







CVPR2019:Domain-Specific Batch Normalization for Unsupervised Domain Adaptation无监督域适配的特定域批处理规范化
0.摘要
我们在深度神经网络中提出了一种新的基于领域特定批归一化的无监督领域自适应框架。我们的目标是通过在卷积-卷积神经网络中专门化批归一化层,同时允许它们共享所有其他模型参数,从而适应这两种领域,这是通过两阶段算法实现的。在第一阶段,我们使用外部无监督域自适应算法(例如ample, MSTN[27]或CPUA[14])来估计目标域中示例的伪标签,该算法集成了提出的特定于域的批处理归一化。第二阶段使用源和目标域的多任务分类损失学习最终模型。注意,两个域在两个阶段都有单独的批处理规范化层。我们的框架可以很容易地整合到基于深度神经网络的领域自适应技术中,该技术具有批处理归一化层。我们还提出,我们的方法可以扩展到多源域的问题。该算法在多个基准数据集上进行了评估,在标准设置和多源域适应场景中达到了最先进的精度。
1.概述
无监督域适应是一种学习框架,它将从具有大量带注释的训练示例的源域学到的知识转移到只有无标记数据的目标域。由于域迁移问题,即源数据集和目标数据集具有不同的特征,这一任务具有挑战性。领域的转移在现实问题中是常见的,在训练过的模型的广泛应用中应该小心处理。无监督域自适应的目的是学习处理该问题的鲁棒模型,目前正变得流行,因为它可以拯救依赖于多样性和多样性有限的数据集的视觉识别任务
近年来无监督域适应研究的进展得益于深度神经网络的成功。采用具有适当损失函数的深度神经网络对基于浅学习的传统域适应技术进行了改进。深度网络强大的表示能力重新证明了以往方法的有效性,促进了全新算法的发展。基于深度神经网络的无监督域自适应有大量研究[3,4,10,14,23,27,30],近年来我们见证了显著的性能改进。
许多现有的无监督领域适应技术[3,4,14,23,27]的缺点之一是源域和目标域共享整个网络进行训练和预测。两个领域之间的共享组件是不可避免的,因为这两个领域有一些共同的东西;我们常常需要依靠源域的信息来学习适应于未标记的目标域数据的网络。然而,我们相信通过将领域特定信息与领域不变信息分离可以获得更好的泛化性能,因为这两个领域明显具有不同的特征,并且在单一模型中不兼容。
为了分离领域特定信息进行非监督领域适应,我们提出了一种新的深度神经网络构建块,称为领域特定批处理归一化(DSBN)。DSBN层由批处理归一化(BN)的两个分支组成,每个分支专门负责一个域。DSBN使用BN参数捕获特定于领域的信息,并使用参数将特定于领域的数据转换为领域不变表示。由于这种思想是通用的,DSBN普遍适用于各种具有BN层的无监督域适应的深度神经网络。此外,它可以很容易地扩展到多源域适应场景
在此基础上,我们提出了一种基于DSBN的两阶段无监督域自适应框架,即我们的网络首先生成目标域中无标签数据的伪标签,然后使用伪标签学习一个完全监督模型。具体地说,第一个阶段通过现有的包含DSBN的无监督域适应网络估计目标域数据的初始伪标签。在第二阶段,利用源域和目标域的数据在完全监督下训练具有DSBN层的多任务分类网络,其中第一阶段生成的伪标签分配到目标域数据。为了进一步提高准确率,我们迭代第二阶段的训练,并对目标域中的示例的标签进行再细化。我们的主要贡献总结如下:
- 我们提出了一种新的基于DSBN的无监督域适应框架,它是一种适用于各种深度神经网络模型的域适应通用方法。
- 我们引入了一种两阶段学习方法DSBN,包括伪标签估计和多任务分类,它自然集成到现有的无监督领域适应方法中。
- 我们的框架通过其直接的扩展为多源非监督域适应提供了原则性算法。
- 通过将我们的框架与两种最新的领域适应技术集成,我们在包括Office-31和VisDA-C数据集在内的标准基准上实现了最先进的性能。
2.预备知识
在无监督域自适应中,我们给出两个数据集:XS用于标记源域,XT用于标记目标域,其中nS和nT分别表示XS和XT的基数。我们的目标是在完全监督的基础上,通过转移从源领域学到的分类知识来对目标领域中的示例进行分类。本节将详细讨论两种用于集成特定领域批处理规范化技术的最新方法。
2.1.移动语义传输网络(Moving Semantic Transfer Network)
基于未标记目标域样本的伪标签,MSTN[27]提出了一种语义匹配损失函数来跨域对齐相同类的质心。整体损函数的形式定义由下式给出
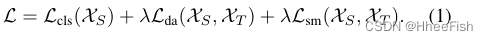
分类损失Lcls(XS)是源数据集的交叉熵损失,域对抗损失Lda使得网络混淆了域成员,如[3]中讨论的一个例子。语义匹配损失对齐了跨域的同一类的质心。注意,应该估计伪标签来计算语义匹配损失。直观上,Eq(1)损失函数鼓励两个域具有相同的分布,特别是通过添加对抗性和语义匹配损失项。因此,基于损失函数的学习网络可以应用于目标域的实例。
2.2.类预测不确定性对齐(Class Prediction Uncertainty Alignment)
CPUA[14]是一种非常简单的方法,它只在域之间排列类概率。CPUA 在这两个领域解决了类不平衡问题,并引入了类加权损失函数来利用类先验。
记pS© =ncS/ nS为源样本中具有类标签c的比例,且P~T© =ncT/ nT为目标样本中具有伪标签c的比例。ncT代表{x∈XT|y~(x) =c}的基数,其中,y~(x) = argmaxi∈CF(x)[i]。每个域的类权值分别为

它们的总损失函数可以写成
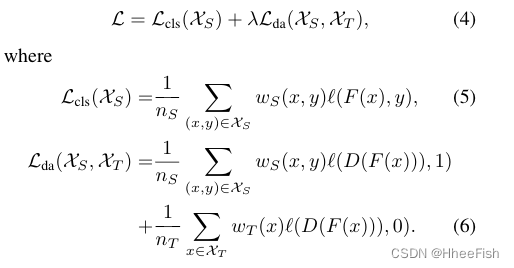
注意f(·)是一个分类网络,ℓ(·,·)表示交叉熵损失,d(·)是一个域鉴别器
3.领域特定批规范化(Domain-Specific Batch Normalization)
本节简要回顾批处理规范化(BN)与DSBN的比较,然后介绍DSBN及其用于多源域适应的扩展
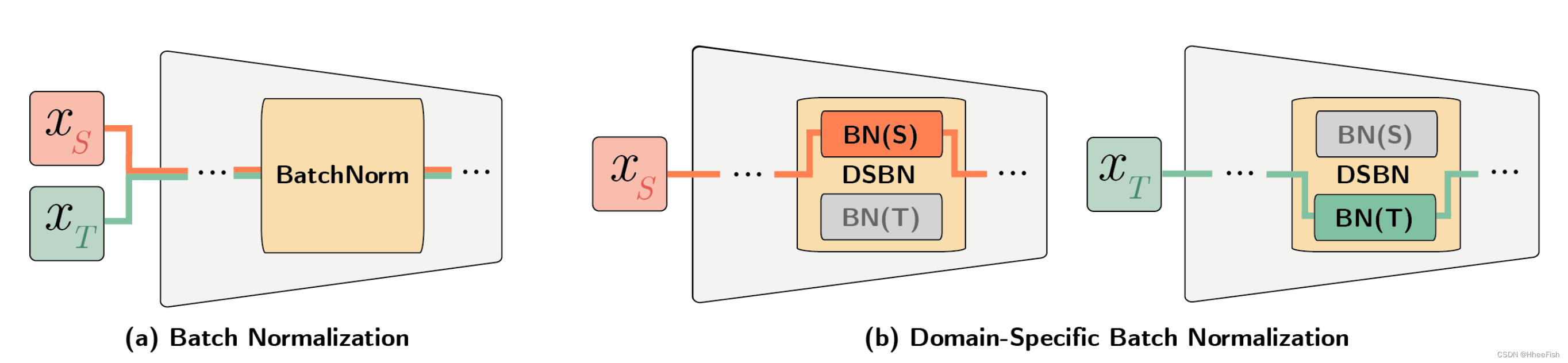
图1。说明BN和DSBN的区别。DSBN层由批处理归一化层中的两个分支组成——一个分支用于源域(S),另一个分支用于目标域(T)。每个输入示例根据其域选择一个分支。在具有DSBN层的域适应网络中,除了DSBN层的参数外,所有的参数在两个域之间共享,并有效地学习两个域的共同信息,而通过DSBN层的域特定bnn参数有效地捕获域特定属性。注意,DSBN层可以插入任何带有BN层的无监督域适应网络。
3.1.批量规范化
BN[5]是一种广泛应用于深度网络的训练技术。BN层在每个通道维度的小批量示例中“漂白”激活,并使用仿射参数γ和β转换激活。x∈RH×W×N表示每个通道的激活,BN表示为
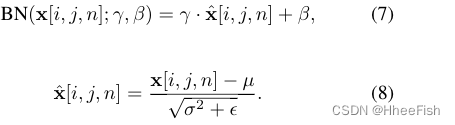
小批内激活的平均值和方差μ和σ由下式计算
ε是一个小常数,以避免被零除
在训练过程中,BN通过带有更新因子α的指数移动平均来估计整个激活的平均值和方差,用指数移动平均来表示,并用指数移动平均来表示。形式上,对于第一个小批,均值和方差由
在测试阶段,BN使用估计的平均值和方差进行“漂白”输入激活。注意,如果畴移显著,则共享源域和目标域的均值和方差是不合适的。
3.2.领域特定批规范化(Domain-Specific Batch Normalization)
DSBN是通过为每个域保留多组BN[5]来实现的。图1说明了BN和DSBN之间的区别。形式上,DSBN为每个域标签d∈{S, T}分配域特定的仿射参数γd和βd。xd∈RH×W×N表示属于域标签d的每个通道的激活,那么DSBN层可以写成
在训练过程中,DSBN分别通过带有更新因子α的指数移动平均估计每个域激活的平均值和方差,该指数移动平均由下式给出
在DSBN的测试阶段,每个域的估计均值和方差用于相应域的样本
我们期望DSBN通过估计批统计和分别学习每个域的仿射参数来捕获特定于域的信息。我们相信DSBN允许网络更好地学习域不变特征,因为通过利用捕获的统计数据和从给定域学习到的参数,可以有效地删除网络中的域特定信息。
DSBN易于插入现有的深度神经网络进行无监督域适应。通过将所有BN层替换为DSBN层并使用带域标签的数据训练整个网络,可以将现有的**分类网络F(·)**转换为特定于域的网络。域特定网络用Fd(·)表示,根据域变量d∈{S, T}, Fd特化为源或目标d域。
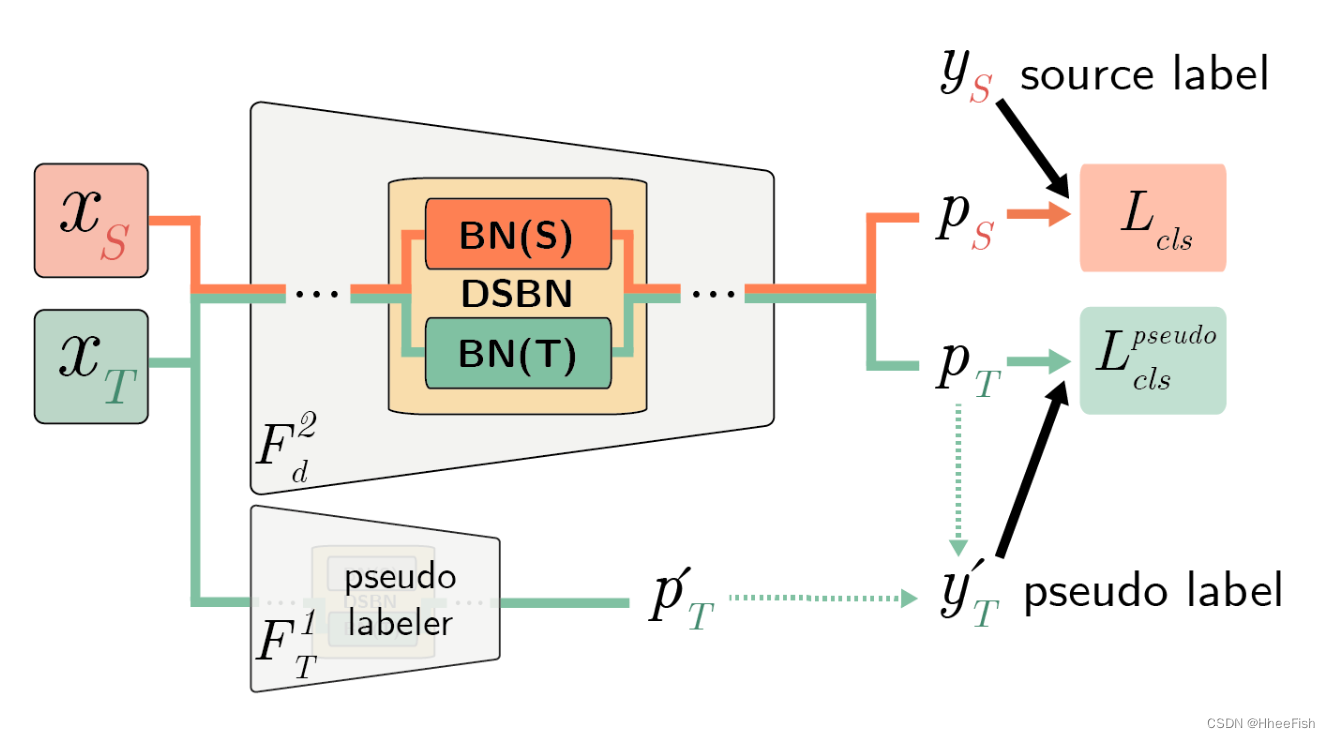
图2。第二阶段训练概述。为了对目标域样本使用中间伪标签,我们使用第一阶段训练过的网络F1T(x)作为第二阶段的伪标签器。在这一阶段,只在两个域上使用分类损失来训练网络。
3.3.扩展到多源域适应
DSBN通过增加更多的域分支,可以很容易地扩展到多源无监督域适应。此外,用所有源域的损失之和定义一个新的多源域适应损失函数如下所示:
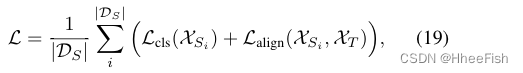
其中DS = {XS1, XS2,…}是源域的集合,Lalign可以是对齐源域和目标域的任何类型的损失。其余的训练过程与单源域适应情况相同
4.基于DSBN的领域自适应
DSBN是一种无监督域适应的通用技术,可以集成到基于批量归一化深度神经网络的各种算法中。我们的框架分两个阶段训练深度网络进行无监督的域适应。在第一阶段,我们训练一个现有的无监督域适应网络生成目标域数据的初始伪标签。第二阶段学习两个域的最终模型,使用源域的ground-truth和目标域的伪标签作为监督,其中伪标签在目标域在训练过程中逐步细化。这两个阶段的网络都包含DSBN层,以更有效地学习域不变表示,从而更好地适应目标域。为了进一步提高准确性,我们可以对第二阶段训练进行额外的迭代,其中使用前一迭代的结果更新伪标签。本节的其余部分将详细介绍我们使用DSBN的两阶段训练方法
4.1.阶段1:训练初始伪标签
由于我们的框架具有通用性和灵活性,任何无监督域自适应网络只要有BN层,都可以用来估计目标域数据的初始伪标签。在本文中,我们选择了两个最先进的模型作为初始伪标签发生器:MSTN[27]和CPUA[14]。如第3.2节所述,我们用DSBN替换它们的BN层,以便它们更有效地学习域不变表示。然后,这些网络根据它们原有的损失和学习策略进行训练。经过训练的初始伪标签生成器用F1T表示。
4.2.阶段2:使用伪标签进行自训练
在第二阶段,我们利用两个域的数据及其标签,利用丰富的域不变表示,并在完全监督的情况下训练两个域的最终模型。该网络使用两个分类损耗进行训练——一个是具有地真标签的源域,另一个是具有伪标签的目标域——得到的网络用F2d(d∈{S, T})表示。总损失函数由两个领域的两个损失项的简单相加得到,如下:
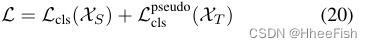
其中:
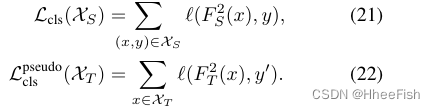
式(21)和式(22)中,ℓ(·,·)为交叉熵损失,y’表示分配给目标域x∈XT的伪标签
伪标签y’由F1T初始化,并由F2T逐步细化如下:
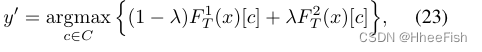
其中FiT(x)[c]表示FiT和权重因子λ给出的类预测得分,在训练过程中从0逐渐变化到1。这种方法可以看作是一种自我训练,因为F2T在训练过程中参与了伪标签的生成。在训练的早期阶段,由于F2T的预测可能不可靠,我们对F1T给出的初始伪标签赋予了更多的权重。权重λ逐渐增大,在训练的最后阶段,伪标记完全依赖于F2T。我们使用[3]来抑制潜在的有噪声的伪标签;当γ= 10时,λ适应因子λ=2/(1+exp(−γ·p))−1逐渐增大
由于F2T使用F1T给出的合理的初始伪标签进行训练,而F1T仅利用弱信息进行域对齐,因此F2T比F1T更能准确地识别目标域图像。为了进一步提高精度,使用F2T估计更精确的初始伪标签是很自然的。因此,我们迭代地进行第二阶段过程,其中初始伪标签使用前一迭代模型的预测结果进行更新。实验结果表明,这种迭代方法能有效地提高目标区域的分类精度
5.实验
我们提出了实证结果来验证提出的框架,并将我们的方法与最先进的领域适应方法进行比较。
5.1.实验设置
我们讨论了用于训练和评估的数据集,并介绍了包括超参数设置在内的实现细节
5.1.1.数据集

图3。每个数据集的示例图像。(a)两个域的VisDA-C数据集图像,(b)三个域的Office-31数据集图像,©四个域的Office-Home数据集图像。
我们在实验中使用了三个数据集:VisDA-C [16], Office-31[17]和Office-Home[26]。VisDA-C是一个用于2017视觉领域适应挑战的大型基准数据集。它由两个域组成——虚拟和现实,并从MS-COCO[8]数据集中获得12个公共对象类的152,409张合成图像和55400张真实图像。Office-31是一个领域适应的标准基准,它包括31个类别的三个不同的领域:Amazon (a)有2817张图片,Webcam (W)有795张图片,DSLR (D)有498张图片。Office-Home[26]有四个域:艺术(Ar)有2,427张图片,剪纸(Cl)有4,365张图片,产品(Pr)有4,439张图片,现实世界(Rw)有4,357张图片。每个域包含65类日常对象。我们采用[3]中引入的完全转换协议来评估数据集上我们的框架。
5.1.2.应用细节
根据[3,20],我们的框架的骨干网络采用resnet -101用于visa - c数据集,ResNet-50用于Office-31和office - home数据集。所有的网络都有BN层,并在ImageNet上预先训练。为了比较BN和DSBN层之间的纯粹差异,我们为每个域构造了小批量,并分别转发它们。批次大小设置为40,所有实验都是相同的。我们使用Adam优化器[6],β1= 0.9, β2= 0.999。阶段1和阶段2的初始学习速率分别为η0= 1.0×10−4and5.0×10−5。如[3]中所示,根据ηp=η0/(1+αp)β的公式调整学习链,其中α= 10,β= 0.75, p表示训练进度在0 ~ 1之间呈线性变化。优化器的最大迭代次数设置为50,000
5.2.结果
我们给出了基于单源和多源域自适应的标准基准数据集上的实验结果。
5.2.1.VisDA-C
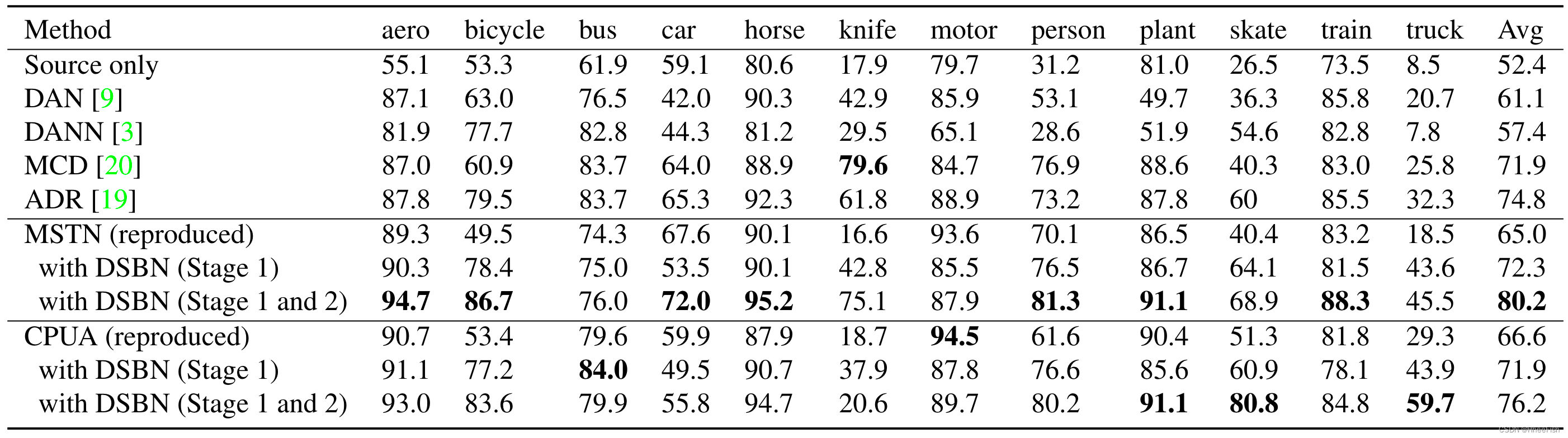
表1。基于ResNet-101骨干网的多种算法在VisDA-C验证数据集上的分类性能(%)结果清楚地表明,我们的两阶段学习框架DSBN有效地提高了准确性。
表1量化了我们采用MSTN和CPUA作为初始伪标签生成器的方法的性能,并将其与VisDA-C数据集上的最新记录进行了比较。在表中,“DSBN(阶段1)”表示我们用DSBN替换BN层并执行第一阶段训练,“DSBN1(阶段1和阶段2)”表示我们同时执行第一和第二阶段训练。我们提出的方法通过将DSBN应用于基线模型,显著且一致地提高了准确性,并在与MSTN结合时实现了最先进的性能[27]。还要注意,我们的模型可靠地识别了一些很难的类,如刀、人、滑板和卡车
5.2.2.Office-31
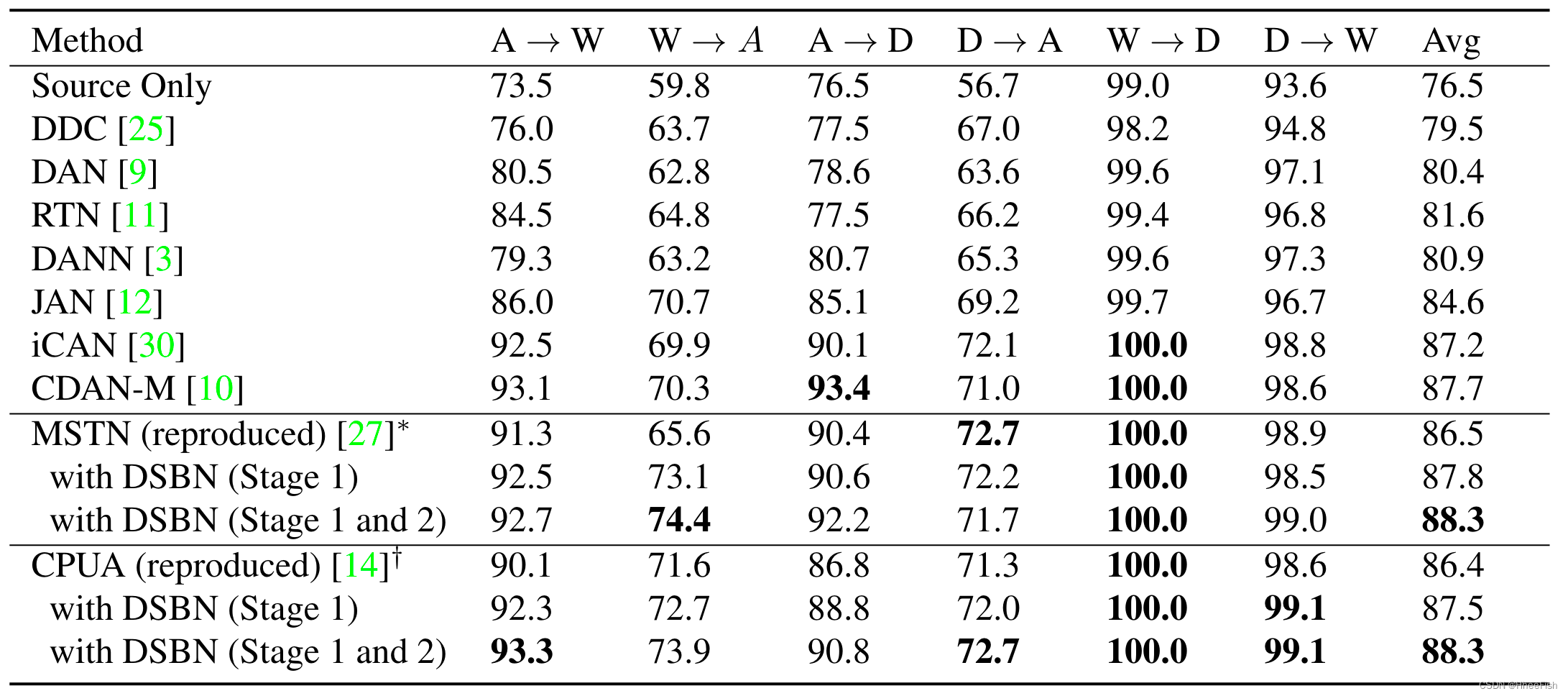
表2。Office-31数据集的分类准确度(%)(ResNet-50)。*原始论文报告使用alexnet的平均准确率为79.1%。†原文报道ResNet-50的平均准确率为87.9%。
表2展示了我们在Office-31数据集上使用MSTN和CPUA的方法的总体得分。在两个阶段都经过DSBN训练的模型可以获得最先进的性能,并始终优于两个基线模型。表2还表明,我们的框架可以成功地应用于现有的域自适应算法,并大大提高了性能
5.2.3.多个源域
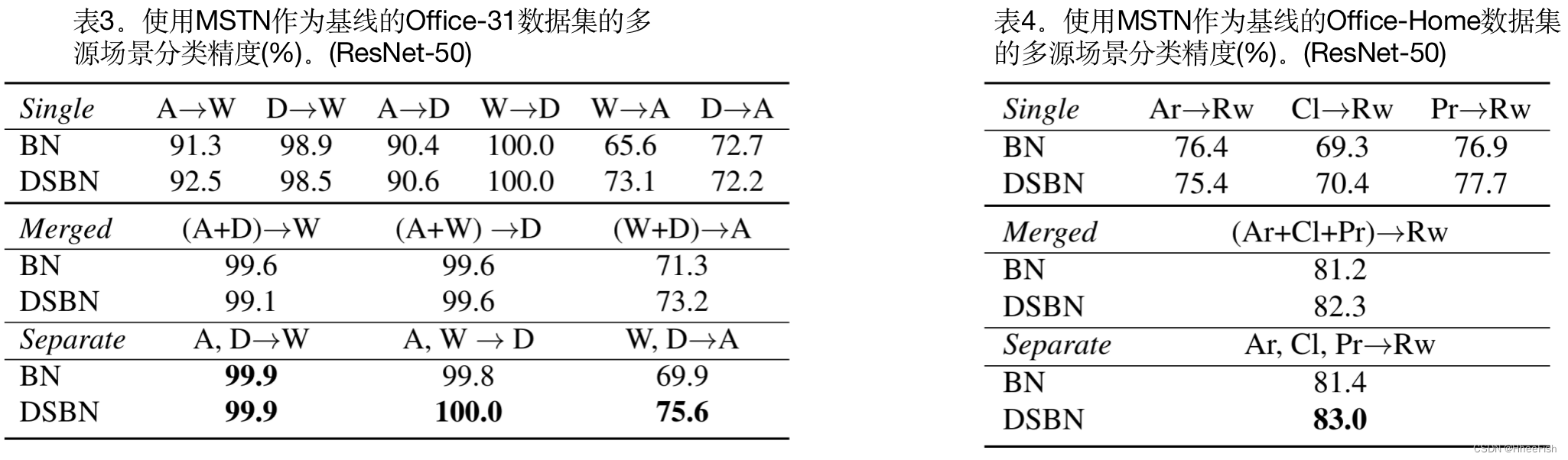
表3和表4分别展示了office -31和Office-Home数据集上的多源域自适应结果。为了比较多源和单源域适应,将表顶部的单源结果作为“单一”,并附加两个不同的多源场景:“合并”和“分离”。合并意味着来自多个源域的数据被组合起来并构造一个新的更大的源域数据集,而单独参数表示每个源域被单独考虑。在这种情况下,我们总共有|DS|+1个域并且网络中有同样数目的DSBN分支。当目标任务很容易时,在BN和DSBN之间存在边际性能增益,但我们的模型在所有设置下都始终优于BN模型。特别是,对于表3中任务“A”的较难的域适应,具有源域分离的DSBN比合并的情况要好得多。这一结果表明DSBN在多源域适应任务中也具有优势。注意,这些合并情况并不总是比没有DSBN的合并情况好
5.3.分析
5.3.1.消融实验
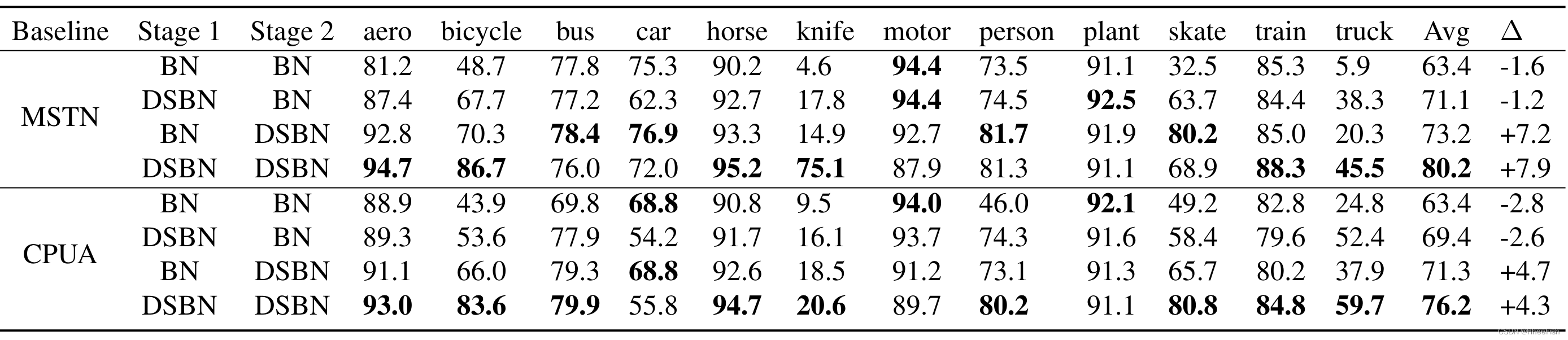
表5所示。在VisDA-C验证数据集上,批量归一化变化组合的消融结果。(ResNet-101),其中∆表示第二阶段训练相对于仅第一阶段训练结果的精度增益
我们在我们的框架上进行消融实验,分析DSBN与BN相比的效果。表5总结了使用MSTN和CPUA作为基线架构的VisDA CDATA集上的消融结果,其中表中最后一列显示了第二阶段训练相对于第一阶段训练结果的精确度。我们测试了两阶段培训中不同培训程序的几种组合。结果直接表明,DSBN在两种训练过程中都起着至关重要的作用。另一个重要的点是,使用DSBN的第二阶段训练可以大大提高性能,而第二阶段中的普通BN没有帮助。这意味着在训练阶段分离特定于域的信息有助于设置可靠的伪标签。请注意,特别是对于较难的类,这种趋势更为明显
5.3.2.特征可视化
图4可视化了BN(左)和DSBN(右)的实例嵌入,使用MSTN作为VisDA-C数据集的基线。我们观察到,通过对DSBN进行积分,同一类中的两个域的例子能更好地对齐,这意味着DSBN能有效地学习域不变表示

图4。使用VisDA-C验证数据集上的MSTNas基线算法训练的ResNet-101模型的样本表示的t-SNE图(左)和DSBN(右)。他们证明DSBN提高了跨领域表示的一致性,
5.3.3.迭代学习
我们的框架采用第一阶段获得的网络作为第二阶段的伪标记器,第二阶段学习到的网络比伪标记器更强。因此,通过迭代地应用第二阶段学习过程,当前迭代中的伪标签由前一个迭代的结果给出,我们可以期待进一步的性能改进。为了验证这一想法,我们使用MSTNas基线算法在VisDA-C数据集上评估每次迭代的分类精度。如表6所示,第二阶段的迭代学习在迭代中逐渐提高精度。
6.结论
我们提出了用于无监督域适应的特定于域的批归一化。提出的框架具有批处理规范化层的独立分支,每个域一个分支,同时跨域共享所有其他参数。这种思想一般适用于具有批处理归一化层的深度神经网络。该框架采用两阶段训练策略,应用于两种最新的无监督域自适应算法mstn和CPUA,并在标准基准数据集上展示了出色的性能。我们还展示了我们的框架扩展到源域适应问题的能力,并报告了与其他方法相比显著改进的结果。
参考文献
[1] Karsten M. Borgwardt, Arthur Gretton, Malte J. Rasch, Hans-Peter Kriegel, Bernhard Sch ̈olkopf, and Alex J. Smola. Inte-grating Structured Biological Data by Kernel Maximum MeanDiscrepancy.Bioinformatics, 22(14):e49–e57, July 2006.2
[2] Konstantinos Bousmalis, George Trigeorgis, Nathan Silber-man, Dilip Krishnan, and Dumitru Erhan. Domain SeparationNetworks. InNIPS, 2016.2
[3] Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, PascalGermain, Hugo Larochelle, Franc ̧ois Laviolette, Mario Marc-hand, and Victor Lempitsky. Domain-Adversarial Training ofNeural Networks.JMLR, 17(1):2096–2030, 2016.1,2,3,5,6,7
[4] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu,Phillip Isola, Kate Saenko, Alexei A. Efros, and Trevor Dar-rell. CyCADA: Cycle Consistent Adversarial Domain Adap-tation. InICML, 2018.1,2
[5] Sergey Ioffe and Christian Szegedy. Batch Normalization:Accelerating Deep Network Training by Reducing InternalCovariate Shift. InICML, 2015.3,4
[6] Diederik P. Kingma and Jimmy Ba. Adam: A Method forStochastic Optimization. InICLR, 2015.6
[7] Yanghao Li, Naiyan Wang, Jianping Shi, Xiaodi Hou, and Ji-aying Liu. Adaptive Batch Normalization for practical domainadaptation.Pattern Recognition, 80:109–117, 2018.2
[8] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,Pietro Perona, Deva Ramanan, Piotr Doll ́ar, and C LawrenceZitnick. Microsoft COCO: Common Objects in Context. InECCV, 2014.6
[9] Mingsheng Long, Yue Cao, Jianmin Wang, and Michael I Jor-dan. Learning Transferable Features with Deep AdaptationNetworks. InICML, 2015.6,7
[10] Mingsheng Long, Zhangjie Cao, Jianmin Wang, andMichael I Jordan. Conditional Adversarial Domain Adapta-tion. InNIPS, 2018.1,2,7
[11] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael IJordan. Unsupervised Domain Adaptation with ResidualTransfer Networks. InNIPS, 2016.7
[12] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael IJordan. Deep Transfer Learning with Joint Adaptation Net-works. InICML, 2017.2,7
[13] Massimiliano Mancini, Lorenzo Porzi, Samuel Rota Bul,Barbara Caputo, and Elisa Ricci. Boosting Domain Adap-tation by Discovering Latent Domains. InCVPR, 2018.2
[14] Jeroen Manders, Elena Marchiori, and Twan van Laarhoven.Simple Domain Adaptation with Class Prediction UncertaintyAlignment.arXiv preprint arXiv:1804.04448, 2018.1,2,3,5,7
[15] Fabio Maria Carlucci, Lorenzo Porzi, Barbara Caputo, ElisaRicci, and Samuel Rota Bulo. AutoDIAL: Automatic DomaInAlignment Layers. InICCV, 2017.2
[16] Xingchao Peng, Ben Usman, Neela Kaushik, Judy Hoffman,Dequan Wang, and Kate Saenko. VisDA: The Visual DomainAdaptation Challenge, 2017.5
[17] Kate Saenko, Brian Kulis, Mario Fritz, and Trevor Darrell.Adapting Visual Category Models to New Domains. InECCV,2010.5
[18] Kuniaki Saito, Yoshitaka Ushiku, and Tatsuya Harada.Asymmetric Tri-training for Unsupervised Domain Adapta-tion. InICML, 2017.2
[19] Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, and KateSaenko. Adversarial Dropout Regularization. InProc. In-ternational Conference on Learning Representations (ICLR),2018.6
[20] Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tat-suya Harada. Maximum Classifier Discrepancy for Unsuper-vised Domain Adaptation. InCVPR, 2018.6
[21] Jian Shen, Yanru Qu, Weinan Zhang, and Yong Yu. Wasser-stein Distance Guided Representation Learning for DomainAdaptation. InAAAI, 2018.2
[22] Baochen Sun, Jiashi Feng, and Kate Saenko. Return of Frus-tratingly Easy Domain Adaptation. InAAAI, 2016.2
[23] Baochen Sun and Kate Saenko. Deep CORAL: CorrelationAlignment for Deep Domain Adaptation. InECCV Work-shops, 2016.1,2
[24] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell.Adversarial Discriminative Domain Adaptation. InCVPR,2017.2
[25] Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, andTrevor Darrell. Deep Domain Confusion: Maximizing for Do-main Invariance.CoRR, abs/1412.3474, 2014.7
[26] Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty,and Sethuraman Panchanathan. Deep Hashing Network forUnsupervised Domain Adaptation. InCVPR, 2017.5,6
[27] Shaoan Xie, Zibin Zheng, Liang Chen, and Chuan Chen.Learning Semantic Representations for Unsupervised DomainAdaptation. InICML, 2018.1,2,3,5,7
[28] Hongliang Yan, Yukang Ding, Peihua Li, Qilong Wang,Yong Xu, and Wangmeng Zuo. Mind the Class Weight Bias:Weighted Maximum Mean Discrepancy for Unsupervised Do-main Adaptation. InCVPR, 2017.2
[29] Werner Zellinger, Thomas Grubinger, Edwin Lughofer,Thomas Natschl ̈ager, and Susanne Saminger-Platz. CentralMoment Discrepancy (CMD) for Domain-Invariant Represen-tation Learning. InICLR, 2017.2
[30] Weichen Zhang, Wanli Ouyang, Wen Li, and Dong Xu. Col-laborative and Adversarial Network for Unsupervised domainadaptation. InCVPR, 2018.1,2,7














 3616
3616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









