







 本文介绍了Paddle-structure,一个强大的AI模型,用于处理PDF页面元素分析,包括文本检测、识别和表格结构识别。文章详细指导了模型的安装与使用过程,以及在遇到问题时的解决方案,展示了模型的效果和输出的HTML及Excel文件。
本文介绍了Paddle-structure,一个强大的AI模型,用于处理PDF页面元素分析,包括文本检测、识别和表格结构识别。文章详细指导了模型的安装与使用过程,以及在遇到问题时的解决方案,展示了模型的效果和输出的HTML及Excel文件。
Paddle-structure是目前我们能找到的可以做中英文版面分析较好的一个基础模型,其开源版可以识别十类页面元素。这篇文章介绍演示如何使用。
pdf的解析大体上有两条路,一条是基于规则,一条是基于AI。所谓基于规则就是根据文档的组织特点去“算”每部分的样式和内容。笔者认为这种方式很不通用,因为pdf的类型、排版实在太多了,没办法穷举。因此笔者采用AI的方式来解决:目标检测 和 OCR文字识别
一、Paddle-structure
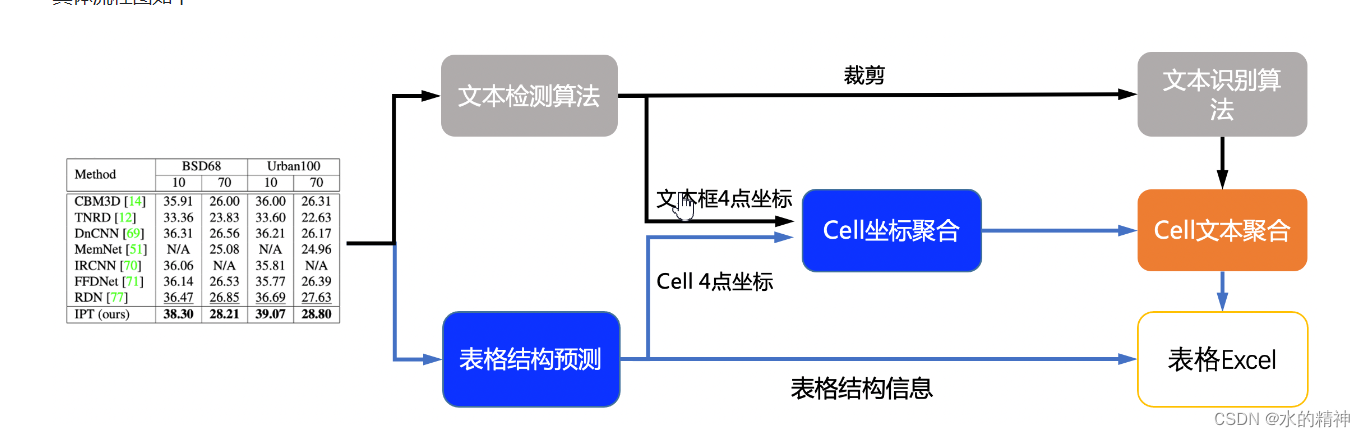
流程说明:
- 图片由单行文字检测模型检测到单行文字的坐标,然后送入识别模型拿到识别结果。
- 图片由SLANet模型拿到表格的结构信息和单元格的坐标信息。
- 由单行文字的坐标、识别结果和单元格的坐标一起组合出单元格的识别结果。
- 单元格的识别结果和表格结构一起构造表格的html字符串。
二、效果
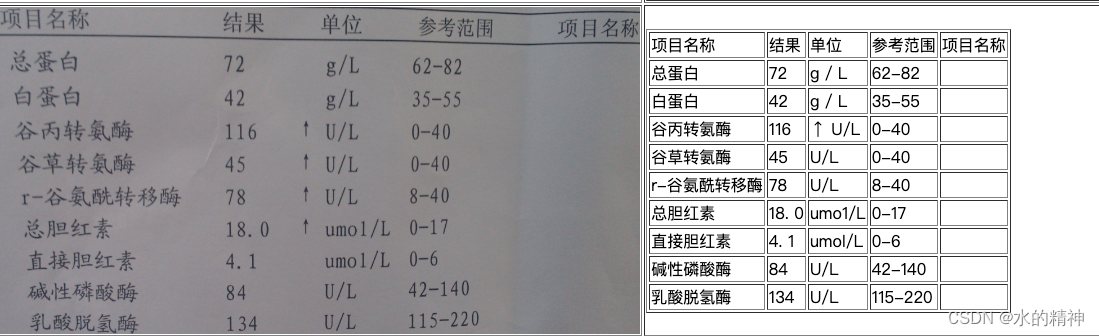
三、安装使用
下载源码包
上传到服务器上
unzip PaddleOCR-release-2.7.zip
cd PaddleOCR-release-2.7
cd ppstructure
# 下载模型
mkdir inference && cd inference
# 下载基于PubTabNet数据集训练的文本检测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar && tar xf en_ppocr_mobile_v2.0_table_det_infer.tar
# 下载基于PubTabNet数据集训练的文本识别模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar && tar xf en_ppocr_mobile_v2.0_table_rec_infer.tar
# 下载基于PubTabNet数据集训练的表格识别模型并解压
wget https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/en_ppstructure_mobile_v2.0_SLANet_infer.tar && tar xf en_ppstructure_mobile_v2.0_SLANet_infer.tar
cd ..
python3 table/eval_table.py \
--det_model_dir=inference/en_ppocr_mobile_v2.0_table_det_infer \
--rec_model_dir=inference/en_ppocr_mobile_v2.0_table_rec_infer \
--table_model_dir=inference/en_ppstructure_mobile_v2.0_SLANet_infer \
--image_dir=train_data/table/pubtabnet/val/ \
--rec_char_dict_path=../ppocr/utils/dict/table_dict.txt \
--table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
--det_limit_side_len=736 \
--det_limit_type=min \
--rec_image_shape=3,32,320 \
--gt_path=path/to/gt.txt我按照官方只指示跑的时候,有问题
首先说服务器上缺少 /lib64/libstdc++.so.6: version `GLIBCXX_3.4.20' not found 这个不太好解决。我在docker容器里跑的。
还是有问题 缺少paddle
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple安装完以后就可以运行上述命令了。
最终得到结果:一个html的内容。就是解析后的结果,还输出了一个excel文件到了 ../output/table下。
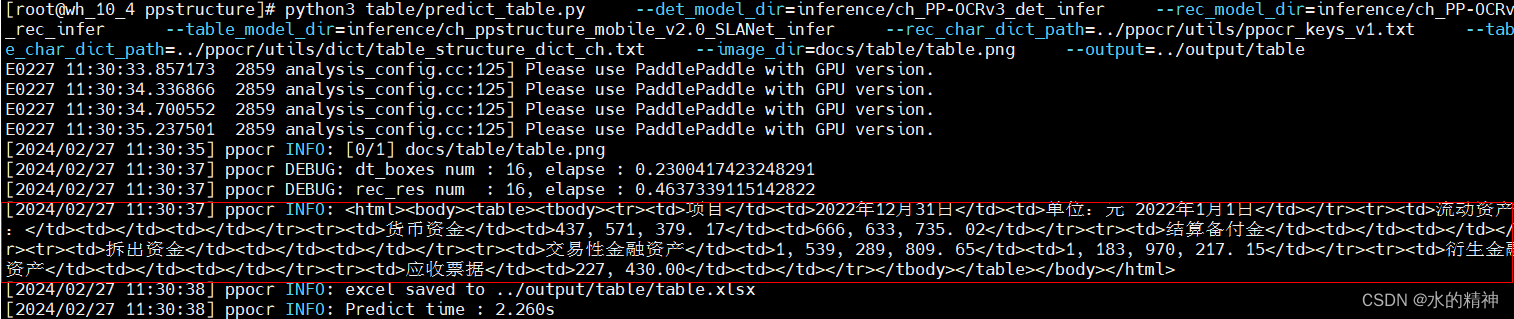
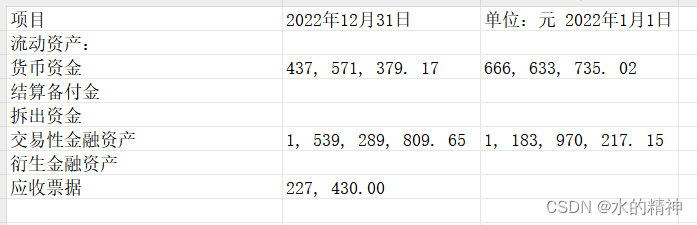
excel
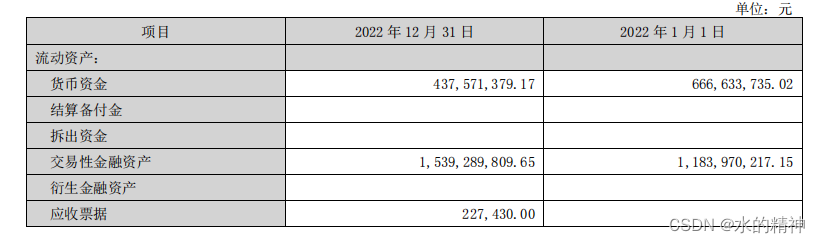
对比原图片

















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









