







 文章探讨了LatentDiffusion模型中编码器的多对一问题导致的细节恢复不足,介绍了PSLD模型通过引入惩罚项来确保反向过程按预期进行,解决了人脸特征等问题。同时提及了类似算法如LDIR和STSL作为补充。
文章探讨了LatentDiffusion模型中编码器的多对一问题导致的细节恢复不足,介绍了PSLD模型通过引入惩罚项来确保反向过程按预期进行,解决了人脸特征等问题。同时提及了类似算法如LDIR和STSL作为补充。
前言
Latent Diffusion是在潜在空间进行扩散操作的模型,我们都知道在Latent Diffusion中有一个Autoencoder自编码器,它被用于将输入图片映射到潜在空间并将处理后的潜在信息返回到图像域,但在编码的过程中,由于编码器是实现多对一的映射,例如:多个不同的中年男性都被映射成相同的latenti空间的信息。
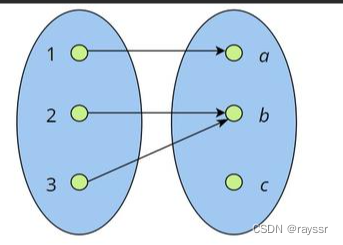
在上图中,1和a是一对一的关系,而2,3和b是多对一 的关系,因为这种情况,在反向过程中,图像的生成路径就不止一条。如果我们输入的信息是2,在潜在空间中呗映射成b,在反向过程中由b可以一步步生成2,也可以一步步生成3,所以在应用Latent Diffusion进行去噪去模糊的工作时,会发现在细节部分(例如人脸的特征)不能很好的接近ground truth。针对这一问题PSLD对模型进行了改动,通过惩罚不是encoder和decoder固定点的恢复路径来保证在其按照我们希望的方向进行恢复。
PSLD
我们都知道,在像素域的操作中使用前向随机微分方程和反向随机微分方程,分别为:![]()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









