







TF模型优化
一、TF模型优化概述
1. 为什么要优化?
- Reducing latency and cost for inference for both cloud and edge devices (e.g. mobile, IoT).
- Deploying models on edge devices with restrictions on processing, memory and/or power-consumption.
- Reducing payload size for over-the-air model updates.
- Enabling execution on hardware restricted-to or optimized-for fixed-point operations.
- Optimizing models for special purpose hardware accelerators.
2. 主要方法
1)Quantization
Quantized models are those where we represent the models with lower precision, such as 8-bit integers as opposed to 32-bit float. Lower precision is a requirement to leverage certain hardware.
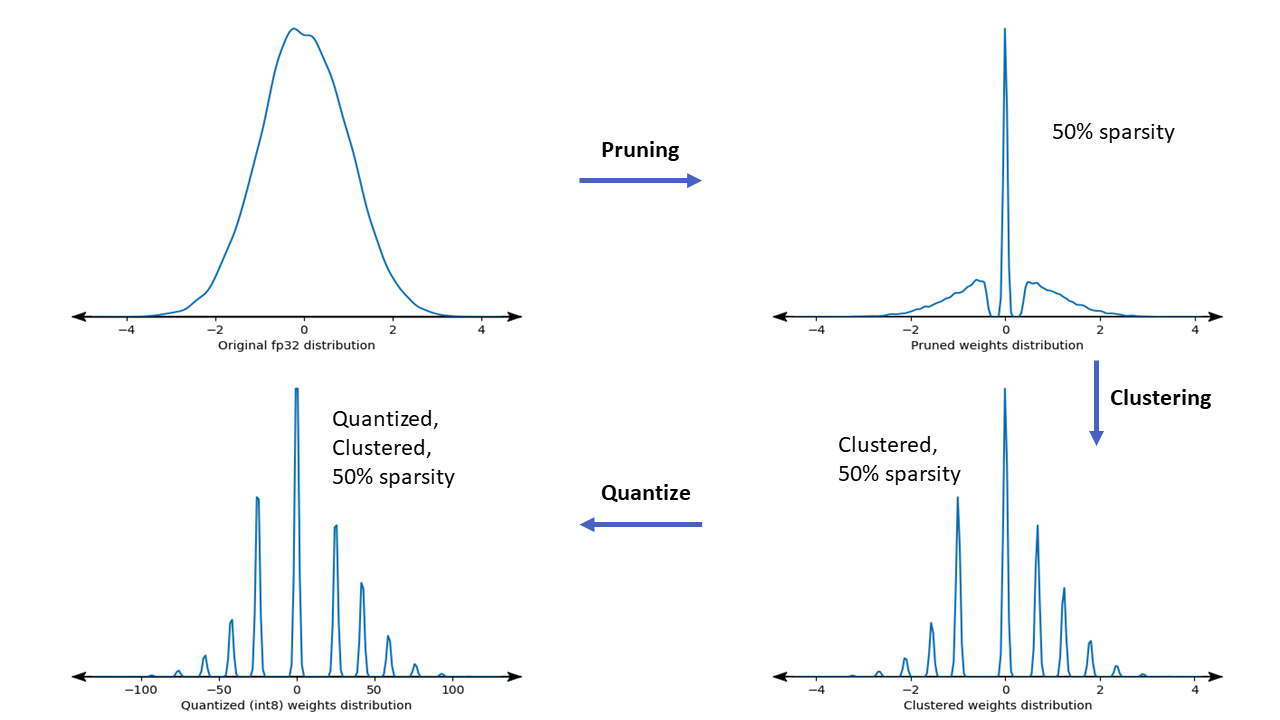
2) Sparsity and pruning
Sparse models are those where connections in between operators (i.e. neural network layers) have been pruned, introducing zeros to the parameter tensors.
3) Clustering
Clustered models are those where the original model’s parameters are replaced with a smaller number of unique values.
4) Collaborative optimization
This enables you to benefit from combining several model compression techniques and simultaneously achieve improved accuracy through quantization aware training.
二、Weight Pruning
1. Trim insignificant weights (修剪无关紧要的权重)
权重修剪在训练过程中逐渐将模型权重归零,以实现模型稀疏性。 稀疏模型更容易压缩,我们可以在推理过程中跳过零值以改善延迟。
三、Quantization
1. Quantization aware training
-
理论论文:uantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
-
使用方法:方法
2. Post-training quantization
四、Weight Clustering
Clustering, or weight sharing, reduces the number of unique weight values in a model, leading to benefits for deployment. It first groups the weights of each layer into N clusters, then shares the cluster’s centroid value for all the weights belonging to the cluster.
This technique brings improvements via model compression. Future framework support can unlock memory footprint improvements that can make a crucial difference for deploying deep learning models on embedded systems with limited resources.
- 理论论文:Deep Compression: Compressing Deep Neural Networks With Pruning, Trained Quantization and Huffman Coding
- 使用方法:方法
五、Collaborative Optimization
Collaborative optimization is an overarching process that encompasses various techniques to produce a model that, at deployment, exhibits the best balance of target characteristics such as inference speed, model size and accuracy.
The idea of collaborative optimizations is to build on individual techniques by applying them one after another to achieve the accumulated optimization effect. Various combinations of the following optimizations are possible:

 - 使用方法:方法
- 使用方法:方法















 1245
1245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









