






4. Meta AI的Llama 3.1
论文地址:https://arxiv.org/abs/2407.21783
Meta的新款Llama LLMs发布总是备受关注。这次发布还附带了一份92页的技术报告:The Llama 3 Herd of Models。最后但同样重要的是,在本节中,我们将看看上个月发布的第四篇重要模型论文。
4.1 Llama 3.1 概述
除了发布一个巨大的4050亿参数模型外,Meta还更新了之前的80亿和700亿参数模型,使它们的MMLU性能稍有提升。
不同模型的MMLU基准性能。
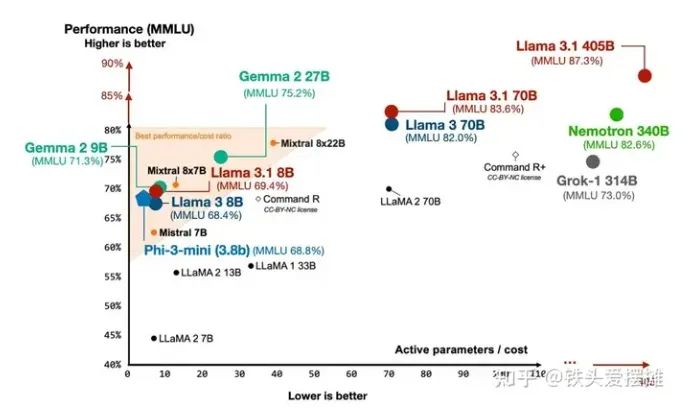
尽管Llama 3使用了与其他最近的LLM类似的组查询注意力,令人惊讶的是,Meta AI对滑动窗口注意力和专家混合方法说不。换句话说,Llama 3.1 看起来非常传统,重点显然是放在预训练和后训练上,而不是架构创新。
与之前的Llama版本类似,权重是公开可用的。此外,Meta表示他们更新了Llama 3的许可证,现在终于可以(允许)使用Llama 3进行合成数据生成或知识蒸馏以改进其他模型。
4.2 Llama 3.1 预训练
Llama 3在一个巨大的15.6万亿标记数据集上进行了训练,这比Llama 2的1.8万亿标记有了大幅增加。研究人员表示,它支持至少八种语言(而Qwen 2能够处理20种语言)。
Llama 3一个有趣的方面是其128,000的词汇量,这是使用OpenAI的tiktoken分词器开发的。(对于那些对分词器性能感兴趣的人,我在这里做了一个简单的基准比较。)
在预训练数据质量控制方面,Llama 3采用基于启发式的过滤和基于模型的质量过滤,利用像Meta AI的fastText和基于RoBERTa的分类器等快速分类器。这些分类器还帮助确定训练过程中使用的数据混合的上下文类别。
Llama 3的预训练分为三个阶段。第一阶段涉及使用15.6万亿标记和8k上下文窗口的标准初始预训练。第二阶段继续预训练,但将上下文长度扩展到128k。最后阶段涉及退火,进一步提高模型的性能。让我们在下面详细了解这些阶段。
4.2.1 预训练 I: 标准(初始)预训练
在他们的训练设置中,他们开始使用包含400万标记的批次,每个批次的序列长度为4096。这意味着假设400万的数字四舍五入,批次大小约为1024标记。在处理了前252百万标记后,他们将序列长度加倍到8192。在训练过程中,处理了2.87万亿标记后,他们再次将批次大小加倍。
此外,研究人员在整个训练过程中没有保持数据混合不变。相反,他们在训练过程中调整了数据混合,以优化模型的学习和性能。这种动态的数据处理方法可能有助于提高模型在不同类型数据上的泛化能力。
4.2.2 预训练 II: 继续预训练以延长上下文
与其他一次性增加上下文窗口的模型相比,Llama 3.1的上下文延长采取了更渐进的方法:在这里,研究人员通过六个不同阶段将上下文长度从8,000增加到128,000标记。这种逐步增加可能使模型更顺利地适应较大的上下文。
用于此过程的训练集涉及8000亿标记,大约占整个数据集大小的5%。
4.2.3 预训练 III: 在高质量数据上退火
在第三阶段的预训练中,研究人员使用了一个小但高质量的混合数据集进行训练,他们发现这有助于提高在基准数据集上的性能。例如,在GSM8K和MATH训练集上退火显著提高了各自的GSM8K和MATH验证集的性能。
在论文的第3.1.3节中,研究人员表示退火数据集的大小为400亿标记(占整个数据集大小的0.02%)。然而,在第3.4.3节中,他们表示退火仅在4000万标记(0.1%的退火数据)上进行。
Llama 3.1 预训练技术的总结。
4.3 Llama 3.1 后训练
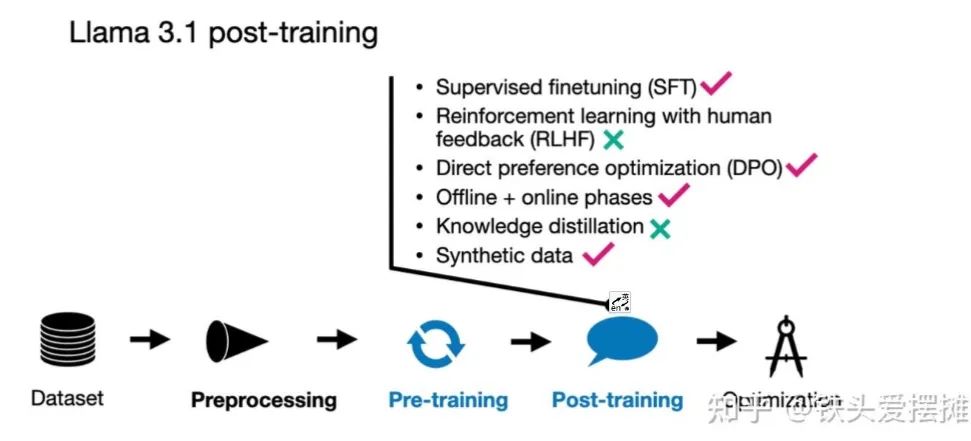
在后训练过程中,Meta AI 团队采用了一种相对简单的方法,包括监督微调 (SFT)、拒绝采样和直接偏好优化 (DPO)。
他们观察到,与这些技术相比,像 RLHF 与 PPO 这样的强化学习算法稳定性较差,且更难扩展。值得注意的是,SFT 和 DPO 步骤在多个回合中反复进行,结合了人类生成的数据和合成数据。
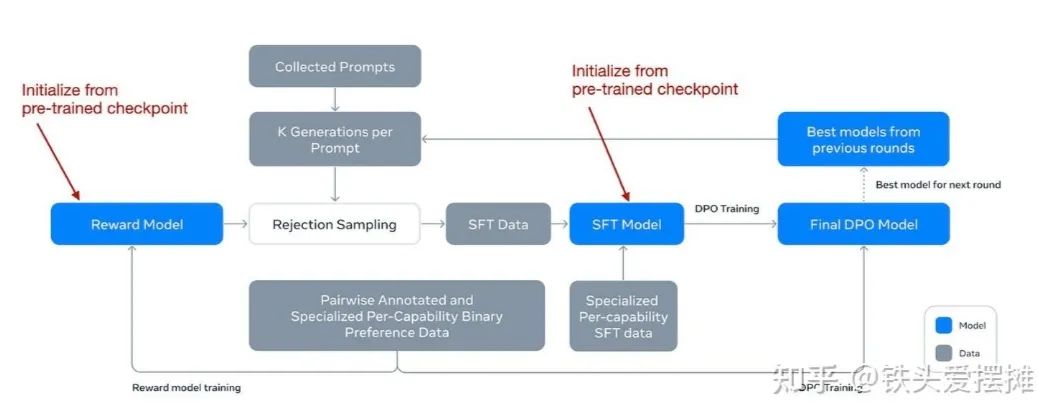
在描述进一步的细节之前,他们的工作流程在下图中有所说明。
Llama 3.1 论文中的注释图,描述了后训练过程
请注意,尽管他们使用了DPO,他们还开发了一个奖励模型,就像在RLHF中那样。最初,他们使用预训练阶段的检查点并利用人工注释数据来训练奖励模型。然后,这个奖励模型被用于拒绝采样过程,以帮助选择适当的提示进行进一步训练。
在每一轮训练中,他们不仅对奖励模型应用了模型平均技术,还对SFT和DPO模型应用了这种技术。这种平均包括将最近和以前模型的参数合并,以稳定(并改善)性能。
对于那些对模型平均的技术细节感兴趣的人,我在之前的文章 Model Merging, Mixtures of Experts, and Towards Smaller LLMs 的 “Understanding Model Merging and Weight Averaging” 部分中讨论了这个话题。
总而言之,核心是一种相对标准的SFT + DPO阶段。然而,这个阶段会重复多轮。然后,他们加入了一个用于拒绝采样的奖励模型(像Qwen 2和AFM)。他们还使用了像Gemma那样的模型平均技术;不过,这不仅仅是针对奖励模型,而是所有相关模型。
Llama 3.1后训练的技术总结。
4.4 结论
Llama 3 模型仍然相当标准,并且与早期的 Llama 2 模型相似,但有一些有趣的方法。特别是,庞大的 15 万亿标记训练集使 Llama 3 与其他模型区分开来。有趣的是,像苹果的 AFM 模型一样,Llama 3 也实施了三阶段的预训练过程。
与其他最近的大型语言模型相比,Llama 3 没有采用知识蒸馏技术,而是选择了更为直接的模型开发路径。在后训练阶段,该模型使用了直接偏好优化(DPO)而不是在其他模型中流行的更复杂的强化学习策略。总体而言,这一选择很有趣,因为它表明了通过更简单(但经过验证)的方法来改进 LLM 性能的关注点。
5. 主要收获
我们可以从本文讨论的这四个模型中学到什么:阿里巴巴的 Qwen 2、苹果的基础模型(AFM)、谷歌的 Gemma 2 和 Meta 的 Llama 3?
这四个模型在预训练和后训练方面采取了不同的方法。当然,方法论有所重叠,但没有一个训练管道完全相同。在预训练方面,一个共同的特征似乎是所有方法都使用多阶段的预训练管道,其中一般的核心预训练之后是上下文延长,有时还有高质量的退火步骤。下图再次展示了预训练中采用的不同方法的一览。
预训练中使用的技术概述

当谈到后训练时,没有一个流程是完全相同的。似乎拒绝采样现在是后训练过程中常见的做法。然而,当谈到DPO或RLHF时,目前还没有一致的意见或偏好。
后训练技术概述

总之,没有单一的配方来开发高性能的LLM,而是有许多途径。
最后,这四个模型的表现大致相当。不幸的是,其中一些模型尚未进入LMSYS和AlpacaEval排行榜,因此我们还没有直接的比较,除了在多项选择基准测试如MMLU等上的得分外。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试,不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









