






本文对 llm 如何进行长文本训练,进行一些基础知识的普及,并提供一些最简单的代码来解释原理。如果想要深入了解其中门道,还需要读者自行研究 megatron、deepspeed、flash-attention 等源码。
我们从这几个问题进行探讨:
- 为什么要进行长文本训练?
- 长文本训练有什么难度?
- 各大框架都是怎么做的?
一、为什么长文本
工业界对长文本的需求不用过多赘述,论文解读、RAG、多模态、文学创作等任务,动辄就是一个 query 好几千的 token 量。这种情况下,谁家的模型在长文本下效果好,自然就能提供给用户更好的体验。
在 2023 年的时候,大多长文本的工作还是围绕着 “ ROPE 的外推” 来进行,这里最经典的工作莫过于 NTK 了。不过时至今日,大家似乎倾向于更加返璞归真的做法:我直接在 pretrain / postrain /sft 阶段训一个 long-context 模型,不是思路更简单、模型效果更好吗?答案似乎也是肯定的。
二、长文本的难点
经常训 llm 的同学都知道,OOM 是要命的。为了能训更大的模型,各大主流框架几乎是卯足了劲来优化显存:megatron 的 pipeline_parallel 和 tensor_parallel 、deepspeed 的 zero 技术、offload,gradient checkpoint、混合精度、 等等等等。
然而,这些传统技术在 long-context 面前基本是治标不治本的存在:
-
13B 模型和 7B 模型相比较,参数只增加了 1 倍,也就是说我们只要把 pipeline_parallel 的倍数调大一倍,以前怎么训,现在就还怎么训,无非就是 data_parallel 的数量减半了而已(由于有优化器、梯度等额外存储在,显存压力并不是提升一倍这么简单,这里不做过多展开);
-
4K 的文本和 40K 的文本,attention 矩阵的大小,可是相差了
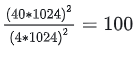
倍,更别说部分公司可能都在用 400K 这个量级的长度。
这也就是说,如果优化不了 seq_len * seq_len 这个量级的参数量,那么 long-context llm 是必然没法训练的。然而 attention 层的 softmax 操作,又要求模型必须在一张 GPU 上见到完整的 sequence,这似乎是条死路。
三、主流框架怎么做的
时势造英雄,sequence_parallel 和 ring_attention 应运而生(这里特指 deepspeed 中的 sequence_parallel,它在 megatron 中叫 context_parallel )。
sequence_parallel
顾名思义,sequence_parallel (sp) 就是在 sequence 维度上对 tensor 进行切分,放到不同的卡上运算:
batch * seq_len * head_num * head_dim —> batch * ( seq_len / / sp_size ) * head_num * head_dim
这个思路不仅简单,而且在 llama 模型的三件套 ( Attention、 MLP、RMSNorm) 中,后两个模块本身就是只对 tensor 的最后一个维度进行操作,天然支持 sp 并行。
# valid MLP sequence_parallel
import torch.nn as nn
import torch
class MLP(nn.Module):
def __init__(self, hidden_size, intermediate_size):
super().__init__()
self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)
self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
self.act_fn = nn.SiLU()
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
mlp = MLP(10, 20)
x = torch.randn(3, 4, 10)
x1, x2 = x.split(2, dim=1)
assert torch.equal(mlp(x), torch.cat((mlp(x1), mlp(x2)), dim=1))
# valid RMS_norm sequence_parallel
class RMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states
norm = RMSNorm(10)
x = torch.randn(3, 4, 10)
x1, x2 = x.split(2, dim=1)
assert torch.equal(norm(x), torch.cat((norm(x1),norm(x2)), dim=1))
那么重点来了,如何实现 Attention 的 sp?deepspeed 给出了一种简单且优雅的方案:
在 Attention 之前,借助all2all通信,把 batch * ( seq_len / / sp_size ) * head_num * head_dim 的 q、k、v 三个tensor 变成 batch * seq_len * (head_num // sp_size) * head_dim 的 tensor,并在计算完 attention 之后,再次all2all通信交换维度:
- before attention:batch * ( seq_len / / sp_size ) * head_num * head_dim
- during attention:batch * seq_len * (head_num // sp_size) * head_dim
- after attention: batch * ( seq_len / / sp_size ) * head_num * head_dim
# sp 的all2all通信,注意 scater_idx 和 gather_idx
def forward(self, spg, query, key, value, *args, **kwargs) :
""" forward
Arguments: query (Tensor): query input to the layer key (Tensor): key input to the layer value (Tensor): value input to the layer args: other args
Returns: * output (Tensor): context output """
# before attn: [bz, s/p, nh, hd]
query_layer = self._seq_alltoall.apply(spg, query, scatter_idx=2, gather_idx=1)
key_layer = self._seq_alltoall.apply(spg, key, scatter_idx=2, gather_idx=1)
value_layer = self._seq_alltoall.apply(spg, value, scatter_idx=2, gather_idx=1)
# during attn: [bz, s, nh/p, hd]
context_layer = self.attn(query_layer, key_layer, value_layer, *args, **kwargs)
# after attn: [bz, s/p, nh, hd]
output = self._seq_alltoall.apply(spg, context_layer, scatter_idx=1, gather_idx=2)
return output
# 上述函数中的 self._seq_alltoall 最终会调用下面这个 single_all_to_all 函数
def single_all_to_all(input, scatter_idx, gather_idx, group):
seq_world_size = dist.get_world_size(group)
inp_shape = list(input.shape)
inp_shape[scatter_idx] = inp_shape[scatter_idx] // seq_world_size
if scatter_idx < 2:
input_t = input.reshape(
[seq_world_size, inp_shape[scatter_idx]] + \
inp_shape[scatter_idx + 1:]
).contiguous()
else:
# transpose groups of heads with the seq-len parallel dimension, so that we can scatter them!
input_t = input.reshape(
[-1, seq_world_size, inp_shape[scatter_idx]] + \
inp_shape[scatter_idx + 1:]
).transpose(0, 1).contiguous()
output = torch.empty_like(input_t)
dist.all_to_all_single(output, input_t, group=group)
# if scattering the seq-dim, transpose the heads back to the original dimension
if scatter_idx < 2:
output = output.transpose(0, 2).contiguous()
return output.reshape(
inp_shape[: gather_idx] + \
[inp_shape[gather_idx] * seq_world_size,] + \
inp_shape[gather_idx + 1:]).contiguous()
也就是说,计算 attention 的时候,单卡依然看得见整个 sequence 序列,只不过以前单卡处理 num_head 个 attention 头,现在只处理 num_head // sp_size 个 attention 头。
虽然没有在源码中没看见 assert num_head % sp_size == 0 的代码逻辑,但我有理由怀疑这是 sequence_parallel 能正常运作的潜在条件 。
(贴一下chatgpt老师的理解,它无敌了!它迟早知道自己是怎么训练出来的)


ring_attention
不同于 sp 并行,ring_attention 另辟蹊径,从根源上解决问题:既然 softmax 函数是 attention 必须见到完整的 sequence 的罪魁祸首,那我就“改造”下它的运算方式。用一句戏言来概括,ring_attention 成功就成功在它没有选择调包实现 softmax,而是选择手动实现 softmax
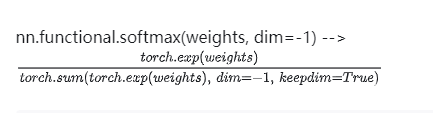
# ring_attention 原理理解
import torch
import torch.nn as nn
import math
B, L, D = 3, 6, 10
Q, K, V = torch.randn(B, L, D), torch.randn(B, L, D), torch.randn(B, L, D)
Q_1, Q_2, Q_3 = torch.split(Q, L // 3, dim=1)
K_1, K_2, K_3 = torch.split(K, L // 3, dim=1)
V_1, V_2, V_3 = torch.split(V, L // 3, dim=1)
def attn(Q, K, V):
attn_weights = torch.matmul(Q, K.transpose(1,2)) / math.sqrt(D)
# 计算分子
numerator = torch.exp(attn_weights)
# 计算分母
denominator = torch.sum(numerator, dim=-1, keepdim=True)
# 计算softmax
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
return torch.matmul(numerator, V), denominator, torch.matmul(attn_weights, V)
A, B, all_attn = attn(Q, K, V)
# 第一个 attn 块
A11, B11, attn_11 = attn(Q_1, K_1, V_1)
A12, B12, attn_12 = attn(Q_1, K_2, V_2)
A13, B13, attn_13 = attn(Q_1, K_3, V_3)
A1 = A11 + A12 + A13
B1 = B11 + B12 + B13
# 第二个 attn 块
A21, B21, attn_21 = attn(Q_2, K_1, V_1)
A22, B22, attn_22 = attn(Q_2, K_2, V_2)
A23, B23, attn_23 = attn(Q_2, K_3, V_3)
A2 = A21 + A22 + A23
B2 = B21 + B22 + B23
# 第三个 attn 块
A31, B31, attn_31 = attn(Q_3, K_1, V_1)
A32, B32, attn_32 = attn(Q_3, K_2, V_2)
A33, B33, attn_33 = attn(Q_3, K_3, V_3)
A3 = A31 + A32 + A33
B3 = B31 + B32 + B33
# 合并三个 attn 块
merge_A_1_2_3 = torch.cat((A1, A2, A3), dim=1)
merge_B_1_2_3 = torch.cat((B1, B2, B3), dim=1)
merge_attn_1_2_3 = merge_A_1_2_3 / merge_B_1_2_3
ring_attn = torch.cat((A1 / B1, A2 / B2, A3 / B3), dim=1)
# 因为精度问题,两个 attn 并不严格相等,就不用 assert 验证了
print(all_attn)
print(ring_attn)

最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试,不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









