通过URL对象的openConnection()方法获得URLConnection对象 连接 URLConnection con = realUrl.openConnection();
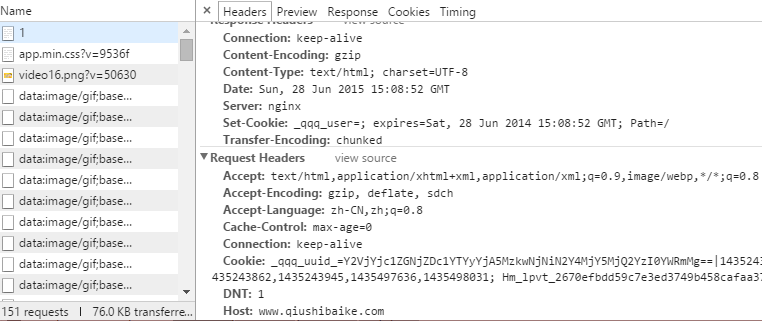
设置request头部参数,可从浏览器net中看到 con.setRequestProperty("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"); con.setRequestProperty("Accept-Language", "zh-CN,zh;q=0.8"); con.setRequestProperty("Connection", "keep-alive"); con.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36");
连接发送请求 con.connect();
通过URLConnection对象的getInputStream()方法获取响应网络流 ,并包装成BufferedReader带有缓冲区的字符流对象 in = new BufferedReader(new InputStreamReader(con.getInputStream()));
循环读取流拼接到result字符串中,返回result String line; while ((line = in.readLine()) != null) { result += "\n"+ line; } return result;
糗百的地址的规律 http://www.qiushibaike.com/text/page/后拼接页码,我们可以通过循环获取前10页的内容 String url = "http://www.qiushibaike.com/text/page/"; String html = ""; for (int i = 1; i <= 10; i++) { html += qiuShiBaiKe.sendGet(url+i, null); }























 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









