







一、Zookeeper的作用:
1、ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现。 分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协 调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列 等功能。
2、个人对于zk的理解:我个人觉得zk就像一个很大的数据库,保存了很多数据,比如后面的kafka中的offset,就是保存在zk中的,就像一个很大的数据库。
3、数据同步的端口:2888,也就是Leader和Follower交换信息的端口;选举机制端口:3888。
二、Zookeeper的选举机制:
1、假设有五台机器,ID为1-5,它们同时启动,都没有历史纪录,在存放数据量这一点,都是一样的,那么ID为1的启动,只有它一台启动,它发出的信息没有得到回复,所以一直处于Looking状态。
2、服务器ID为2的启动,它与最开始启动的服务器ID为1的通信,互相交换自己的选举结果,由于两者都没有历史数据,所以ID较大的服务器胜出,但是由于没有达到超过半数以上的服务器同意选举它,所以它们都处于Looking状态。
3、服务器ID为3的启动,根据和前面一样的理论,这个服务器成了集群的leader。
4、服务器ID为4的启动,理应这个服务器应该成为1,2,3,4中最大的,但是由于前面半数的服务器选举服务器ID为3的,所以它成为Follower。
5、服务器ID为5的也成为Follower。
ps:如果启动的顺序是5,4,3,2,1,那么ID为5的会成为Leader。如果挂了一台,还剩四台机器,那么会按照顺序启动,然后再比较事务ID。
三、Client对于Zookeeper的ServerList的轮询机制:
1、客户端在初始化zk的过程中,将所有的Server保存在一个List中,然后随机打散,形成一个环,之后从0号位一个一个开始使用。在配置地址的时候,Server地址能够重复使用,这样的目的是弥补客户端无法设置Server权重的缺陷。
2、连接异常:①ConnectionLoss。②SessionExpired
3、客户端修改了某一个节点上的数据,其他客户端能够马上获取到最新数据吗?不能确保任何客户端都能够获取到,方法在客户端获取之前调用了sync。如果客户端A对于数据进行了修改,如果客户端B获取数据,想要获取修改后的数据,应该先调用sync方法,然后再getData。
四、Zookeeper对节点的watch:
1、对节点的watch是永久的吗?不是,因为一个watch是一个事件,当设置了watch的数据发生了改变的时候,则服务器将这个改变发送给设置watch的客户端。
2、watch通知是一次性的,必须重复注册。
3、发生ConnectionLoss的时候,如果Session_timeout之内再次连接上(即不发生SessionExpired),那么这个连接注册的watch依旧存在。
4、对于某个节点注册了watch,如果该节点删除了,那么watch也会删除。
5、同一个zk客户端对某一节点注册相同的watch,只会收到一次通知。
6、watcher对象只会保存在客户端,不会传递到服务端。
7、创建临时节点,连接断开之后,zk不会马上移除临时数据,只有当SessionExpired之后,才会把这个会话建立的临时数据删除。
五、Zookeeper注意事项:
1、zk对于动态扩容支持不是特别好,实现动态扩容的两种方式:①关闭zk服务,修改配置后启动。②逐个启动。
2、zk中集群的通信:leader服务器会和follower/observer服务器建立TCP通信,同时为每个F/O都创建一个叫做LearderHandler的实体,LearderHandler主要负责Leader和F/O之间的网络通讯,包括数据的同步,请求转发和投票等,Leader服务器保存了所有的F/O的LeaderHandler。
3、zk不会自动清理日志。
4、zk作为一个分布式的服务框架,主要解决分布式集群中应用系统的一致性问题。ZooKeeper提供的服务包括:分布式消息同步和协调机制、服务器节点动态上下线、统一配置管理、负载均衡、集群管理等。
ps:zk类似于linux中的目录节点树方式的数据存储,即分层命名空间,zk并不是专门存储数据的,它的作用是主要是维护和监控存储数据的状态变化,通过监控这些数据状态的变化,从而可以达到基于数据的集群管理,zk中的杰点的数据上限时1M。
5、zk的数据结构,每一个子目录都成为一个znode,znode可以有子节点目录,每一个znode可以存储数据。但是Ephemeral类型的目录节点类型的目录节点不能有子节点目录。znode是有版本。znode可以是临时节点。znode目录名可以自动编号。znode可以被监控(这是核心,zk很多功能都是靠这个实现的)。
6、zk节点的类型:
1)、znode有短暂性(ephemeral)和持久性(persistent),短暂性的客户端和服务端断开连接后,创建的节点自动删除,持久性的断开连接不会自动删除。
2)、znode有四种形式的目录节点:(1)、持久化目录节点。(2)、持久化顺序编号目录节点。(3)、临时目录节点。(4)、临时顺序编号目录节点。
7、zk的通知机制:
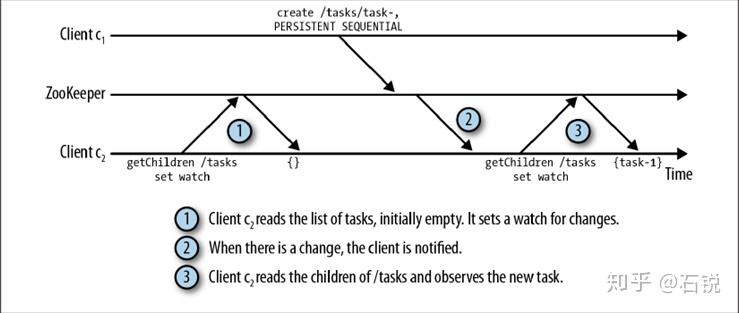
zk选择了基于通知的机制:即客户端向zk注册需要接收通知的znode,通知znode设置监控点来接收通知,监控点是单次触发,即触发点触发一个通知,为了接受多个通知,客户端必须在每次通知后设置一个新的监视点。
8、zk的监控原理:

main方法会创建zkClient,在创建zkClient的时候,会创建出listener进程和connect进程。一个是监控进程一个是网络连接进程。当zkClient调用getChildren等方法注册监听器的时候,connect进程向zk注册监听器,注册后的缉监听器位于zk的监听器列表中,监听器列表中记录了zkClient的ip地址,端口号,要监控的目录,一旦目标文件发生了改变,zk就会把这条消息发送给对应的zkClient的listener进程,listener进程接受到后,就会执行process方法。在process方法中针对发生的事件进行处理。
9、集群中最少要有3台机器(2N+1),保证机器数量时奇数。
10、集群有三台机器,挂了一台,也能够运行,只要保证存活的机器数大于一集群总数的一半就行了。
11、zk中的使用的ZAB协议与Paxo算法:
①相同之处:都有一个leader,用来协调N哥follower的运行;leader要等待超半数的follower做出正确反馈后才进行提案;二者都有一个值来代表leader周期。
②不同之处:ZAB用来构造高可用的分布式数据主备系统,Paxo是用来构造分布式一致性状态机系统。
12、zk对于事务的支持:
(1)、对于事务的支持主要依赖四个函数:zoo_create_op_init,zoo_delete_op_init,zoo_set_op_init以及zoo_check_op_init,每一个函数都会在客户端初始化一个operation,客户端有义务保留这些operation,当准备好一个事务中的所有操作的时候,可以使用zoo_multi来提交所有的操作。由zk服务来保证这一系列操作的原子性。
更多文章见:
















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









