






目录
(3)通过hdfs_dfs命令可以查看下载文件命令的使用帮助。
导学与指南
Hadoop的HDFS(Hadoop Distributed File System)是一个高度容错性的系统,用于在大量计算机集群上存储大量的数据。HDFS的设计是为了存储超大数据集,提供高吞吐量的数据访问,并能在商用硬件上运行。
下面,我将提供一个简单的Java代码示例,用于在HDFS上进行基本的文件操作,并对其进行解析。
首先,确保你已经正确配置了Hadoop环境,并且Hadoop集群正在运行。然后,你可以使用Hadoop的Java API进行HDFS操作。
以下是一个简单的示例,用于在HDFS上创建一个文件,写入一些数据,然后读取并打印这些数据:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.io.IOUtils;
import java.io.BufferedWriter;
import java.io.OutputStreamWriter;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsExample {
public static void main(String[] args) throws Exception {
// 1. 创建Hadoop配置对象
Configuration conf = new Configuration();
// 设置HDFS的URI,这里是NameNode的地址
conf.set("fs.defaultFS", "hdfs://localhost:9000");
// 2. 获取FileSystem对象,这是与HDFS交互的主要接口
FileSystem fs = FileSystem.get(conf);
// 3. 创建一个新文件
Path filePath = new Path("/user/hadoop/test.txt");
FSDataOutputStream outputStream = fs.create(filePath);
// 4. 写入数据
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(outputStream, "UTF-8"));
writer.write("Hello, HDFS!");
writer.close();
// 5. 关闭输出流
outputStream.close();
// 6. 打开文件并读取数据
FSDataInputStream inputStream = fs.open(filePath);
IOUtils.copyBytes(inputStream, System.out, 4096, false);
// 7. 关闭输入流和文件系统对象
inputStream.close();
fs.close();
}
}任务背景
Hadoop框架的核心设计为HDFS和MapReduce,HDFS负责海量数据的存储,MapReduce则负责海量数据的计算。对海量数据进行计算前,数据的存储是必要的一步操作,因此,需要先掌握 HDFS分布式文件系统的基本操作。
某社交网站有数百万注册用户,网站的服务器上保留了用户登录网站的日志记录,用户每登录一次网站,将在日志文件中记录一次用户的邮件地址,现有一份社交网站在 2021年某一天的原始日志文件email_log.txt,共800万行记录,部分数据如下所示。

一、认识Hadoop安全模式
1.任务描述
- 安全模式是保证一个系统保密性、完整性及可使用性的一种机制,一定程度上可以防止系统里的资源遭到破坏、更改和泄露,安全模式可以使整个系统持续可靠地正常运行。
- Hadoop集群也有安全模式,在安全模式下可保证Hadoop集群中数据块的安全性。
2.了解Hadoop安全模式
Hadoop安全模式是一种在Hadoop集群中实现身份验证和授权的机制,旨在确保数据块的完整性和一致性,同时提供一种自检机制以检查集群状态并自动修复一些异常情况。以下是关于Hadoop安全模式的详细解释:
(1)目的与功能:
- 安全模式是HDFS(Hadoop Distributed File System)所处的一种特殊状态,其中文件系统仅接受读数据请求,而不接受删除、修改等变更请求。这种机制可以防止在恢复过程中发生数据的丢失或损坏。
- 当NameNode主节点启动时,HDFS首先进入安全模式。在此模式下,DataNode会向NameNode汇报其可用的block等状态。当整个系统达到安全标准时,HDFS会自动离开安全模式。
- 安全模式还提供了自检功能,用于检查集群状态。例如,在进入安全模式时,Hadoop会自动检查数据块的复制数量是否达到指定的最小值,如果未达到要求,Hadoop将自动进行数据块的复制操作,直到满足要求为止。
(2)身份验证与授权:
- Hadoop安全模式使用Kerberos认证协议来验证用户的身份。用户必须首先通过Kerberos认证获取有效的令牌,然后才能执行Hadoop命令。
- 通过访问控制列表(ACL),Hadoop可以授权用户对文件和目录的访问。这种精细的权限控制确保了数据的安全性。
(3)配置与使用:
- 在配置Hadoop安全模式时,需要设置Kerberos服务器,并配置Hadoop集群的各个节点和客户端,使其能够与Kerberos服务器进行安全通信。
- SSL(Secure Socket Layer)配置也是关键的一部分,它可以保护数据在传输过程中的安全性,防止数据被窃听和篡改。
- 在使用Hadoop安全模式时,用户需要通过Kerberos提供的票据进行身份认证,只有认证成功的用户才能访问Hadoop集群中的数据。
3.查看、解除与开启Hadoop安全模式
(1)查看安全模式
当启动Hadoop集群时,首先会进入安全模式,主要是为了检查系统中DataNode节点上的数据块数量和有效性。在Linux系统上启动Hadoop集群,启动完成后可以在本机的浏览器输入“http://master:9870”网址,查看HDFS的监控服务。

Summary模块下将提示安全模式信息,默认情况下刚开启集群时将自动开启安全模式,显示“Safe mode is ON”的信息,说明安全模式已启动。 衔接的信息为“The reported blocks 0 needs additional 1376 blocks to reach the threshold 0.9990 of total blocks 1378. The minimum number of live datanodes is not required. Safe mode will be turned off automatically once the thresholds have been reached.”,这说明报告的数据块数是0块,如果要达到总数据块1378中的0.9990 (即阈值)还需要额外的1376个数据块。不需要活动数据节点的最小数目,一旦达到阈值,即使用的数据块个数达到总数据块数量的99.9%,安全模式将自动关闭。
因为数据块还没有加载到阈值,所以集群处于安全模式。等待一段时间,再次刷新网页,查看安全模式情况,将发现出现了“Safemode is off”信息,表示安全模式已自动关闭。
除了在Web端查看安全模式状态外,还可以在Liunx终端使用“hdfs dfsadmin -safemode get”命令查看。

(2)解除和开启安全模式
当启动Hadoop集群时集群会开启安全模式,原因是DataNode的数据块数没有达到总块数的阈值。如果没有先关闭Hadoop集群时,而直接关闭了虚拟机,那么Hadoop集群也会进入安全模式,保护系统。当再次开启Hadoop集群时,系统会一直处于安全模式不会自动解除,这时使用“hdfs dfsadmin -safemode leave”令可以解除安全模式。
[root@master ~]# hdfs dfsadmin -safemode leave
Safe mode is OFF
使用“hdfs dfsadmin -safemode enter”命令则可以使集群进入安全模式。在安全模式中,用户只能读取HDFS上的数据,不能进行增加、修改等变更请求。 例如,使用“hdfs dfs -mkdir /Hadoop”命令,在HDFS上创建一个/Hadoop目录,系统将会提示集群处于安全模式,不能创建/Hadoop目录
[root@master ~]# hdfs dfsadmin -safemode enter
Safe mode is ON
[root@master ~]# hdfs dfs -mkdir /Hadoop
mkdir: Cannot create directory /Hadoop. Name node is in safe mode.
二、查看Hadoop集群的基本信息
1.任务描述
Hadoop集群有两大核心功能,即分布式存储与并行计算。
在向Hadoop集群提交任务前,需要先了解集群的存储资源与计算资源。
- Hadoop集群的数据存储,是通过HDFS实现的。HDFS分布式文件系统是由一个NameNode节点与多个DataNode节点组成的。查看HDFS文件系统的信息有两种方式,分别是命令行方式与浏览器方式。
- Hadoop集群的计算资源也是分布在集群的各个节点上的,通过ResourceManager与NodeManager协同调配。一般可以通过浏览器访问ResourceManager的监控服务端口查询Hadoop集群的计算资源。
2.查询集群的存储系统信息
要查询Hadoop集群的存储系统信息,你可以通过几种不同的方法来实现。以下是一些常用的方法:
使用Hadoop自带的Web界面
Hadoop提供了一个Web界面,你可以通过浏览器访问这个界面来查看集群的各种信息,包括存储系统信息。默认情况下,你可以在
http://<namenode_hostname>:50070/上访问Hadoop集群的NameNode的Web界面。在这个界面上,你可以查看集群的整体状态、文件系统信息、节点健康状况等。使用Hadoop命令行工具
Hadoop提供了一些命令行工具,你可以使用这些工具来查询集群的存储系统信息。例如,你可以使用
hdfs dfsadmin -report命令来查看HDFS的存储状态。这个命令会显示HDFS集群的健康状况、容量信息、数据块分布等。查看配置文件
你还可以查看Hadoop的配置文件,如
hdfs-site.xml,以获取存储系统的配置信息。这些配置文件通常包含有关HDFS块大小、复制因子、数据目录等重要参数的设置。使用第三方管理工具
除了Hadoop自带的工具外,还有一些第三方管理工具可以帮助你查看和监控Hadoop集群的状态,包括存储系统信息。例如,Ambari和Cloudera Manager等工具提供了丰富的监控和管理功能,可以方便地查看集群的状态和性能指标。
注意事项
- 确保你有足够的权限来访问和查看集群的存储系统信息。
- 根据你的Hadoop版本和集群配置,具体的命令和界面可能会有所不同。因此,建议查阅你所使用的Hadoop版本的官方文档以获取最准确的信息。
- 如果集群规模较大或配置较复杂,建议使用专业的监控和管理工具来更全面地了解集群的状态和性能。
通过以上方法,你应该能够方便地查询Hadoop集群的存储系统信息,以便更好地管理和优化你的集群。
3.查询集群的计算资源信息
要查询Hadoop集群的计算资源信息,你可以采取以下几种方法:
使用Hadoop自带的Web界面
Hadoop提供了NameNode和ResourceManager的Web界面,你可以通过浏览器访问这些界面来查看集群的计算资源信息。通常,NameNode的Web界面地址是
http://<namenode_hostname>:50070/,而ResourceManager的Web界面地址是http://<resourcemanager_hostname>:8088/。在ResourceManager的Web界面上,你可以查看集群中各个节点的计算资源使用情况,包括CPU使用率、内存使用率、任务执行情况等。这些信息有助于你了解集群的负载情况和资源分配情况。
使用Hadoop命令行工具
Hadoop还提供了一些命令行工具,你可以使用这些工具来查询集群的计算资源信息。例如,
yarn node -list命令可以列出集群中所有节点的状态和资源使用情况。查看配置文件
Hadoop的配置文件中也包含了关于计算资源的配置信息。你可以查看
yarn-site.xml等配置文件,了解集群的计算资源分配策略、最大容器大小等参数。使用第三方管理工具
除了Hadoop自带的工具外,你还可以使用第三方管理工具来查询和监控Hadoop集群的计算资源信息。这些工具通常提供了更丰富的功能和更直观的界面,方便你进行集群管理和资源优化。
注意事项
- 确保你有足够的权限来访问和查看集群的计算资源信息。
- 根据你的Hadoop版本和集群配置,具体的命令和界面可能会有所不同。因此,建议查阅你所使用的Hadoop版本的官方文档以获取最准确的信息。
- 集群的计算资源信息会实时变化,因此建议定期查看和分析这些信息,以便更好地管理和优化你的集群。
通过以上方法,你应该能够方便地查询Hadoop集群的计算资源信息,从而更好地了解集群的负载情况和资源分配情况,为集群的优化和管理提供有力支持。
4.了解分布文件系统——HDFS
| Active Nodes | 表示在线的计算节点,目前为3个。 |
| Memory Total | 表示可使用的内存总量,目前为6GB。 |
| Vcores Total | 表示可使用的CPU核心,目前共有3个。 |
| Rack | 表示机架名称,默认机架名为default-rack。 |
| Node Address | 表示计算节点的名称及端口。 |
| Containers | 表示执行计算任务的容器数量,无任务时值为0。 |
| Mem Used 与Mem Avail | 表示实际内存使用数量与可用内存的数量。 |
| VCores Used 与VCores Avail | 表示实际CPU核心使用数量与可用CPU核心的数量。 |
三、上传文件到HDFS目录
1.任务描述
HDFS是Hadoop的核心组件之一,负责文件数据的存储。
2.了解HDFS文件系统
文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。具体地说,HDFS文件系统负责为用户创建、写入、读出、修改和转储文件,当用户不再使用时删除文件等。
- Windows操作系统——安装于大部分个人计算机中,使用者将文件存储在磁盘驱动器(如D盘、E盘)的目录中。
- Linux操作系统——在大部分企业服务器中,更多的是使用此操作系统,Linux文件系统以及类Linux的文件系统均提供了树状的文件目录结构,可以供使用者存储或读取文件。
Hadoop集群也有专有的文件系统,即HDFS,HDFS也使用了类Linux的目录结构进行文件存储。以安装及配置的Hadoop集群为例,介绍HDFS与本地计算机的文件系统、Linux本地的文件系统之间的关系。
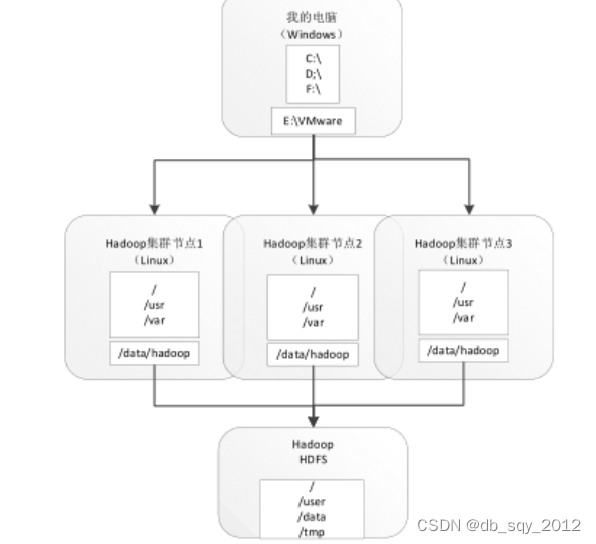
在使用HDFS文件系统前,需要对HDFS所存储的内容有一定的了解,可以通过浏览HDFS目录结构与文件列表进行查看。 在本地计浏览器的地址栏输入“http://master:9870”网址,远程访问HDFS的监控服务端口。当需要访问HDFS上的目录及文件时,可以单击网页的“Utilities ”标签栏,在下拉选项中选择“Browse the file system ”选项。

与Linux文件系统相似,根目录“/”是HDFS所有目录的起始点。 HDFS的根目录“/”下的目录列表。 继续单击图中的“test”超链接,将可以浏览/test目录下的内容。图中显示了HDFS的/test目录下的列表,此目录下有一个文件1.txt。以此类推,可以通过单击界面上的目录链接,浏览更多的子目录。 继续单击图中的文件“1.txt”超链接,在弹出的新窗口中单击“Head the file(first 32K)”选项,将在窗口下方出现“File contents”文本显示框,显示文件前32KB的内容。

假定已有数据文件data.txt,存储在本地计算机(Windows系统)的E盘中,现需要将该数据文件上传至HDFS的/user/root/目录下,常用的解决方法如下。 文件上传的操作流程如下,分为两步。 在本地计算机中使用SSH或FTP工具上传文件至Linux本地的目录(master节点),如/root/hadoop/目录。 在master节点终端,使用HDFS命令,上传文件至HDFS的/user/root/目录下。 同理,也可以通过逆向操作进行文件的下载,即将HDFS上的文件下载至本地计算机中。

3.掌握HDFS的基本操作
(1)创建目录
在集群服务器的终端,输入“hdfs dfs”命令,按“Enter ”键回车后即可看到HDFS基础操作命令的使用帮助。 “[-mkdir [-p] <path>...] ”的命令可用于创建目录,参数<path>用以指定创建的新目录。在HDFS中创建/user/dfstest目录,查看在HDFS文件目录/user/下的文件列表,可查看到新创建的目录。 “hdfs dfs -mkdir <path>”的命令只能逐级地创建目录,如果父目录不存在,那么使用该命令将会报错。若加上参数“-p”,则可以同时创建多级目录。

(2)上传与下载文件
创建了新目录/user/dfstest后,即可向该目录上传文件。通过hdfs_dfs命令查看上传文件命令的使用帮助。
| 命 令 | 解 释 |
| hdfs dfs [-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] | 将文件从本地文件系统复制到HDFS文件系统,主要参数<localsrc>为本地文件路径,<dst>为复制的目标路径 |
| hdfs dfs [-moveFromLocal <localsrc> ... <dst>] | 将文件从本地文件系统移动到HDFS文件系统,主要参数<localsrc>为本地文件路径,<dst>为移动的目标路径 |
| hdfs dfs [-moveFromLocal <localsrc> ... <dst>] | 将文件从本地文件系统上传到HDFS文件系统,主要参数<localsrc>为本地文件路径,<dst>为上传的目标路径 |
(3)通过hdfs_dfs命令可以查看下载文件命令的使用帮助。
| 命令 | 解释 |
| hdfs dfs [-copyToLocal [-p] [-ignoreCrc] [-crc] <src>... <localdst>] | 将文件从HDFS文件系统复制到本地文件系统,主要参数<src>为HDFS文件系统路径,<localdst>为本地文件系统路径 |
| hdfs dfs [-get [-p] [-ignoreCrc] [-crc] <src>...<localdst>] | 获取HDFS文件系统上指定路径的文件到本地文件系统,主要参数<src>为HDFS文件系统路径,<localdst>为本地文件系统路径 |
(4)查看文件内容
当用户想查看某个文件内容时,可以直接使用HDFS命令。HDFS提供了两种查看文件内容的命令。
| 命令 | 解释 |
| hdfs dfs [-cat [-ignoreCrc] <src> ...] | 查看HDFS文件内容,主要参数<src>指定文件路径 |
| hdfs dfs [-tail [-f] <file>] | 输出HDFS文件最后1024字节,主要参数<file>指定文件 |
(5)删除文件或目录
当HDFS上的某个文件或目录被确认不再需要时,可以选择删除,释放HDFS的存储空间。在HDFS的命令帮助文档中,HDFS主要提供了两种删除文件或目录的命令。
| 命令 | 解释 |
| hdfs dfs [-rm [-f] [-r|-R] [-skipTrash] <src> ...] | 删除HDFS上的文件,主要参数-r用于递归删除,<src>指定删除文件的路径 |
| hdfs dfs [-rmdir [--ignore-fail-on-non-empty] <dir> ...] | 若删除的是一个目录,则可以用该方法,主要参数<dir>指定目录路径 |
四、小结
首先介绍了Hadoop的安全模式,了解Hadoop安全模式的机制和作用,掌握Hadoop安全模式的查看、解除和开启。
接着结合实际任务及多个示例,介绍Hadoop集群的文件系统与计算资源信息的查询。
再重点介绍了Hadoop的HDFS文件系统的基本操作。














 2192
2192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









