






增强智能体的工具使用能力
智能代理和工具之间的关系可以类比为人类使用工具来完成任务的方式。就像人类使用锤子敲打钉子一样,代理可以调用一个API来获取数据、使用翻译服务来翻译文本或者执行其他功能以协助或完成它们的任务。通过增强代理的工具使用能力,它们能够执行更复杂、更精细的任务,并在更广泛的场景中提供帮助。
最近一些开源的大语言模型能够自由地与各种外部工具交互,比如Toolformer、Gorilla、ToolLLama等模型,它们是一类设计为优化和改进代理工具使用能力的模型,使代理更有效地与工具集成,完成任务,从而扩展LLMs的能力范围。
Gorilla:精准调用1600+ API的智能体进步
Gorilla是一个基于检索感知的LLaMA-7B大型语言模型,也是一种基础的智能体,它能够使用各种API工具。这个模型通过分析自然语言查询,精准地找出并调用合适、语义语法均正确的API,从而提升了大型语言模型执行任务的能力和准确性。
Gorilla的一个主要特点是它能够准确地调用超过1600个API,并且这个数量还在增长。这一成就展示了如何利用语言模型的理解和生成能力,来扩展其在自动化工具使用上的潜力。为了进一步提高Gorilla的性能,开发团队通过模拟聊天式对话,对LLaMA-7B模型进行了微调,让其能够更自然地与用户进行交流,并生成相应的API调用。
此外,Gorilla也能够处理带有约束条件的API调用,这要求模型除了理解API的基本功能外,还必须能够识别和考虑各种参数约束。这一能力让Gorilla在处理特定要求的任务时显得更加智能和可靠。
在训练过程中,Gorilla不仅在无检索器的情况下学习,还在有检索器的环境中进行训练,以提升其适应和理解不断更新的API文档的能力。这种训练方式使得Gorilla不仅能响应用户的直接指令,还能够针对检索到的相关API文档生成精确的调用指令,减少了错误幻觉的发生。
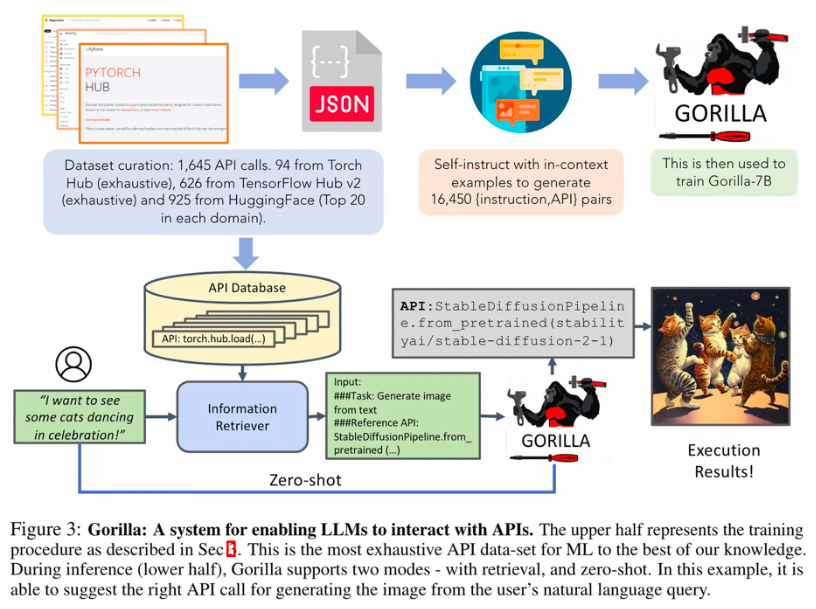
总的来说,Gorilla不仅增强了语言模型在API调用和工具使用上的能力,还提高了处理带约束任务的复杂性,展现了智能体在自动化和人机交互方面的巨大潜力。
Gorilla-CLI:提升命令行互动体验
Gorilla-CLI是一个由加州大学伯克利分校开发,基于Gorilla模型的提升命令行交互体验的工具,它通过智能化的命令预测和补全,使得命令行操作更加直观和高效。当开发者在终端中输入命令时,Gorilla-CLI能够根据上下文提示可能的命令补全,甚至可以根据过去的操作模式预测下一步可能的命令,从而加速开发流程。https://github.com/gorilla-llm/gorilla-cli
安装步骤:
#通过pip安装Gorilla CLI
pip install gorilla-cli
# Gorilla命令生成示例
$ gorilla 从当前目录下找到qa.txt文件
# 命令建议:
find . -name "qa.txt"
# Gorilla命令生成示例
$ gorilla 统计qa.txt文件中有多少个问题?
# Gorilla命令生成示例
$ gorilla 把qa.txt中的问题单独写到一个新的文件中
实验效果:
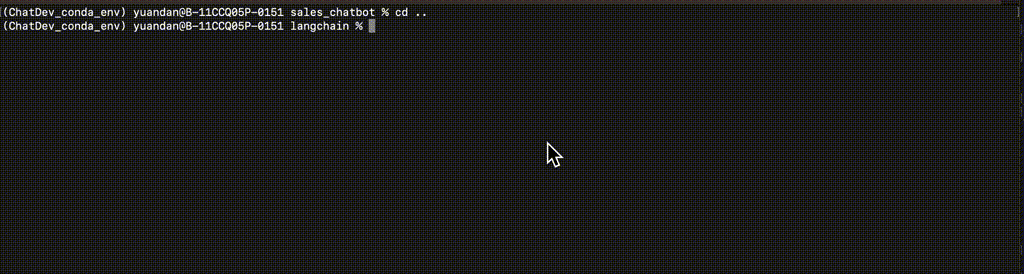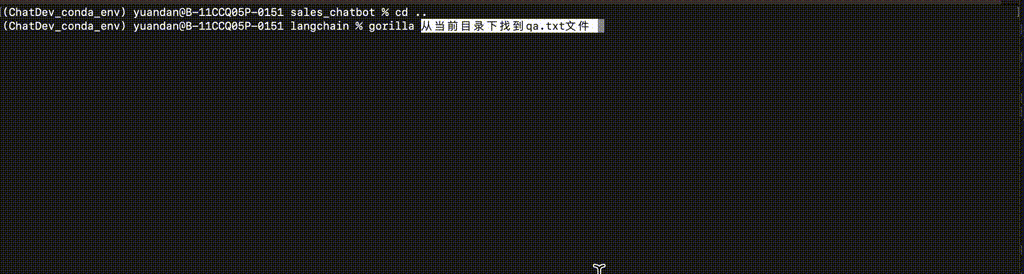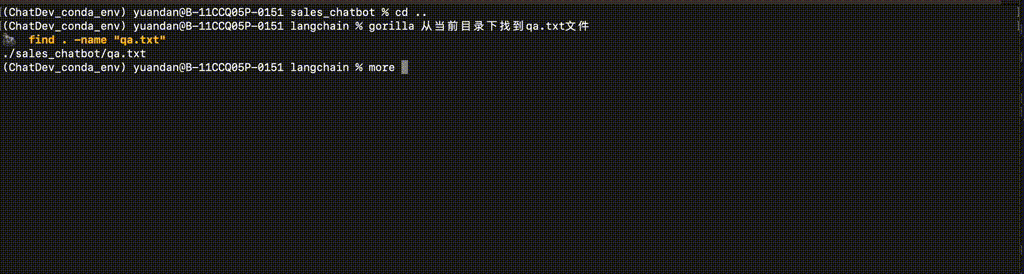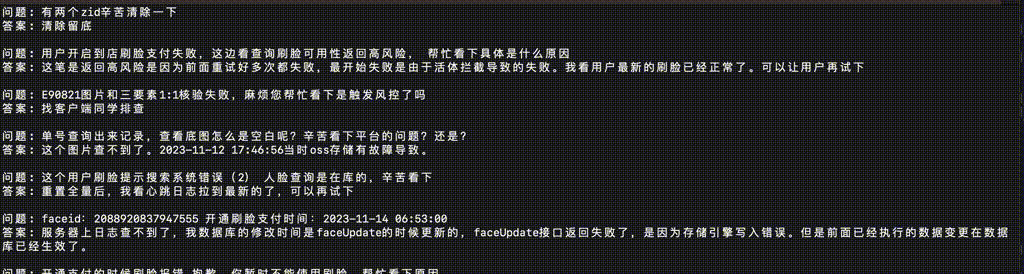

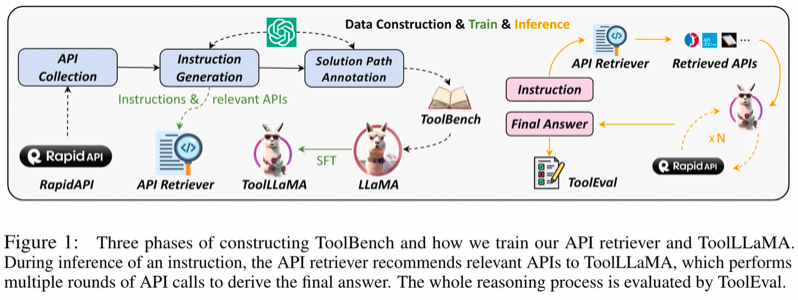
ToolLLaMa:实现16000+ API的精准协同调用
ToolLLaMA也是一个基于开源LLaMA-7B语言模型的框架,旨在增强模型执行复杂任务的能力,特别是遵循指令使用外部工具API。通过扩展传统LLMs的功能,ToolLLaMA可以处理真实世界的应用场景,这些场景需要结合多个API工具来完成任务。(gorilla5月份刚发布, ToolLLaMa 8月份就紧跟着发布了)
ToolLLaMA的关键特点在于支持大量的真实世界API,共16464个,覆盖49个类别。这种丰富的API支持为用户提供了更多的工具选项,以满足各种应用需求。ToolLLaMA使用ChatGPT生成的指令调整数据集ToolBench,这些数据集包含单工具和多工具使用场景的指令,使得模型能够学习如何解析和执行包含多个API调用的指令。
为了提高在这些复杂任务中的效率,ToolLLaMA采用了DFSDT算法,它是一种基于深度优先搜索的决策树,能够帮助模型在多个潜在解决方案中做出更好的选择。此算法增强了模型规划任务路径和推理的能力。
ToolLLaMA训练了一个API检索器,能够为给定的用户指令推荐合适的API,从而省去了手动筛选API的步骤,使得整个使用流程更加高效。
在性能评估方面,ToolEval结果表明,ToolLLaMA在执行复杂指令及泛化到未见APIs方面的效果与封闭源码的高级模型ChatGPT相似。这一发现表明,通过适当的训练方法和数据集,开源LLMs能够实现类似于封闭源码LLMs的工具使用能力。ToolLLaMA项目的代码、训练模型和演示都已在GitHub公开,以促进社区的进一步发展和应用。
总体而言,ToolLLaMA不仅在API支持数量上超越了类似Gorilla的模型,更在任务规划、API检索和泛化能力上提供了新的优势,这些都是推动开源LLMs在复杂应用场景中应用的重要因素。https://github.com/OpenBMB/ToolBench
安装步骤:
#克隆这个仓库并导航到ToolBench文件夹。
git clone git@github.com:OpenBMB/ToolBench.git
cd ToolBench
#安装包(python>=3.9)
pip install -r requirements.txt
#或者只为ToolEval安装
pip install -r toolbench/tooleval/requirements.txt
#使用我们的RapidAPI服务器进行推理
#请首先填写表单,审核后我们会发送给您toolbench密钥。然后准备您的toolbench密钥:
export TOOLBENCH_KEY="your_toolbench_key"
#对于ToolLLaMA,要使用ToolLLaMA进行推理,请运行以下命令:
export PYTHONPATH=./
python toolbench/inference/qa_pipeline.py \
--tool_root_dir data/toolenv/tools/ \
--backbone_model toolllama \
--model_path ToolBench/ToolLLaMA-7b \
--max_observation_length 1024 \
--observ_compress_method truncate \
--method DFS_woFilter_w2 \
--input_query_file data/test_instruction/G1_instruction.json \
--output_answer_file toolllama_dfs_inference_result \
--toolbench_key $TOOLBENCH_KEY
#如果想要尝试自己训练,参考下面的流程
#准备数据和工具环境:
wget --no-check-certificate 'https://drive.google.com/uc?export=download&id=1XFjDxVZdUY7TXYF2yvzx3pJlS2fy78jk&confirm=yes' -O data.zip
unzip data.zip 数据预处理,以G1_answer为例:
export PYTHONPATH=./
python preprocess/preprocess_toolllama_data.py \
--tool_data_dir data/answer/G1_answer \
--method DFS_woFilter_w2 \
--output_file data/answer/toolllama_G1_dfs.json
#训练代码基于FastChat。您可以使用以下命令使用我们的预处理数据data/toolllama_G123_dfs_train.json来训练2 x A100(80GB)的ToolLLaMA-7b的lora版本。对于预处理的细节,我们分别将G1、G2和G3数据分割成训练、评估和测试部分,并在我们的主要实验中合并训练数据进行训练:
export PYTHONPATH=./
deepspeed --master_port=20001 toolbench/train/train_lora.py \
--model_name_or_path huggyllama/llama-7b \
--data_path data/toolllama_G123_dfs_train.json \
--eval_data_path data/toolllama_G123_dfs_eval.json \
--conv_template tool-llama-single-round \
--bf16 True \
--output_dir toolllama_lora \
--num_train_epochs 5 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 2 \
--evaluation_strategy "epoch" \
--prediction_loss_only \
--save_strategy "epoch" \
--save_total_limit 8 \
--learning_rate 5e-5 \
--weight_decay 0. \
--warmup_ratio 0.04 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--source_model_max_length 2048 \
--model_max_length 8192 \
--gradient_checkpointing True \
--lazy_preprocess True \
--deepspeed ds_configs/stage2.json \
--report_to none
实验效果:
如果你正在计划一个给最好朋友的惊喜派对,并希望为每位参加聚会的人提供一些鼓舞人心的话语,那么可以使用toolLLama这样的语言模型,它能够让你轻松地调用一个工具来生成或查找各种名人的励志名言,特别是关于爱情、梦想和成功的话语。例如,其中一个例子返回了:“成功不是终点,失败也不是致命的:真正重要的是继续前进的勇气。”–丘吉尔
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试,不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









