



BERT 是 Bidirectional Encoder Representations from Transformers 的缩写,是一种为自然语言处理 (NLP) 领域设计的开源机器学习框架。该框架起源于 2018 年,由 Google AI Language 的研究人员精心打造。本文旨在探索 BERT 的架构、工作原理和应用。

一、什么是 BERT?
BERT 利用基于 Transformer 的神经网络来理解和生成类似人类的语言。BERT 采用仅编码器的架构。在原始 Transformer 架构中,既有编码器模块,也有解码器模块。在 BERT 中使用仅编码器架构的决定表明主要强调理解输入序列而不是生成输出序列。
1、BERT 的双向方法
传统语言模型按顺序处理文本,从左到右或从右到左。这种方法将模型的感知限制在目标词之前的直接上下文中。BERT 使用双向方法(B 就是 Bidirectional(双向)),同时考虑句子中单词的左右上下文,而不是按顺序分析文本,BERT 同时查看句子中的所有单词。
例如:“The bank is situated on the _______ of the river.”
在单向模型中,对空白的理解将严重依赖于前面的单词,并且模型可能难以辨别“bank”是指银行还是河的一侧。
BERT 是双向的,它同时考虑左侧(“The bank is situated on the”)和右侧上下文(“of the river”),从而实现更细致的理解。它理解缺失的单词可能与银行的地理位置有关,展示了双向方法带来的语境丰富性。
2、预训练和微调
BERT 模型经历了两个步骤:
-
对大量未标记的文本进行预训练,以学习上下文嵌入。
-
对标记数据进行微调,以执行特定的 NLP 任务。
对大数据进行预训练
-
BERT 是在大量未标记的文本数据上进行预训练的。该模型学习上下文嵌入,即考虑句子中周围上下文的单词表示。
-
BERT 参与各种无监督的预训练任务。例如,它可能学习预测句子中缺失的单词(掩码语言模型(Masked Language Model)或 MLM 任务)、理解两个句子之间的关系或预测一对句子中的下一个句子。
对标记数据进行微调
-
在预训练阶段之后,BERT 模型在其上下文嵌入的帮助下,针对特定的自然语言处理 (NLP) 任务进行微调。此步骤通过调整模型的一般语言理解以适应特定任务的细微差别,使模型适合更有针对性的应用。
-
BERT 使用与下游特定任务相关的标记数据进行微调。这些任务可能包括情绪分析、问答、命名实体识别或任何其他 NLP 应用程序。模型的参数经过调整,以优化其性能以满足当前任务的特定要求。
BERT 的统一架构使其能够以最小的修改适应各种下游任务,使其成为自然语言理解和处理中多功能且高效的工具。
二、BERT 的工作原理
BERT 旨在生成语言模型,因此仅使用编码器机制。将 token 序列输入到 Transformer 编码器。这些 token 首先嵌入到向量中,然后在神经网络中处理。输出是一系列向量,每个向量对应一个输入 token,提供上下文化表示。
在训练语言模型时,定义预测目标是一项挑战。许多模型会预测序列中的下一个单词,这是一种定向方法,可能会限制上下文学习。BERT 通过两种创新的训练策略解决了这一挑战:
-
掩码语言模型 (Masked Language Model,MLM)
-
预测下一句 (Next Sentence Prediction,NSP)
1. MLM
在 BERT 的预训练过程中,每个输入序列中的一部分单词被屏蔽(掩码),并训练模型根据周围单词提供的上下文预测这些掩码单词的原始值。
简单来说,
-
掩码单词:在 BERT 从句子中学习之前,它会隐藏一些单词(约 15%)并用特殊符号替换它们,例如 [MASK]。
-
猜测隐藏的单词:BERT 的工作是通过查看周围的单词来找出这些隐藏的单词是什么。这就像一场猜测某些单词缺失的游戏,BERT 会尝试填补空白。
-
BERT 如何学习:
-
BERT 在其学习系统之上添加了一个特殊层来做出这些猜测。然后,它会检查其猜测与实际隐藏的单词有多接近
-
它通过将猜测转换为概率来实现这一点,说“我认为这个单词是 X,我对此非常确定。”
4 特别关注隐藏的单词
-
BERT 在训练期间的主要重点是正确获取这些隐藏的单词。它不太关心预测未隐藏的单词。
-
这是因为真正的挑战是找出缺失的部分,这种策略有助于 BERT 真正理解单词的含义和上下文。
从技术角度来说,
-
BERT 在编码器的输出之上添加了一个分类层。这一层对于预测掩码词至关重要。
-
分类层的输出向量与嵌入矩阵相乘,将它们转换为词汇维度。此步骤有助于将预测的表示与词汇空间对齐。
-
使用 SoftMax 激活函数计算词汇表中每个单词的概率。此步骤为每个掩码位置生成整个词汇表的概率分布。
-
训练期间使用的损失函数仅考虑掩码值的预测。该模型因其预测与掩码词的实际值之间的偏差而受到惩罚。
-
该模型的收敛速度比定向模型慢。这是因为在训练期间,BERT 只关心预测掩码值,而忽略非掩码词的预测。通过这种策略实现的增强的环境意识弥补了较慢的收敛速度。
2. NSP
BERT 预测第二句是否与第一句相连。这是通过使用分类层将 [CLS] 标记的输出转换为 2×1 形状的向量,然后使用 SoftMax 计算第二句是否跟在第一句后面的概率来实现的。
-
在训练过程中,BERT 学习理解句子对之间的关系,预测第二句是否跟在原始文档中的第一句后面。
-
50% 的输入对将第二句作为原始文档中的后续句子,而另外 50% 的输入对具有随机选择的句子。
-
为了帮助模型区分连接和断开的句子对。在进入模型之前对输入进行处理:
-
在第一句的开头插入 [CLS] token,并在每个句子的末尾添加 [SEP] 标记。
-
在每个 token 中添加表示句子 A 或句子 B 的句子嵌入。
-
位置嵌入指示每个 token 在序列中的位置。
- BERT 预测第二句是否与第一句相连。这是通过使用分类层将 [CLS] token 的输出转换为 2×1 形状的向量来实现的,然后使用 SoftMax 计算第二句是否跟在第一句后面的概率。
在 BERT 模型的训练过程中,MLM 和 NSP 一起训练。该模型旨在最小化 MLM 和 NSP 的组合损失函数,从而形成一个强大的语言模型,增强了理解句子内上下文和句子间关系的能力。
为什么要一起训练 MLM 和 NSP?
MLM 帮助 BERT 理解句子内的上下文,NSP 帮助 BERT 掌握句子对之间的联系或关系。因此,同时训练这两种策略可确保 BERT 学习对语言的广泛而全面的理解,捕捉句子内的细节和句子之间的流程。
三、BERT 架构
BERT 的架构是一个多层双向 Transformer 编码器,与 Transformer 模型非常相似。Transformer 架构是一个编码器-解码器网络,在编码器端使用自注意力,在解码器端使用注意力。
-
BERT-BASE 在编码器堆栈中有 12 层,而 BERT-LARGE 在编码器堆栈中有 24 层。这些比原始论文中描述的 Transformer 架构(6 个编码器层)更多。
-
BERT 架构(BASE 和 LARGE)还具有比原始论文中建议的 Transformer 架构更大的前馈网络(分别为 768 个和 1024 个隐藏单元)和更多的注意力头(分别为 12 个和 16 个)。它包含 512 个隐藏单元和 8 个注意力头。
-
BERT-BASE 包含 110M 个参数,而 BERT-LARGE 包含 340M 个参数。

BERT-BASE 和 BERT-LARGE 架构
该模型首先将 CLS token 作为输入,然后将一系列单词作为输入。这里 CLS 是一个分类标记。然后它将输入传递到上面的层。每一层都应用自注意力机制,并将结果通过前馈网络传递,然后将其传递给下一个编码器。该模型输出一个隐藏大小的向量(BERT-BASE 为 768)。如果我们想从这个模型输出一个分类器,我们可以获取与 CLS token 相对应的输出。
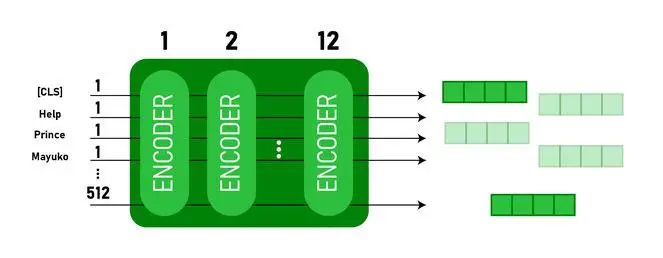
BERT 的嵌入向量输出
现在,这个训练好的嵌入向量可以用来执行分类、翻译等一系列任务。
四、如何在 NLP 任务中使用 BERT 模型?
BERT 可用于各种自然语言处理 (NLP) 任务,例如:
1. 分类任务
-
BERT 可用于情绪分析等分类任务,目标是将文本分为不同的类别(正面/负面/中性),可通过在 [CLS] token 的 Transformer 输出顶部添加分类层来使用 BERT。
-
[CLS] token表示来自整个输入序列的聚合信息。然后,可以将此池化表示用作分类层的输入,以对特定任务进行预测。
2. 问答
-
在问答任务中,模型需要在给定的文本序列中定位和标记答案,可以为此目的训练 BERT。
-
BERT 通过学习标记答案开头和结尾的两个附加向量来训练问答。在训练期间,为模型提供问题和相应的段落,并学习预测段落中答案的开始和结束位置。
3. 命名实体识别 (NER)
-
BERT 可用于 NER,其目标是识别和分类文本序列中的实体(例如,人员、组织、日期)。
-
基于 BERT 的 NER 模型通过从 Transformer 获取每个 token 的输出向量并将其输入到分类层来进行训练。该层预测每个 token 的命名实体标签,指示其代表的实体类型。
五、使用 BERT 对文本 tokenize 和编码
我们将借助 Python 中的“transformer”库使用 BERT 对文本进行 tokenize (就是生成文本的 token)和编码。
安装 transformers 的命令:
pip install transformers
-
我们将使用 BertTokenizer.from_pretrained(“bert-base-cased”) 加载预训练的 BERT tokenize 和带大小写的词汇表。
-
tokenizer.encode(text) 对输入文本进行 tokenize 并将其转换为 token ID 序列。
-
print(“Token IDs:”, encoding) 打印编码后获得的 token ID。
-
tokenizer.convert_ids_to_tokens(encoding) 将 token ID 转换回其对应的 token。
-
print(“Tokens:”, tokens) 打印转换 token ID 后获得的 token
from transformers import BertTokenizer
# Load pre-trained BERT tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
# Input text
text = 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '
# Tokenize and encode the text
encoding = tokenizer.encode(text)
# Print the token IDs
print("Token IDs:", encoding)
# Convert token IDs back to tokens
tokens = tokenizer.convert_ids_to_tokens(encoding)
# Print the corresponding tokens
print("Tokens:", tokens)

tokenizer.encode 方法在编码序列的开始和结束处添加特殊的
-
[CLS] – 分类标记
-
[SEP] – 分隔符标记
六、BERT 的应用场景
BERT 可用于多种 NLP 任务:
-
文本表示:BERT 用于生成单词嵌入或句子中单词的表示。
-
命名实体识别 (NER):BERT 可以针对命名实体识别任务进行微调,其目标是在给定文本中识别诸如人名、组织、位置等实体。
-
文本分类:BERT 广泛用于文本分类任务,包括情绪分析、垃圾邮件检测和主题分类。它在理解和分类文本数据上下文方面表现出色。
-
问答系统:BERT 已应用于问答系统,其中模型经过训练以理解问题的上下文并提供相关答案。这对于阅读理解等任务特别有用。
-
机器翻译:BERT 的上下文嵌入可用于改进机器翻译系统。该模型捕捉了对准确翻译至关重要的语言细微差别。
-
文本摘要:BERT 可用于抽象文本摘要,其中模型通过理解上下文和语义来生成较长文本的简洁而有意义的摘要。
-
对话式 AI:BERT 用于构建对话式 AI 系统,例如聊天机器人、虚拟助手和对话系统。它掌握上下文的能力使其能够有效地理解和生成自然语言响应。
-
语义相似性:BERT 嵌入可用于测量句子或文档之间的语义相似性。这在重复检测、释义识别和信息检索等任务中很有价值。
七、BERT vs GPT
BERT 和 GPT 的区别如下:
| BERT | GPT | |
| 架构 | BERT 专为双向表征学习而设计。它使用掩码语言模型目标,根据左右上下文预测句子中缺失的单词。 | 另一方面,GPT 是为生成式语言建模而设计的。它利用单向自回归方法,根据前面的上下文预测句子中的下一个单词。 |
| 预训练目标 | BERT 使用掩码语言模型目标和下一句预测进行预训练。它专注于捕捉双向上下文并理解句子中单词之间的关系。 | GPT 经过预先训练,可以预测句子中的下一个单词,这有助于模型学习语言的连贯表示并生成上下文相关的序列。 |
| 上下文理解 | BERT 对于需要深入理解句子内的上下文和关系的任务非常有效,例如文本分类、命名实体识别和问答。 | GPT 擅长生成连贯且上下文相关的文本。它常用于创意任务、对话系统和需要生成自然语言序列的任务。 |
| 任务类型和用例 | 常用于文本分类、命名实体识别、情感分析和问答等任务。 | 应用于文本生成、对话系统、总结和创意写作等任务。 |
| 微调与小样本学习 | BERT 通常使用标记数据针对特定的下游任务进行微调,以使其预训练表示适应当前的任务。 | GPT 旨在执行小样本学习,它可以用最少的特定任务训练数据推广到新任务。 |
BERT vs GPT
问:BERT 有什么用?
BERT 用于执行 NLP 任务,如文本表示、命名实体识别、文本分类、问答系统、机器翻译、文本摘要等。
问:BERT 模型有什么优势?
BERT 语言模型因其对多种语言的广泛预训练而脱颖而出,与其他模型相比,它提供了广泛的语言覆盖范围。这使得 BERT 对于非英语项目特别有利,因为它提供了跨多种语言的强大上下文表示和语义理解,增强了其在多语言应用中的多功能性。
问:BERT 如何用于情绪分析?
BERT 通过利用其双向表示学习来捕捉给定文本中的上下文细微差别、语义含义和句法结构,在情绪分析方面表现出色。这使 BERT 能够通过考虑单词之间的关系来理解句子中表达的情绪,从而产生高效的情绪分析结果。
问:谷歌是基于 BERT 的吗?
BERT 和 RankBrain 是 Google 搜索算法的组成部分,用于处理查询和网页内容,以便更好地理解并改善搜索结果。
八、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









