 0 & 0 & 0 & 0.1 & 0.8 & 0.1 & 0 & 0 & 0 \ldots . \end{array}]\right.
[…0000.10.80.1000….]
那么,第
i
i
i个数据:
d
i
p
r
e
=
∑
j
=
1
N
N
i
j
d
j
o
b
s
=
0.1
d
i
−
1
o
b
s
+
0.8
d
i
o
b
s
+
0.1
d
i
+
1
o
b
s
d_{i}^{\mathrm{pre}}=\sum_{j=1}^{N} N_{i j} d_{j}^{\mathrm{obs}}=0.1 d_{i-1}^{\mathrm{obs}}+0.8 d_{i}^{\mathrm{obs}}+0.1 d_{i+1}^{\mathrm{obs}}
dipre=j=1∑NNijdjobs=0.1di−1obs+0.8diobs+0.1di+1obs
可以看出,
d
i
p
r
e
d_{i}^{\mathrm{pre}}
dipre是三个相邻观测数据的加权平均。上图中,如果行元素有单个尖锐的极大值,且它以主对角线为中心,那么数据可以被很好的恢复。若,图中的峰值非常宽,那么数据恢复较差。
需要指出的是,数据分辨率矩阵不是数据的函数,它仅是数据核 G \mathbf{G} G和施加于反问题的先验信息的函数。。因此,可以在没有实际进行实验的情况下计算和研究数据分辨率矩阵,是实验设计过程中的有用工具。
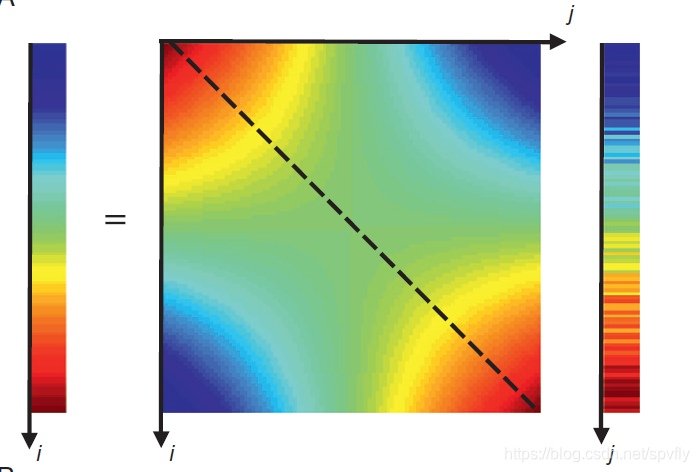
例子:考虑对数据点 ( z , d ) (z,d) (z,d)拟合一条直线的问题。如下图,用一条直线拟合100个沿 z z z轴等间距分布数据的情况,大值(红色)仅出现在主对角线(虚线)的两头,表明在 z z z取中间值时分辨率较差
1.2 模型分辨率矩阵
数据分辨率描述了数据是否可以被独立地预测或拟合。对于模型参数要探索的问题是,模型参数的一个特定估计
m
e
s
t
m^{est}
mest有多接近真实的模型参数?
假设:存在一个真实的模型参数
m
t
r
u
e
\mathbf{m^{true}}
mtrue,则
G
m
t
r
u
e
=
d
o
b
s
\mathbf{Gm^{true}=d^{obs}}
Gmtrue=dobs,
那么,模型参数的一个特定估计
m
e
s
t
m^{est}
mest有多接近真实的模型参数?
将
G
m
t
r
u
e
=
d
o
b
s
\mathbf{Gm^{true}=d^{obs}}
Gmtrue=dobs,代入
m
e
s
t
=
G
−
g
d
o
b
s
\mathbf{m^{est}}=\mathbf{G^{-g}d^{obs}}
mest=G−gdobs,得到
m
e
s
t
=
G
−
g
d
o
b
s
=
G
−
g
[
G
m
t
r
u
e
]
=
[
G
−
g
G
]
m
t
r
u
e
=
R
m
t
r
u
e
\mathbf{m}^{\mathrm{est}}=\mathbf{G}^{-\mathrm{g}} \mathbf{d}^{\mathrm{obs}}=\mathbf{G}^{-\mathrm{g}}\left[\mathbf{G} \mathbf{m}^{\mathrm{true}}\right]=\left[\mathbf{G}^{-\mathrm{g}} \mathbf{G}\right] \mathbf{m}^{\mathrm{true}}=\mathbf{R} \mathbf{m}^{\mathrm{true}}
mest=G−gdobs=G−g[Gmtrue]=[G−gG]mtrue=Rmtrue
式中,
R
\mathbf{R}
R为分辨率矩阵。
如果
R
=
I
\mathbf{R=I}
R=I,模型参数都是唯一确定的。否则,模型参数的估计实际是真实模型参数的加权平均(如下图)。
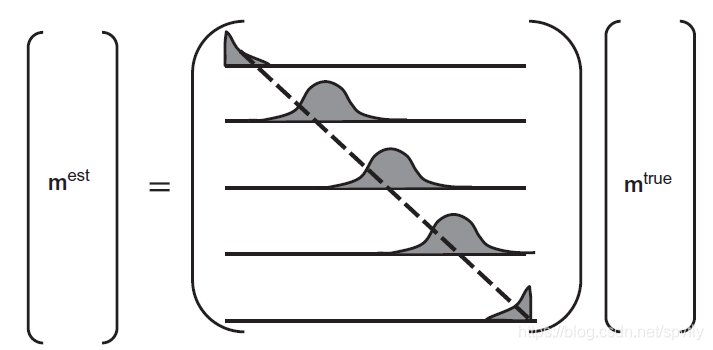
同数据分辨率矩阵一样,它是数据核和先验信息的函数。可作为实验设计的另一个重要工具。
例子:拉普拉斯变换(Laplace transform)的分辨率:
d
(
c
)
=
∫
0
∞
exp
(
−
c
z
)
m
(
z
)
d
z
→
d
i
=
∑
j
=
1
M
exp
(
−
c
i
z
j
)
m
j
d(c)=\int_{0}^{\infty} \exp (-c z) m(z) d z \rightarrow d_{i}=\sum_{j=1}^{M} \exp \left(-c_{i} z_{j}\right) m_{j}
d(c)=∫0∞exp(−cz)m(z)dz→di=j=1∑Mexp(−cizj)mj
上式中:
d
i
d_i
di, 模型参数
m
j
m_j
mj的加权平均,权重随深度
z
z
z衰减。指数的衰减速率由常数
c
i
c_i
ci控制,以致较小的
i
i
i对应于深度范围的平均,而较大的
i
i
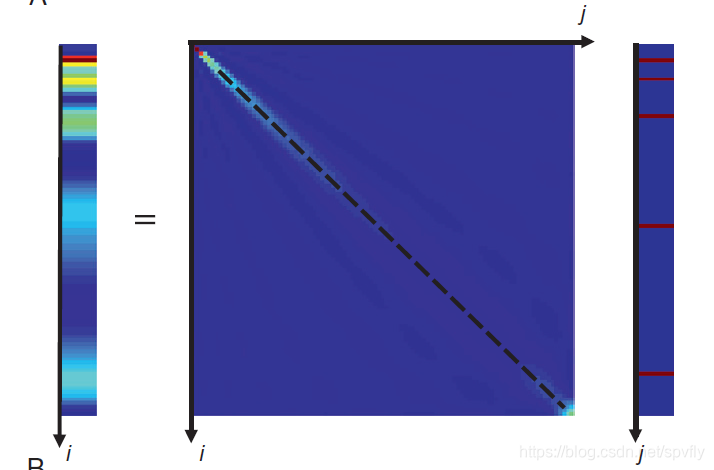
i对应于较浅深度范围的平均。其浅部模型参数被较好地求解了。如下图,大值(红色)仅出现在主对角线(虚线)的接近顶部(较小z值),表明在较大z值处分辨率较差。
1.3 单位协方差矩阵
模型参数的协方差依赖于:数据的协方差和 误差从数据映射至模型参数的方式。用单位协方差矩阵,可以描述发生在映射过程中的误差幅度。
假设,数据是不相关的,且具有均匀的方差
σ
2
\sigma^2
σ2,那么单位协方差为:
[
cov
u
m
]
=
σ
−
2
G
−
g
[
cov
d
]
G
−
g
T
=
G
−
g
G
−
g
T
\left[\operatorname{cov}_{u} \mathbf{m}\right]=\sigma^{-2} \mathbf{G}^{-\mathbf{g}}[\operatorname{cov} \mathbf{d}] \mathbf{G}^{-\mathbf{g} \mathbf{T}}=\mathbf{G}^{-\mathbf{g}} \mathbf{G}^{-\mathbf{g} \mathbf{T}}
[covum]=σ−2G−g[covd]G−gT=G−gG−gT
将数据协方差矩阵进行归一化,形成一个单位数据协方差
[
cov
u
d
]
\left[\operatorname{cov}_{u} \mathbf{d}\right]
[covud],则上式可写为:
[
c
o
v
u
m
]
=
G
−
g
[
cov
u
d
]
G
−
g
T
\left[\mathrm{cov}_{\mathrm{u}} \mathbf{m}\right]=\mathbf{G}^{-\mathrm{g}}\left[\operatorname{cov}_{\mathrm{u}} \mathbf{d}\right] \mathbf{G}^{-\mathrm{g} \mathrm{T}}
[covum]=G−g[covud]G−gT
例子:考虑使用一条直线拟合
(
z
,
d
)
(z,d)
(z,d)数据的问题。截距
m
1
m_1
m1和斜率
m
2
m_2
m2的单位协方差矩阵为:
[
cov
u
m
]
=
1
N
∑
z
i
2
−
(
∑
z
i
)
2
[
∑
z
i
2
−
∑
z
i
−
∑
z
i
N
]
\left[\operatorname{cov}_{u} \mathbf{m}\right]=\frac{1}{N \sum z_{i}^{2}-\left(\sum z_{i}\right)^{2}}\left[\begin{array}{cc} \sum z_{i}^{2} & -\sum z_{i} \\ -\sum z_{i} & N \end{array}\right]
[covum]=N∑zi2−(∑zi)21[∑zi2−∑zi−∑ziN]
下图为使用最小二乘法对不相关的数据(黑圈)拟合为一条直线(红色),此数据具有均匀方差(垂直棒,
1
σ
1\sigma
1σ置信界限),图中A,B的方程相同,但A图数据没有很好的分开,而B图数据较为分散,因此预测数据的方差(蓝色曲线,
1
σ
1\sigma
1σ界限)图A较大,而图B较小。

2 反映分辨率和协方差好坏的度量
2.1 狄利克雷展布函数
对于分辨率和协方差矩阵,当它们为单位矩阵时为最佳,那么可以通过对分辨率矩阵中的非对角元素的大小和展布情况来作为分辨率的度量:
spread
(
N
)
=
∥
N
−
I
∥
2
2
=
∑
i
=
1
N
∑
j
=
1
N
[
N
i
j
−
δ
i
j
]
2
spread
(
R
)
=
∥
R
−
I
∥
2
2
=
∑
i
=
1
M
∑
j
=
1
M
[
R
i
j
−
δ
i
j
]
2
\begin{array}{l} \operatorname{spread}(\mathbf{N})=\|\mathbf{N}-\mathbf{I}\|_{2}^{2}=\sum_{i=1}^{N} \sum_{j=1}^{N}\left[N_{i j}-\delta_{i j}\right]^{2} \\ \operatorname{spread}(\mathbf{R})=\|\mathbf{R}-\mathbf{I}\|_{2}^{2}=\sum_{i=1}^{M} \sum_{j=1}^{M}\left[R_{i j}-\delta_{i j}\right]^{2} \end{array}
spread(N)=∥N−I∥22=∑i=1N∑j=1N[Nij−δij]2spread(R)=∥R−I∥22=∑i=1M∑j=1M[Rij−δij]2
上述这种基于分辨率矩阵与单位矩阵之间差值的
L
2
L_2
L2范数定义的度量,可称之为狄利克雷展布函数(Dirichlet spread functions)。
单位协方差的度量为:
size
(
[
cov
u
m
]
)
=
∥
[
var
u
m
]
1
/
2
∥
2
2
=
∑
i
=
1
M
[
cov
u
m
]
i
i
\text { size }\left(\left[\operatorname{cov}_{u} \mathbf{m}\right]\right)=\left\|\left[\operatorname{var}_{u} \mathbf{m}\right]^{1 / 2}\right\|_{2}^{2}=\sum_{i=1}^{M}\left[\operatorname{cov}_{u} \mathbf{m}\right]_{i i}
size ([covum])=∥∥∥[varum]1/2∥∥∥22=i=1∑M[covum]ii
式中,平方根是一个元素一个元素施加的。注意,协方差大小的度量没有考虑单位协方差矩阵中偏离主对角线元素的大小。
2.2 展布函数的应用举例
例子,考虑用展布函数去求解超定反问题
G
m
=
d
\mathbf{Gm=d}
Gm=d。
分析
N
\mathbf{N}
N的第
k
k
k行的展布
J
k
\mathbf{J_k}
Jk:
J
k
=
∑
i
=
1
N
(
N
k
i
−
δ
k
i
)
2
=
∑
i
=
1
N
N
k
i
2
−
2
∑
i
=
1
N
N
k
i
δ
k
i
+
∑
i
=
1
N
δ
k
i
2
J_{k}=\sum_{i=1}^{N}\left(N_{k i}-\delta_{k i}\right)^{2}=\sum_{i=1}^{N} N_{k i}^{2}-2 \sum_{i=1}^{N} N_{k i} \delta_{k i}+\sum_{i=1}^{N} \delta_{k i}^{2}
Jk=i=1∑N(Nki−δki)2=i=1∑NNki2−2i=1∑NNkiδki+i=1∑Nδki2
对
J
k
\mathbf{J_k}
Jk最小化,
∂
J
k
∂
G
q
r
−
g
=
0
\frac{\partial J_{k}}{\partial G_{q r}^{-g}}=0
∂Gqr−g∂Jk=0
对
J
k
J_k
Jk的三项分别求导,
第一项为:
∂
∂
G
q
r
−
g
[
∑
i
=
1
N
[
∑
j
=
1
M
G
k
j
G
j
i
−
g
]
[
∑
p
=
1
M
G
k
p
G
p
i
−
g
]
]
=
∂
∂
G
q
r
−
g
[
∑
i
=
1
N
∑
j
=
1
M
∑
p
=
1
M
G
j
i
−
g
G
p
i
−
g
G
k
j
G
k
p
]
=
2
∑
i
=
1
N
∑
j
=
1
M
∑
p
=
1
M
δ
j
q
δ
i
r
G
p
i
−
g
G
k
j
G
k
p
=
2
∑
p
=
1
M
G
p
r
−
g
G
k
q
G
k
p
\begin{aligned} \frac{\partial}{\partial G_{q r}^{-g}}\left[\sum_{i=1}^{N}\left[\sum_{j=1}^{M} G_{k j} G_{j i}^{-g}\right]\left[\sum_{p=1}^{M} G_{k p} G_{p i}^{-g}\right]\right] &=\frac{\partial}{\partial G_{q r}^{-g}}\left[\sum_{i=1}^{N} \sum_{j=1}^{M} \sum_{p=1}^{M} G_{j i}^{-g} G_{p i}^{-g} G_{k j} G_{k p}\right] \\ &=2 \sum_{i=1}^{N} \sum_{j=1}^{M} \sum_{p=1}^{M} \delta_{j q} \delta_{i r} G_{p i}^{-g} G_{k j} G_{k p} \\ &=2 \sum_{p=1}^{M} G_{p r}^{-g} G_{k q} G_{k p} \end{aligned}
∂Gqr−g∂[i=1∑N[j=1∑MGkjGji−g][p=1∑MGkpGpi−g]]=∂Gqr−g∂[i=1∑Nj=1∑Mp=1∑MGji−gGpi−gGkjGkp]=2i=1∑Nj=1∑Mp=1∑MδjqδirGpi−gGkjGkp=2p=1∑MGpr−gGkqGkp
第二项:
−
2
∂
∂
G
q
r
−
g
∑
i
=
1
N
∑
j
=
1
M
G
k
j
G
j
i
−
g
δ
k
i
=
−
2
∑
i
=
1
N
∑
j
=
1
M
G
k
j
δ
j
q
δ
i
r
δ
k
i
=
−
2
G
k
q
δ
k
r
-2 \frac{\partial}{\partial G_{q r}^{-g}} \sum_{i=1}^{N} \sum_{j=1}^{M} G_{k j} G_{j i}^{-g} \delta_{k i}=-2 \sum_{i=1}^{N} \sum_{j=1}^{M} G_{k j} \delta_{j q} \delta_{i r} \delta_{k i}=-2 G_{k q} \delta_{k r}
−2∂Gqr−g∂i=1∑Nj=1∑MGkjGji−gδki=−2i=1∑Nj=1∑MGkjδjqδirδki=−2Gkqδkr
第三项是0,整理可得:
∑
p
=
1
M
G
k
q
G
k
p
G
p
r
−
g
=
G
k
q
δ
k
r
\sum_{p=1}^{M} G_{k q} G_{k p} G_{p r}^{-g}=G_{k q} \delta_{k r}
p=1∑MGkqGkpGpr−g=Gkqδkr
对所有的k求和,并转化为矩阵形式,即得到:
G
T
G
G
−
g
=
G
T
\mathbf{G}^{\mathrm{T}} \mathbf{G} \mathbf{G}^{-\mathrm{g}}=\mathbf{G}^{\mathrm{T}}
GTGG−g=GT
由于
G
T
G
\mathbf{G^TG}
GTG是方阵,两边同时乘以它的逆,即可得到广义逆
G
−
g
=
[
G
T
G
]
−
1
G
T
\mathbf{G}^{-\mathrm{g}}=\left[\mathbf{G}^{\mathrm{T}} \mathbf{G}\right]^{-1} \mathbf{G}^{\mathrm{T}}
G−g=[GTG]−1GT
最小二乘广义逆可以被看作是某种逆,它既可以被认为是最小化预测误差,也可以被认为是最小化数据分辨率矩阵的狄利克雷展布。
同理,对于纯欠定情况,最小长度广义逆为:
G
−
g
=
G
T
[
G
G
T
]
−
1
\mathbf{G}^{-\mathbf{g}}=\mathbf{G}^{\mathrm{T}}\left[\mathbf{G} \mathbf{G}^{\mathrm{T}}\right]^{-1}
G−g=GT[GGT]−1
既可以看作是最小化 解的长度,也可以看作是最小化模型分辨率矩阵展布。
2.3 一般情况的狄利克雷展布展布函数
通过折中思想(正则化),可以通过最小化狄利克雷展布函数和协方差大小的加权求和来定义一个有意义的解:
最小化:
α
1
spread
(
N
)
+
α
2
spread
(
R
)
+
α
3
size
(
[
cov
u
m
]
)
\alpha_{1} \operatorname{spread}(\mathbf{N})+\alpha_{2} \operatorname{spread}(\mathbf{R})+\alpha_{3} \operatorname{size}\left(\left[\operatorname{cov}_{\mathbf{u}} \mathbf{m}\right]\right)
α1spread(N)+α2spread(R)+α3size([covum])
式中
α
\alpha
α为任意的权重因子。
通过对上式求解(略去求解过程),所得结果为一个广义逆方程:
α
1
[
G
T
G
]
G
−
g
+
G
−
g
[
α
2
[
G
G
T
]
+
α
3
[
cov
u
d
]
]
=
[
α
1
+
α
2
]
G
T
\alpha_{1}\left[\mathbf{G}^{\mathrm{T}} \mathbf{G}\right] \mathbf{G}^{-\mathrm{g}}+\mathbf{G}^{-\mathrm{g}}\left[\alpha_{2}\left[\mathbf{G} \mathbf{G}^{\mathrm{T}}\right]+\alpha_{3}\left[\operatorname{cov}_{\mathrm{u}} \mathbf{d}\right]\right]=\left[\alpha_{1}+\alpha_{2}\right] \mathbf{G}^{\mathrm{T}}
α1[GTG]G−g+G−g[α2[GGT]+α3[covud]]=[α1+α2]GT
这种形式的方程被称为西尔维斯特方程(Sylvester equation)。当指定权重因子的大小,可以求出该方程的显式解。
当
α
1
=
1
,
α
2
=
α
3
=
0
\alpha_1=1,\alpha_2=\alpha_3=0
α1=1,α2=α3=0时,对应最小二乘解
当
α
1
=
0
,
α
2
=
1
,
α
3
=
0
\alpha_1=0,\alpha_2=1,\alpha_3=0
α1=0,α2=1,α3=0时,对应最小长度解
当
α
1
=
1
,
α
2
=
0
,
α
3
=
ε
2
\alpha_1=1,\alpha_2=0,\alpha_3=\varepsilon^2
α1=1,α2=0,α3=ε2,且
[
c
o
v
u
d
]
=
I
[cov_u\mathbf{d}]=\mathbf{I}
[covud]=I,那么广义逆为:
G
−
g
=
[
G
T
G
+
ε
2
I
]
−
1
G
T
\mathbf{G}^{-g}=\left[\mathbf{G}^{\mathrm{T}} \mathbf{G}+\varepsilon^{2} \mathbf{I}\right]^{-1} \mathbf{G}^{\mathrm{T}}
G−g=[GTG+ε2I]−1GT
此为阻尼最小二乘的广义逆
当
α
1
=
0
,
α
2
=
1
,
α
3
=
ε
2
\alpha_1=0,\alpha_2=1,\alpha_3=\varepsilon^2
α1=0,α2=1,α3=ε2,且
[
c
o
v
u
d
]
=
I
[cov_u\mathbf{d}]=\mathbf{I}
[covud]=I时:
G
−
g
=
G
T
[
G
G
T
+
ε
2
I
]
−
1
\mathbf{G}^{-g}=\mathbf{G}^{\mathrm{T}}\left[\mathbf{G} \mathbf{G}^{\mathrm{T}}+\varepsilon^{2} \mathbf{I}\right]^{-1}
G−g=GT[GGT+ε2I]−1
为阻尼最小长度的广义逆
3 旁瓣和巴克斯-吉尔伯特展布函数
用狄利克雷展布函数来计算广义逆,通常会产生旁瓣(sidelobes),即在分辨率矩阵中远离主对角线处存在大幅值区域。 为此希望找到一种不产生旁瓣的广义逆,即使代价是加宽主对角线附近非零元素带的宽度,因为具有这种分辨率矩阵的解是可解释的,并被解释为物理上相邻的模型参数的局部平均。
巴克斯-吉尔伯特展布函数(Backus-Gilbert spreading function; Backus and Gilbert,1967,1968),由下式给出:
spread
(
R
)
=
∑
i
=
1
M
∑
j
=
1
M
w
(
i
,
j
)
[
R
i
j
−
δ
i
j
]
2
=
∑
i
=
1
M
∑
j
=
1
M
w
(
i
,
j
)
R
i
j
2
\operatorname{spread}(\mathbf{R})=\sum_{i=1}^{M} \sum_{j=1}^{M} w(i, j)\left[R_{i j}-\delta_{i j}\right]^{2}=\sum_{i=1}^{M} \sum_{j=1}^{M} w(i, j) R_{i j}^{2}
spread(R)=i=1∑Mj=1∑Mw(i,j)[Rij−δij]2=i=1∑Mj=1∑Mw(i,j)Rij2
对于数据分辨率展布,相似表达式同样成立。
有了新的展布函数,那么就可以推导新的广义逆。新的广义逆的旁瓣将比基于狄利克雷展布函数的广义逆更小,同时,它们在以用其他标准判定时有时会较差。
3.1 欠定问题的巴克斯-吉尔伯特广义逆
我们谋求特定的广义逆
G
−
g
\mathbf{G^{-g}}
G−g,它最小化了模型分辨率的巴克斯-吉尔伯特展布。由于没有给予模型分辨率的对角元素任何权重,我们需要得到的模型分辨率矩阵满足如下方程:
∑
j
=
1
M
R
i
j
=
[
1
]
i
\sum_{j=1}^{M} R_{i j}=[1]_{i}
j=1∑MRij=[1]i
这个约束保证了分辨率矩阵对角元素的大小是有限的,并且它的行是施加于真实模型参数的单位平均函数。
将分辨率矩阵的某个行的展布写为
J
k
J_k
Jk,并代入分辨率矩阵的表达式,我们有:
J
k
=
∑
l
=
1
M
w
(
l
,
k
)
R
k
l
R
k
l
=
∑
l
=
1
M
w
(
l
,
k
)
[
∑
i
=
1
N
G
k
i
−
g
G
i
l
]
[
∑
j
=
1
N
G
k
j
−
g
G
j
l
]
=
∑
i
=
1
N
∑
j
=
1
N
G
k
i
−
g
G
k
j
−
g
∑
l
=
1
M
w
(
l
,
k
)
G
i
l
G
j
l
=
∑
i
=
1
N
∑
j
=
1
N
G
k
i
−
g
G
k
j
−
g
S
i
j
(
k
)
\begin{aligned} J_{k} &=\sum_{l=1}^{M} w(l, k) R_{k l} R_{k l} \\ &=\sum_{l=1}^{M} w(l, k)\left[\sum_{i=1}^{N} G_{k i}^{-g} G_{i l}\right]\left[\sum_{j=1}^{N} G_{k j}^{-g} G_{j l}\right] \\ &=\sum_{i=1}^{N} \sum_{j=1}^{N} G_{k i}^{-g} G_{k j}^{-g} \sum_{l=1}^{M} w(l, k) G_{i l} G_{j l} \\ &=\sum_{i=1}^{N} \sum_{j=1}^{N} G_{k i}^{-g} G_{k j}^{-g} S_{i j}^{(k)} \end{aligned}
Jk=l=1∑Mw(l,k)RklRkl=l=1∑Mw(l,k)[i=1∑NGki−gGil][j=1∑NGkj−gGjl]=i=1∑Nj=1∑NGki−gGkj−gl=1∑Mw(l,k)GilGjl=i=1∑Nj=1∑NGki−gGkj−gSij(k)
其中,
S
i
j
(
k
)
S_{ij}^{(k)}
Sij(k)定义为:
S
i
j
(
k
)
=
∑
l
=
1
M
w
(
l
,
k
)
G
i
l
G
j
l
S_{i j}^{(k)}=\sum_{l=1}^{M} w(l, k) G_{i l} G_{j l}
Sij(k)=l=1∑Mw(l,k)GilGjl
约束方程
∑
j
R
i
j
=
[
1
]
i
\sum_j{R_{ij}}=[1]_i
∑jRij=[1]i的左边也可以写为广义逆的表达式,即
∑
k
=
1
M
R
i
k
=
∑
k
=
1
M
[
∑
j
=
1
N
G
i
j
−
g
G
j
k
]
=
∑
j
=
1
N
G
i
j
−
g
∑
k
=
1
M
G
j
k
=
∑
j
=
1
N
G
i
j
−
g
u
j
\sum_{k=1}^{M} R_{i k}=\sum_{k=1}^{M}\left[\sum_{j=1}^{N} G_{i j}^{-g} G_{j k}\right]=\sum_{j=1}^{N} G_{i j}^{-g} \sum_{k=1}^{M} G_{j k}=\sum_{j=1}^{N} G_{i j}^{-g} u_{j}
k=1∑MRik=k=1∑M[j=1∑NGij−gGjk]=j=1∑NGij−gk=1∑MGjk=j=1∑NGij−guj
其中,
u
j
u_j
uj定义为
u
j
=
∑
k
=
1
M
G
j
k
u_{j}=\sum_{k=1}^{M} G_{j k}
uj=k=1∑MGjk
关于广义逆元素最小化
J
k
J_k
Jk,(在给定约束条件下)可以使用拉格朗日乘数来求解。首先定义拉格朗日函数
Φ
\mathbf{\Phi}
Φ,表达为
Φ
=
∑
i
=
1
N
∑
j
=
1
M
G
k
i
−
g
G
k
j
−
g
S
i
j
(
k
)
+
2
λ
∑
j
=
1
N
G
k
j
−
g
u
j
\Phi=\sum_{i=1}^{N} \sum_{j=1}^{M} G_{k i}^{-g} G_{k j}^{-g} S_{i j}^{(k)}+2 \lambda \sum_{j=1}^{N} G_{k j}^{-g} u_{j}
Φ=i=1∑Nj=1∑MGki−gGkj−gSij(k)+2λj=1∑NGkj−guj
式中,
2
λ
2\lambda
2λ为拉格朗日乘数。
对关于广义逆的元素
Φ
\Phi
Φ求导,并让结果等于0,得到:
∂
Φ
∂
G
k
p
−
g
=
2
∑
i
=
1
N
S
p
i
(
k
)
G
k
i
−
g
+
2
λ
u
p
=
0
\frac{\partial \Phi}{\partial G_{k p}^{-g}}=2 \sum_{i=1}^{N} S_{p i}^{(k)} G_{k i}^{-g}+2 \lambda u_{p}=0
∂Gkp−g∂Φ=2i=1∑NSpi(k)Gki−g+2λup=0
该方程必须与原来的约束方程同时求解,取出
G
−
g
\mathbf{G^{-g}}
G−g的第
k
k
k行作为列向量
g
(
k
)
\mathbf{g^{(k)}}
g(k),并且将
S
i
j
(
k
)
\mathbf{S_{ij}^{(k)}}
Sij(k),我们可以将这些方程写为:
[
S
(
k
)
u
u
T
0
]
[
g
(
k
)
λ
]
=
[
O
1
]
\left[\begin{array}{ll} \mathbf{S}^{(k)} & \mathbf{u} \\ \mathbf{u}^{\mathrm{T}} & 0 \end{array}\right]\left[\begin{array}{l} \mathbf{g}^{(\mathrm{k})} \\ \lambda \end{array}\right]=\left[\begin{array}{l} \mathbf{O} \\ 1 \end{array}\right]
[S(k)uTu0][g(k)λ]=[O1]
将设上式中对称矩阵的逆矩阵是存在的,在此将其分割为一个
N
×
N
N \times N
N×N的对称方阵
A
\mathbf{A}
A、向量
b
\mathbf{b}
b和标量
c
c
c。使用上述假设,将对称矩阵左乘其逆矩阵产生单位矩阵:
[
A
b
b
T
c
]
[
S
(
k
)
u
u
T
0
]
=
[
I
O
0
1
]
=
[
A
S
(
k
)
+
b
u
T
A
u
b
T
S
(
k
)
+
c
u
T
b
T
u
]
\left[\begin{array}{ll} \mathbf{A} & \mathbf{b} \\ \mathbf{b}^{\mathrm{T}} & c \end{array}\right]\left[\begin{array}{ll} \mathbf{S}^{(\mathrm{k})} & \mathbf{u} \\ \mathbf{u}^{\mathrm{T}} & 0 \end{array}\right]=\left[\begin{array}{ll} \mathbf{I} & \mathbf{O} \\ 0 & 1 \end{array}\right]=\left[\begin{array}{ll} \mathbf{A} \mathbf{S}^{(\mathrm{k})}+\mathbf{b} \mathbf{u}^{\mathrm{T}} & \mathbf{A} \mathbf{u} \\ \mathbf{b}^{\mathrm{T}} \mathbf{S}^{(\mathrm{k})}+\mathbf{c u}^{\mathrm{T}} & \mathbf{b}^{\mathrm{T}} \mathbf{u} \end{array}\right]
[AbTbc][S(k)uTu0]=[I0O1]=[AS(k)+buTbTS(k)+cuTAubTu]
对于未知子矩阵
A
\mathbf{A}
A、向量
b
\mathbf{b}
b和标量
c
c
c可以让子矩阵相等来确定:
A
S
(
k
)
+
b
u
T
=
I
\mathbf{A S}^{(\mathbf{k})}+\mathbf{b u}^{\mathrm{T}}=\mathbf{I}
AS(k)+buT=I ==>
A
=
[
S
(
k
)
]
−
1
[
I
−
b
u
T
]
\mathbf{A}=\left[\mathbf{S}^{(\mathbf{k})}\right]^{-1}\left[\mathbf{I}-\mathbf{b u}^{\mathbf{T}}\right]
A=[S(k)]−1[I−buT]
A
u
=
O
\mathbf{A} \mathbf{u}=\mathbf{O}
Au=O ==>
[
S
(
k
)
]
−
1
u
=
b
u
T
S
(
k
)
u
\left[\mathbf{S}^{(\mathrm{k})}\right]^{-1} \mathbf{u}=\mathbf{b u}^{\mathrm{T}} \mathbf{S}^{(\mathrm{k})} \mathbf{u}
[S(k)]−1u=buTS(k)u 和
b
=
[
S
(
k
)
]
−
1
u
u
T
[
S
(
k
)
]
−
1
u
\mathbf{b}=\frac{\left[\mathbf{S}^{(\mathbf{k})}\right]^{-1} \mathbf{u}}{\mathbf{u}^{\mathrm{T}}\left[\mathbf{S}^{(\mathbf{k})}\right]^{-1} \mathbf{u}}
b=uT[S(k)]−1u[S(k)]−1u
b
T
S
(
k
)
+
c
u
T
=
0
\mathbf{b}^{\mathrm{T}} \mathbf{S}^{(\mathrm{k})}+c \mathbf{u}^{\mathrm{T}}=0
bTS(k)+cuT=0 ==>
c
=
−
1
u
T
[
S
(
k
)
]
−
1
u
c=\frac{-1}{\mathbf{u}^{\mathrm{T}}\left[\mathbf{S}^{(\mathrm{k})}\right]^{-1} \mathbf{u}}
c=uT[S(k)]−1u−1
将方程左乘对称逆矩阵得到
g
(
k
)
=
b
\mathbf{g^{(k)}=b}
g(k)=b和
λ
=
c
\mathbf{\lambda}=c
λ=c,由此,广义逆写为求和形式后为
G
k
l
−
g
=
∑
i
=
1
N
u
i
[
(
S
(
k
)
)
−
1
]
i
l
∑
i
=
1
N
∑
j
=
1
N
u
i
[
(
S
(
k
)
)
−
1
]
i
j
u
j
G_{k l}^{-g}=\frac{\sum_{i=1}^{N} u_{i}\left[\left(\mathbf{S}^{(k)}\right)^{-1}\right]_{i l}}{\sum_{i=1}^{N} \sum_{j=1}^{N} u_{i}\left[\left(\mathbf{S}^{(k)}\right)^{-1}\right]_{i j} u_{j}}
Gkl−g=∑i=1N∑j=1Nui[(S(k))−1]ijuj∑i=1Nui[(S(k))−1]il
这个广义逆的巴克斯-吉尔伯特公式可类比于最小长度解。
例子,下图为拉普拉斯变换问题的狄利克雷解和巴克斯-吉尔伯特解,图a为真实模型(红色)包含了一系列的尖刺。使用巴克斯-吉尔伯特展布函数估计的模型(蓝色)非常光滑,并且光滑的宽度随
z
z
z的增加而增大。图b为对应的模型分辨率矩阵
R
\mathbf{R}
R。图c和d与上述相同,但对应狄利克雷展布函数。注意,巴克斯-吉尔伯特分辨率矩阵具有较低强度的旁瓣,却有较宽的中心条带。
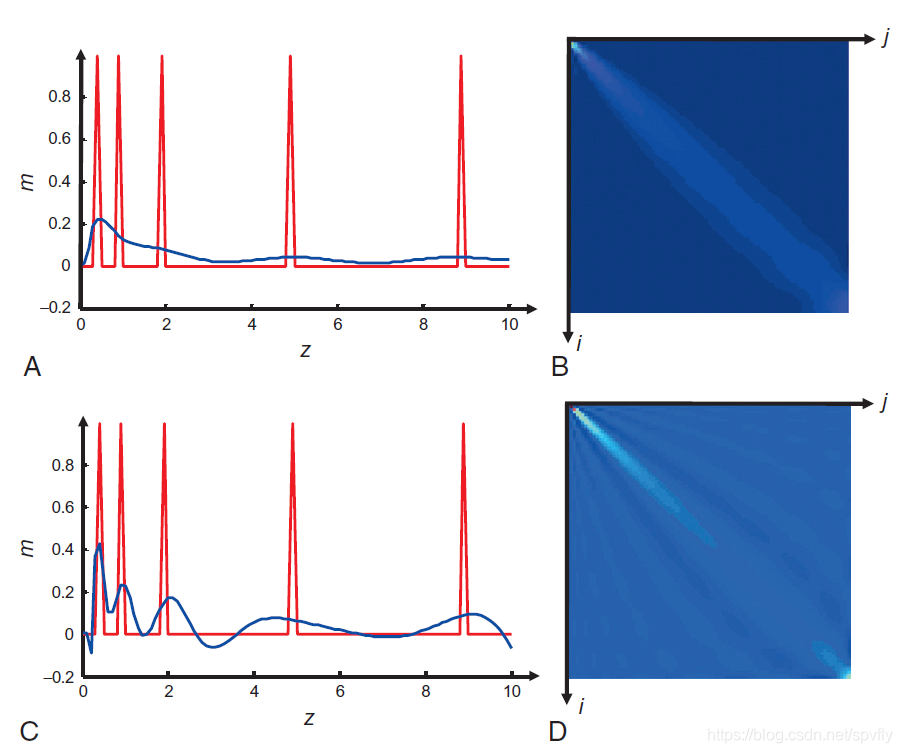
巴克斯-吉尔伯特解使两个解中较光滑的那个,且所对应的模型分辨率矩阵由一个沿主对角线的条带构成。狄利克雷解拥有更多的细节,但也拥有更多的假象(如在
z
≈
3
z \approx 3
z≈3处的负值)。它们与对应的模型分辨率矩阵中的大振幅旁瓣有关联。
3.2 引入协方差大小
α
spread
(
R
)
+
(
1
−
α
)
size
(
[
cov
u
m
]
)
=
α
∑
i
=
1
M
∑
j
=
1
M
w
(
i
,
j
)
R
i
j
2
+
(
1
−
α
)
∑
i
=
1
M
[
cov
u
m
]
i
i
\alpha \operatorname{spread}(\mathbf{R})+(1-\alpha) \operatorname{size}\left(\left[\operatorname{cov}_{\mathbf{u}} \mathbf{m}\right]\right)=\alpha \sum_{i=1}^{M} \sum_{j=1}^{M} w(i, j) R_{i j}^{2}+(1-\alpha) \sum_{i=1}^{M}\left[\operatorname{cov}_{u} \mathbf{m}\right]_{i i}
αspread(R)+(1−α)size([covum])=αi=1∑Mj=1∑Mw(i,j)Rij2+(1−α)i=1∑M[covum]ii
那么,第
k
k
k行的度量
J
k
′
J_{k}^{\prime}
Jk′是
J
k
′
=
α
∑
l
=
1
M
w
(
k
,
l
)
R
k
l
2
+
(
1
−
α
)
[
c
o
v
u
m
]
k
k
=
α
∑
i
=
1
N
∑
j
=
1
N
G
k
i
−
g
G
k
j
−
g
[
S
i
j
]
k
+
(
1
−
α
)
∑
i
=
1
N
∑
j
=
1
N
G
k
i
−
g
G
k
j
−
g
[
c
o
v
u
d
]
i
j
=
∑
i
=
1
N
∑
j
=
1
N
G
k
i
−
g
G
k
j
−
g
S
i
j
′
(
k
)
\begin{aligned} J_{k}^{\prime} &=\alpha \sum_{l=1}^{M} w(k, l) R_{k l}^{2}+(1-\alpha)\left[\mathrm{cov}_{\mathrm{u}} \mathbf{m}\right]_{k k} \\ &=\alpha \sum_{i=1}^{N} \sum_{j=1}^{N} G_{k i}^{-g} G_{k j}^{-g}\left[S_{i j}\right]_{k}+(1-\alpha) \sum_{i=1}^{N} \sum_{j=1}^{N} G_{k i}^{-g} G_{k j}^{-g}\left[\mathrm{cov}_{\mathrm{u}} \mathbf{d}\right]_{i j} \\ &=\sum_{i=1}^{N} \sum_{j=1}^{N} G_{k i}^{-g} G_{k j}^{-g} S_{i j}^{\prime(k)} \end{aligned}
Jk′=αl=1∑Mw(k,l)Rkl2+(1−α)[covum]kk=αi=1∑Nj=1∑NGki−gGkj−g[Sij]k+(1−α)i=1∑Nj=1∑NGki−gGkj−g[covud]ij=i=1∑Nj=1∑NGki−gGkj−gSij′(k)
其中,量
S
i
j
′
(
k
)
S_{ij}^{\prime(k)}
Sij′(k)由如下方程定义:
S
i
j
′
(
k
)
=
α
S
i
j
(
k
)
+
(
1
−
α
)
[
cov
u
d
]
i
j
S_{i j}^{\prime(k)}=\alpha S_{i j}^{(k)}+(1-\alpha)\left[\operatorname{cov}_{\mathrm{u}} \mathbf{d}\right]_{i j}
Sij′(k)=αSij(k)+(1−α)[covud]ij
最后,广义逆仅需要将前面结果中的
S
i
j
(
k
)
S_{ij}^{(k)}
Sij(k)替换
S
i
j
′
(
k
)
S_{ij}^{\prime(k)}
Sij′(k):
G
k
l
−
g
=
∑
i
=
1
N
u
i
[
(
S
′
(
k
)
)
−
1
]
i
l
∑
i
=
1
N
∑
j
=
1
N
u
i
[
(
S
′
(
k
)
)
−
1
]
i
j
u
j
G_{k l}^{-g}=\frac{\sum_{i=1}^{N} u_{i}\left[\left(\mathbf{S}^{\prime(k)}\right)^{-1}\right]_{i l}}{\sum_{i=1}^{N} \sum_{j=1}^{N} u_{i}\left[\left(\mathbf{S}^{\prime(k)}\right)^{-1}\right]_{i j} u_{j}}
Gkl−g=∑i=1N∑j=1Nui[(S′(k))−1]ijuj∑i=1Nui[(S′(k))−1]il
这个广义逆是类比于阻尼最小长度解的巴克斯-吉尔伯特广义逆。
4 分辨率和协方差的折中
如医学层析成像问题中的X射线不透明度(如下图),试图确定一系列的模型参数。
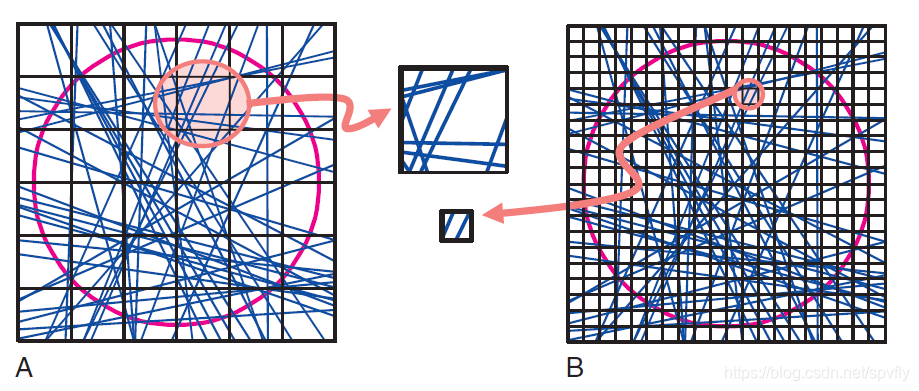
如果离散化模型的网络非常小(图B),那么X射线将难以把每个方格都采样到,这个问题是欠定的。如果我们要确定每一个方格的不透明度,因为很少有方格被多条X射线穿过,以致于几乎不会发生误差被平均掉的情况,那么不透明度的估计将具有相当大的方差。但由于格子较小,那么可以检测到很小的特诊。若方格较大(图A),大部分方格可以被多条X射线穿过,可以平均掉误差(噪声),大方差可以降低。但由于格子较大,小的特征不能被检测到,因此X射线不透明度的分辨率变得较差。
上如的例子,描述了模型分辨率与方差大小之间的一种重要折中。一个量的降低只能以另一个量的增加为代价。通过折中思想,最小化分辨率展布和方差大小的加权求和:
α
spread
(
R
)
+
(
1
−
α
)
size
(
[
cov
u
m
]
)
\alpha \operatorname{spread}(\mathbf{R})+(1-\alpha) \operatorname{size}\left(\left[\operatorname{cov}_{\mathbf{u}} \mathbf{m}\right]\right)
αspread(R)+(1−α)size([covum])
若
α
\alpha
α设定在1附近,那么广义逆的模型分辨率矩阵将拥有小的展布,但模型参数将拥有大方差。若
α
\alpha
α设定为接近0,那么模型参数将具有较小的方差,但模型分辨率矩阵将拥有较大的展布。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









