






随着人工智能的迅速发展,AI问答模型在各类应用场景中表现出色,特别是在信息检索和知识问答领域,传统的检索增强生成(RAG)模型通过结合外部知识库的实时检索和生成技术,显著提高了回答的准确性。然而,这类模型在处理长期信息上存在局限,尤其是在需要持续记忆和动态更新知识的复杂场景中表现欠佳。
为应对这一挑战,MemoRAG应运而生。MemoRAG不仅继承了RAG模型的优势,还通过引入“长期记忆”机制,突破了AI模型对历史信息的局限,使其能够更好地应对复杂问题和长时间任务的需求。MemoRAG通过将信息存储为“记忆”,实现对长期数据的动态更新和检索,从而在个性化问答、知识管理以及任务跟踪等方面展现出显著优势。其“长期记忆”机制不仅使模型更具灵活性,还能更精准地响应用户的动态信息需求。

本文将深入探讨MemoRAG的核心技术原理及其应用场景,并分析MemoRAG如何通过“长期记忆”重塑AI问答模型的能力。我们还将对比MemoRAG与其他RAG模型的不同之处,展示其在未来人工智能发展中的潜力和价值。
MemoRAG 介绍
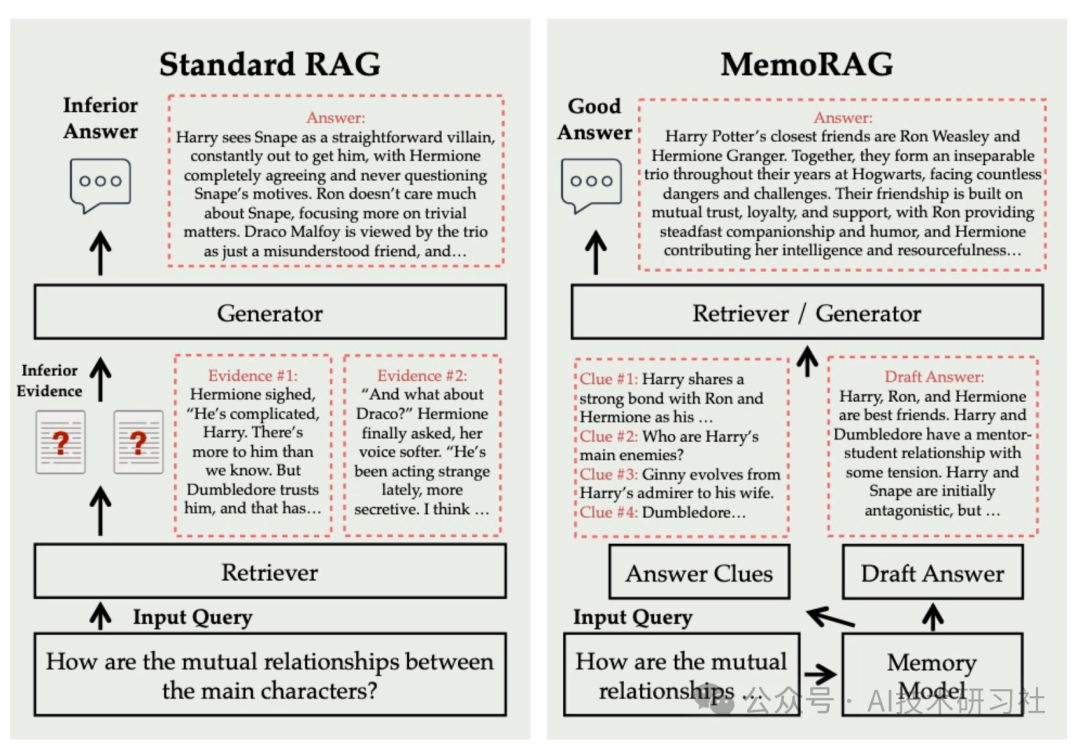
MemoRAG 是一个创新的 RAG 框架,建立在高效、超长的内存模型之上。与主要处理具有明确信息需求的查询的标准 RAG 不同,MemoRAG 利用其内存模型来实现对整个数据库的全局理解。
通过从记忆中调用特定于查询的线索,MemoRAG 增强了证据检索,从而生成更准确且上下文更丰富的响应。
要使用 Memorizer 和 MemoRAG,您需要安装 Python 以及所需的库。您可以使用以下命令安装必要的依赖项:
pip install torch==2.3.1
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
MemoRAG 易于使用,可以直接使用 HuggingFace 模型进行初始化。通过使用 MemoRAG.memorize() 方法,内存模型在较长的 input 上下文中构建全局内存。根据经验,使用默认参数设置, TommyChien/memorag-qwen2-7b-inst 可以处理多达 400K 个令牌的上下文,同时 TommyChien/memorag-mistral-7b-inst 可以管理多达 128K 个令牌的上下文。通过增加 beacon_ratio 参数,可以扩展模型处理较长上下文的能力。例如, TommyChien/memorag-qwen2-7b-inst 可以处理多达 100 万个令牌(beacon_ratio=16)。
from memorag import MemoRAG
# Initialize MemoRAG pipeline
pipe = MemoRAG(
mem_model_name_or_path="TommyChien/memorag-mistral-7b-inst",
ret_model_name_or_path="BAAI/bge-m3",
gen_model_name_or_path="mistralai/Mistral-7B-Instruct-v0.2", # Optional: if not specify, use memery model as the generator
cache_dir="path_to_model_cache", # Optional: specify local model cache directory
access_token="hugging_face_access_token", # Optional: Hugging Face access token
beacon_ratio=4
)
context = open("examples/harry_potter.txt").read()
query = "How many times is the Chamber of Secrets opened in the book?"
# Memorize the context and save to cache
pipe.memorize(context, save_dir="cache/harry_potter/", print_stats=True)
# Generate response using the memorized context
res = pipe(context=context, query=query, task_type="memorag", max_new_tokens=256)
print(f"MemoRAG generated answer: \n{res}")
运行上述代码时,编码的键值 (KV) 缓存、Faiss 索引和分块段落存储在指定的save_dir中。之后,如果再次使用相同的上下文,则可以从磁盘快速加载数据:
pipe.load("cache/harry_potter/", print_stats=True)
更多内容参考项目:https://github.com/qhjqhj00/MemoRAG
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









