






一、安装:
1.下载文件地址
官方源码地址:https://github.com/tesseract-ocr/tesseract
exe执行文件下载地址:https://digi.bib.uni-mannheim.de/tesseract/
2.安装
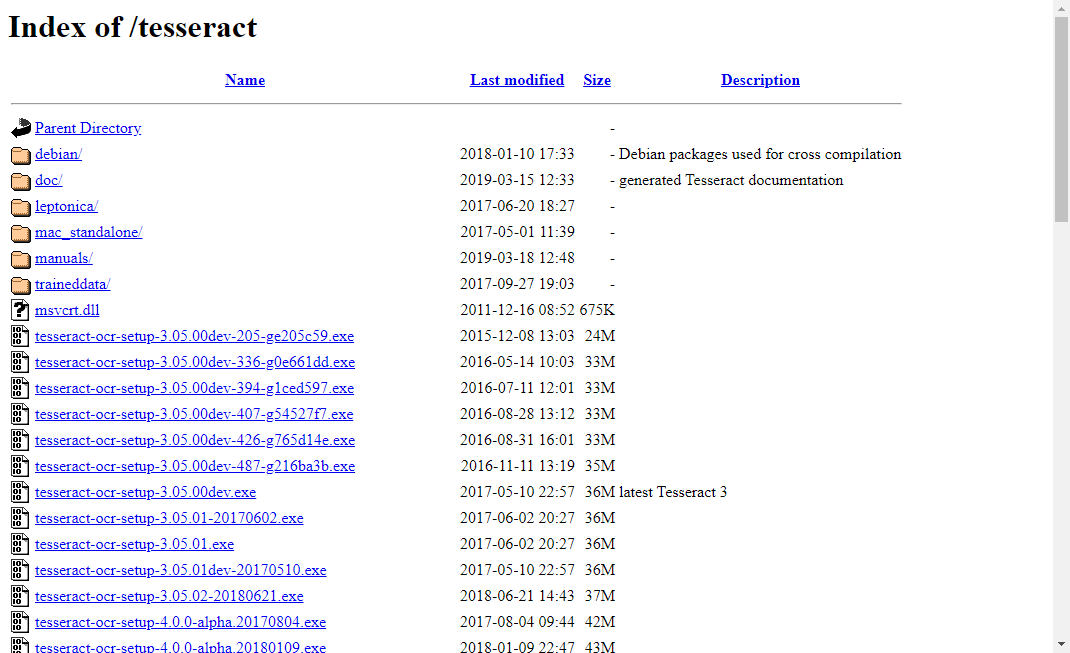
安装时注意选择所需要的语言库,按需选择即可,安装时会自动在线下载选择的语言库,
注意:记住安装的目录,配置环境变量需要用到
3.配置环境变量
我安装的文件夹路径为:D:\soft\tesseract
回到桌面:
右键我的电脑--->选择高级系统设置

选择高级--->环境变量
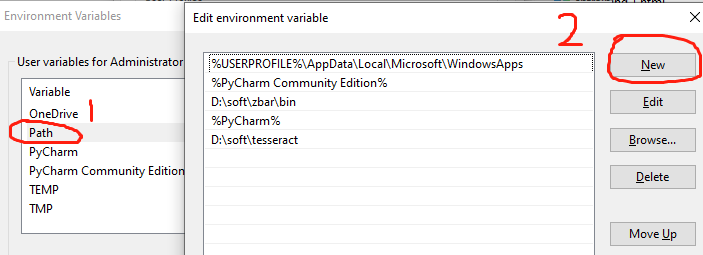
分别在用户变量和系统变量中添加刚刚的安装路径
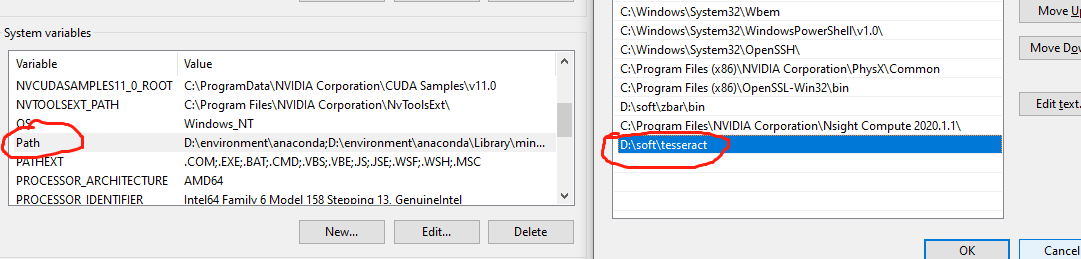
在系统变量中新建TESSDATA_PREFIX,并添加安装目录下的tessdata路径
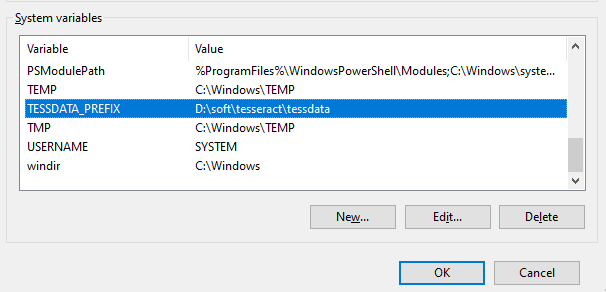
4.重启电脑
5.查看安装成功与否
命令行输入:
tesseract -v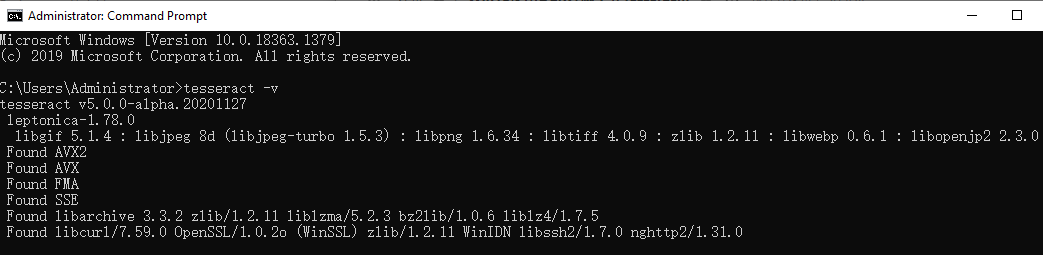
显示版本信息则代表安装成功
二、Pycharm中使用pytesseract识别文本
1.安装pytesseract
命令行:
pip install pytesseract即可
2.使用tesseract识别文本
安装完成后就可以测试文本图片了
识别的目标图片:

识别代码:
import pytesseract
from PIL import Image, ImageEnhance
import cv2
def printText(img_path,isDraw):
# print(pytesseract.get_languages()) #查看自己安装的语言库有哪些
# img = Image.open(img_path)
img = cv2.imread(img_path)
img_ = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# text = pytesseract.image_to_string(Image.open(path),lang="eng")
text = pytesseract.image_to_string(img_,lang="chi_sim") #lang为识别的语言,chi_sim代表中文,eng为英文,可以混合使用
# text = pytesseract.image_to_string(img,lang="chi_sim+eng")
if isDraw==True:
print(text)
imgDraw(img)
else:
print(text)
def imgDraw(image):
h, w, c = image.shape
boxes = pytesseract.image_to_boxes(image)
for b in boxes.splitlines():
b = b.split(' ')
image = cv2.rectangle(image, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), (0, 0, 255), 1)
# image = cv.resize(image, None, None, fx=2, fy=2, interpolation=cv.INTER_LINEAR) #图片放大两倍进行识别有时效果会更好
cv2.imshow('text detect', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
'''
如果出现错误,可能是环境变量配置的原因,可以重新配置下环境变量,也可以在代码中加入以下两行:
pytesseract.pytesseract.tesseract_cmd = 'D:/soft/tesseract/tesseract.exe' #安装目录下的EXE文件的路径
tessdata_dir_config = '--tessdata-dir "D:/soft/tesseract/tessdata"' #安装目录下的tessdata文件夹路径
'''
if __name__ == '__main__':
img_path = "./a.png"
printText(img_path,True)输出结果如图(有误识别的):
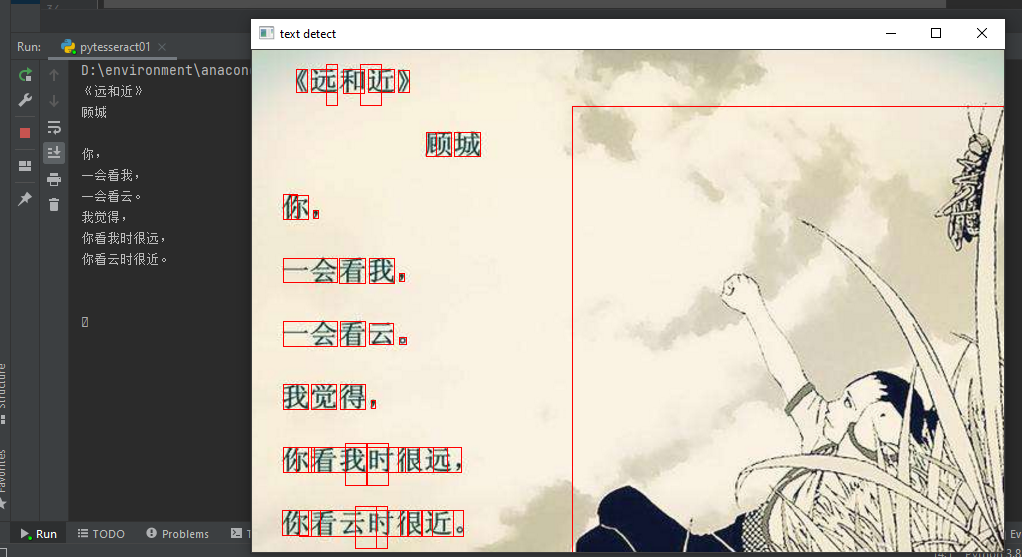

















 2480
2480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









