






一、背景
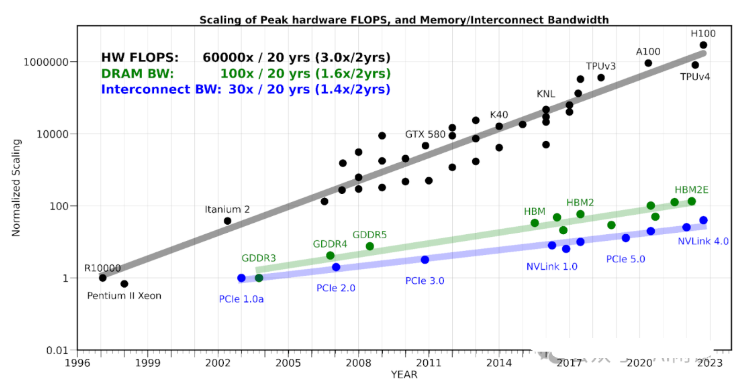
在大规模分布式训练场景中,计算和通信的重叠(Overlap)一直是一个关键的研究热点。随着硬件性能的提升,计算能力和通信带宽之间的差距日益显著。如下图所示,硬件算力每 2 年大约扩大 3x,而通信带宽每 2 年只提升 1.4x,这种差距带来的影响在大规模训练任务中愈加明显。例如,在使用 H100 和 A100 集群进行 LLM 训练时,H100 的通信开销占比通常会高于 A100。这种情况下,通信可能成为了系统性能的瓶颈,因此,如何在计算和通信之间实现高效的 Overlap,已成为优化分布式训练性能的关键策略之一。
实际上,大部分计算和通信的 Overlap 可以理解为生产者和消费者的 Overlap,生产者可以是计算也可以是通信,生产者与消费者可以是短程依赖也可以是长程依赖,通常短程依赖带来的挑战更大,而长程依赖则较容易实现 Overlap。比如:
-
张量并行(Tensor Parallelism,TP)中的 MatMul 计算与 AllReduce 通信就是一个明显的短程依赖,AllReduce 通信依赖 MatMul 的计算,并且 AllReduce 通信又会阻塞后续的计算操作。
-
Deepspeed Zero 的模型切分通信与计算可以看作是一种长程依赖。在这种情况下,只要保证 Layer N 计算之前拿到权重即可,完全可以提前获取权重,避免等到实际开始计算时再进行通信。通过这种方式,通信可以在更早的阶段与之前的计算操作进行重叠,从而更高效地利用计算和通信资源。
本文中我们简单介绍一系列针对大规模训练场景的计算与通信 Overlap 来优化训练性能的工作,包括 Microsoft 的 CoCoNet、Domino,Google 的 Intra-layer Overlapping via Kernel Fusion,AMD 的 T3,北大的 Centauri,字节的 Flux 以及中科大的 DHelix 等。
二、引言
2.1 AllReduce
AllReduce 是集合通信中常见的分布式计算操作,用于多个设备(比如多个 GPU)之间聚合数据的场景,可以包含 Sum、Min、Max 等操作。
对于常见的基于 Ring 的 AllReduce 实现中,通常可以把 AllReduce 操作看成为一个 ReduceScatter 和一个 AllGather 操作,如下图所示:
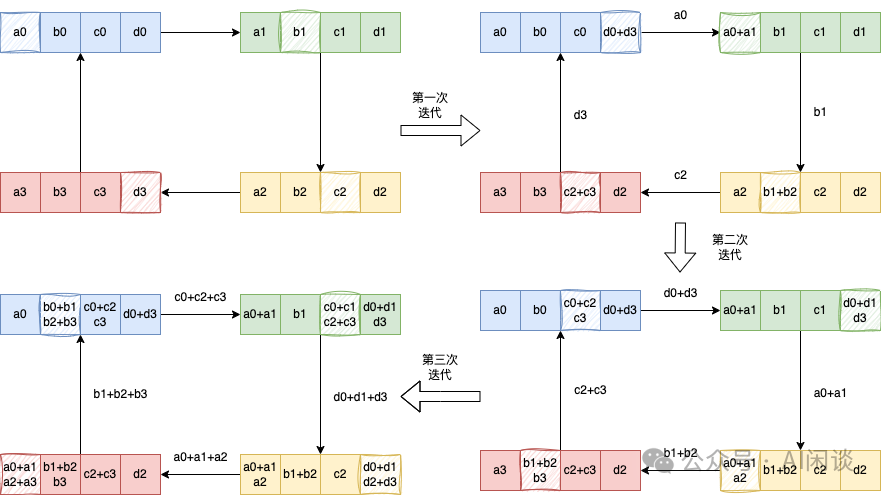
具体的 ReduceScatter 操作如下,每个设备(GPU)发送一部分数据给下一个设备,同时接收上一个设备的数据并累加。这个过程进行 K-1 步(假设有 K 个设备),ReduceScatter 后每个设备都包含一部分数据的 Sum:
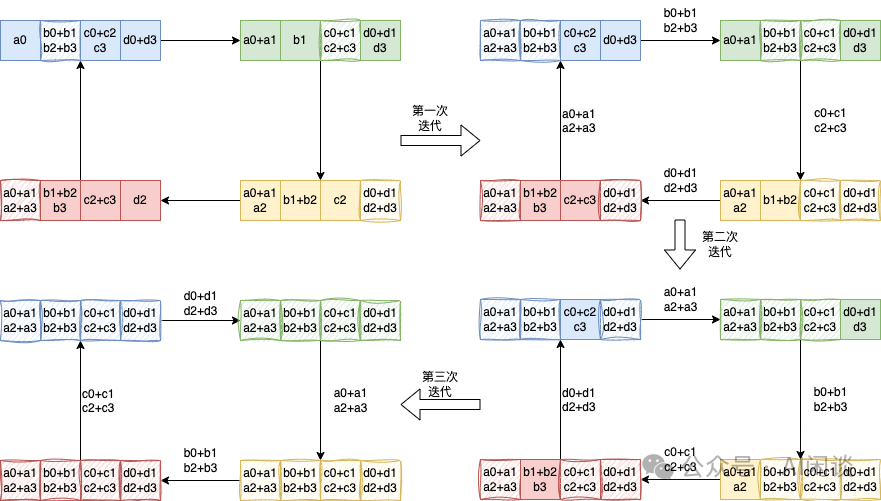
具体的 AllGather 操作如下,每个设备将其持有的部分结果发送给下一个设备,同时接收上一个设备的部分结果,逐步汇集完整的结果,同样需要 K-1 步。AllGather 后,每个设备都包含全量的数据:
2.2 LLM Tensor Parallelism AllReduce
当前 LLM 推理通常会采用 Tensor Parallelism(TP)模型并行,以便在多个 GPU 上实现较大 LLM 的推理。对于标准的 Transformer Decoder Only 模型,通常会在每个 Transformer Block 中采用如下的 TP 切分方式:
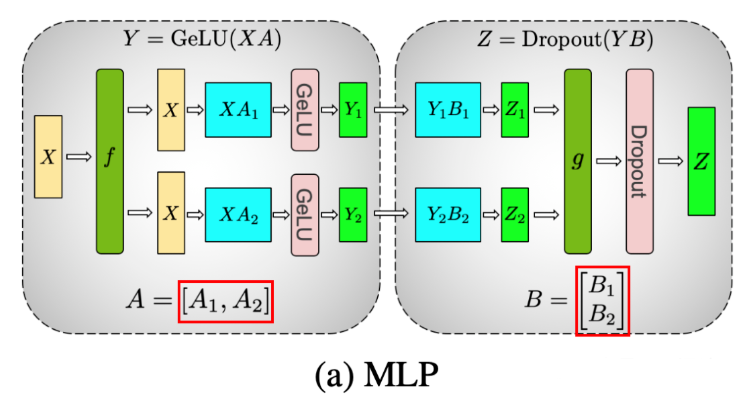
如下图 (a)所示,MLP 层的两个 Linear 层采用先列切(A,Column Parallelism),然后行切(B,Row Parallelism)的方案,这样两个 Linear 之间不用通信:
如下图(b)所示,由于每个 Head 的 Attention,Softmax 都可以独立计算,因此可以按照 Head 的方式切分(等价于列切分),然后对之后的 Linear 采用行切分(B),这样 Self-Attention 中间也不用通信:
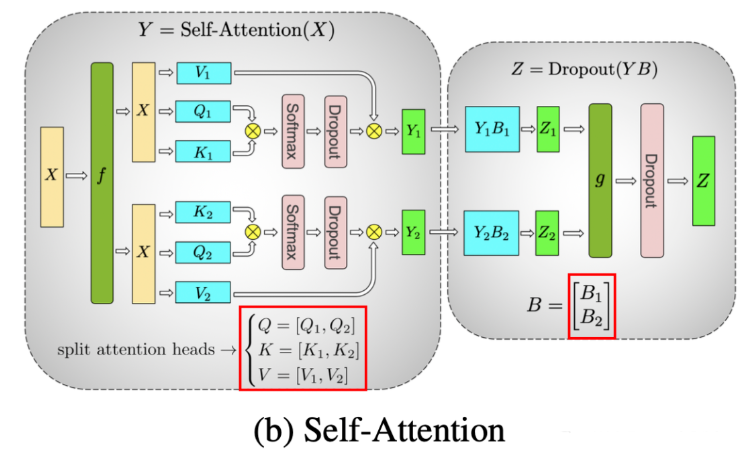
如上所述,采用先列切、再行切的方式,每个 Transformer Block 中都需要两个 AllReduce 操作,对于一个 40 层的模型则需要至少 80 个 AllReduce 操作。
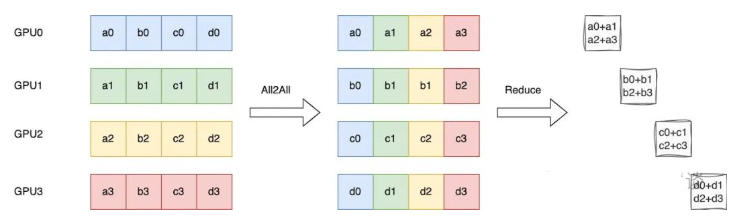
2.3 ReduceScatter = All2All + Local Reduce
如下图所示为 Ring ReduceScatter 的优化,可以等效为一个 All2All 操作实现数据的重排,然后在 Local 进行 Reduce 操作。此过程只有一个 All2All 的整体通信操作,虽然实际上与 Ring 实现的方式的通信量和计算量没有变化,但可以避免 K-1 个 Ring Step 的同步,进而可以有效降低时延。
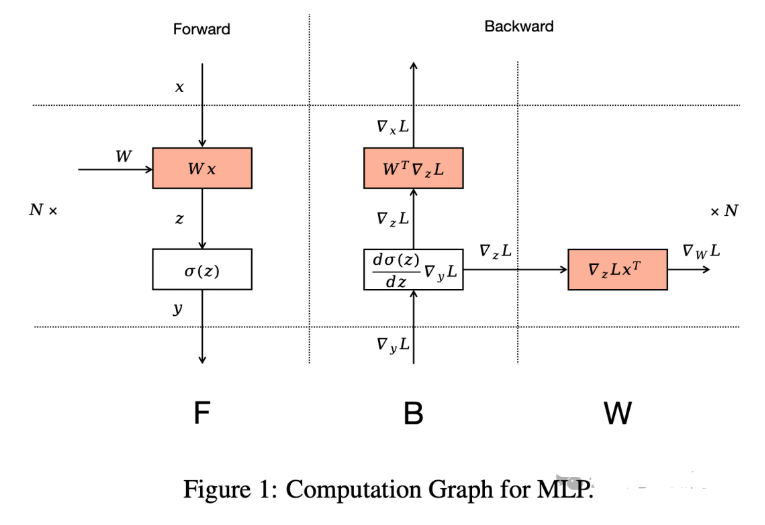
2.4 ZeroBubble
[2401.10241] Zero Bubble Pipeline Parallelism [1] 中作者提出 Zero Bubble,核心思路是将 Backward 分为两个部分,一部分计算输入的梯度,另一部分计算参数的梯度,如下图 Figure 1 所示。这里计算输入的梯度有明确的依赖关系,也是链式法则不断传递的基础;而计算权重的梯度却没有明确的依赖,甚至可以滞后很多。此外,三个红色部分计算量相当,这也就是为什么常见的流水线并行(Pipeline Parallelism,PP)中 Backward 的长度为 Forward 的 2 倍。
三、Microsoft - CoCoNet
3.1 摘要
对应的 Paper 为:[ASPLOS 22] [2105.05720] Breaking the Computation and Communication Abstraction Barrier in Distributed Machine Learning Workloads [2]
CoCoNet 可能是最早提出异步张量并行(Async Tensor Parallelism)的工作,作者提供了一种通用 Kernel 融合的范式,能够自动生成集合通信与常见计算操作(如 GEMM 和卷积)之间的融合 Kernel。具体来说,CoCoNet 包含:
- 一种领域特定语言(DSL),用于以计算和通信操作的形式表示分布式机器学习程序。
- 一组保持语义的转换规则,以优化程序。
- 一个编译器,可以生成联合优化通信和计算的 GPU Kernel。
PS:然而,生成的代码执行效率不及直接采用 cuBlas、cutlass 或 cuDNN 中的高度优化 Kernel,主要原因在于为实现这种细粒度计算-通信 Overlap 需要在 Kernel 内引入额外同步操作。
3.2 方法
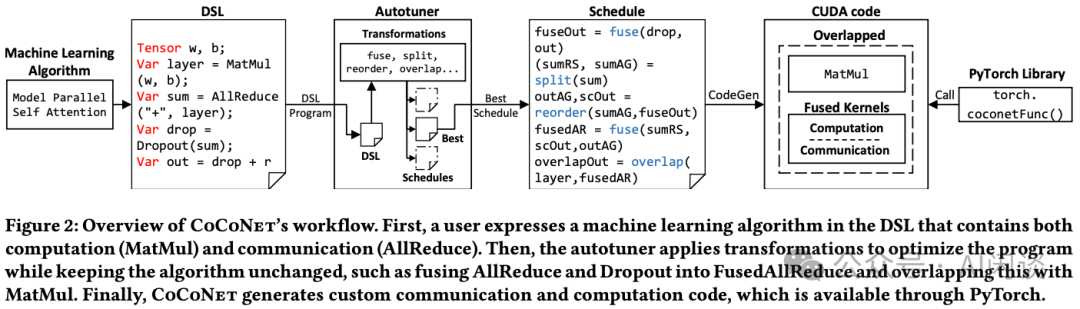
如下图 Figure 2 所示为 CoCoNet 的工作流:
-
首先,使用 DSL 表示用户的机器学习算法,该语言同时包含计算(如矩阵乘和卷积)与通信操作(如 AllReduce)。
-
然后,Autotuner 应用一系列变换以优化程序,同时确保算法逻辑保持不变。例如,将 AllReduce 与 Dropout 融合为 FusedAllReduce,并使其与矩阵乘法 Overlap。
-
最后,生成对应的通信与计算代码,并且可以通过 PyTorch 执行。
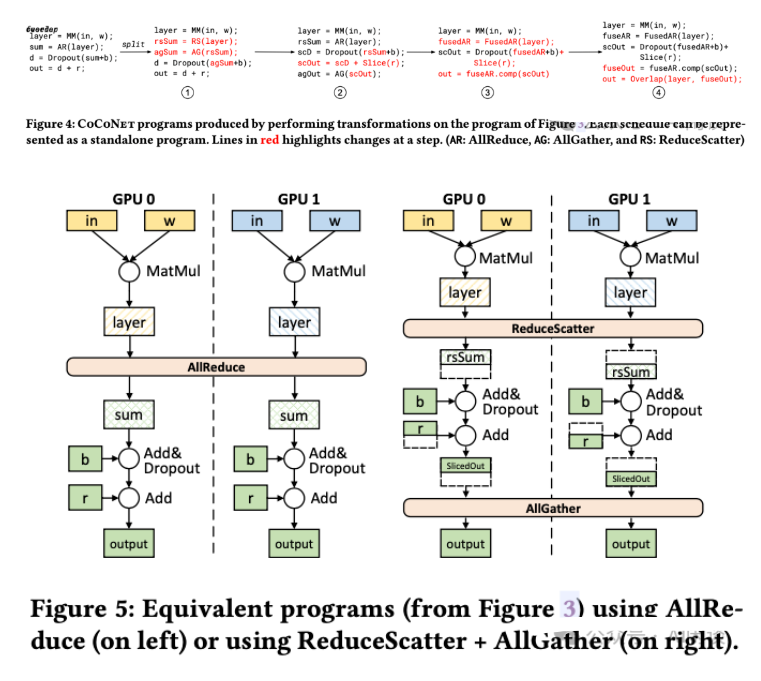
CoCoNet 提供了 4 种能够保持语义的转换方案,用于优化以 DSL 表示的程序。以下图 Figure 3 的代码为例,其主要是实现了 :矩阵乘法 + AllReduce + Dropout + Add。

具体的几个转换过程如下:
- AllReduce 拆分为 ReduceScatter(RS)和 AllGather(AG)
- 操作重排并拆分为等价算子(如下图 Figure 5):
- scD 和 scOut 均为 Slice 切片操作。
- agOut 用于收集计算的最终结果。
- 算子融合:
- FushedAllReduce(FusedAR):融合了 ReduceScatter(rsSum)、计算操作(scD 和 ScOut),以及 AllGather(agOut)。
- fusedAR.comp(scOut) 则指定了需要与 FusedAllReduce 融合的计算,返回的 out 则是输出结果。
- Overlap:对一系列生产者-消费者操作,可以执行 Overlap 变换。比如有多个数据要执行上述操作(不同样本,数据的不同 Chunk),则可以实现通信与计算的 Overlap。
CoCoNet 提供了 AutoTunner,能够自动探索程序的所有调度方案的空间,并针对特定底层框架和输入规模,返回性能最佳的调度方案。
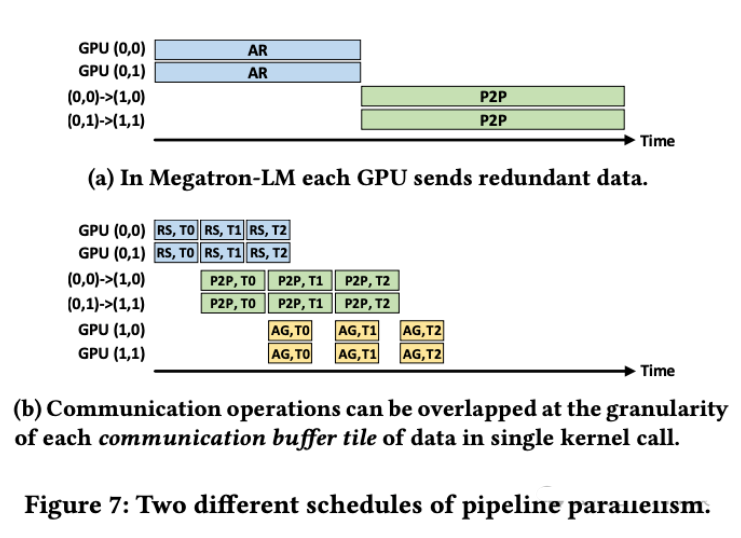
以下图 Figure 7 所示为将其应用到 Megatron-LM 中的 TP+PP 的优化案例,具体来说,总共 4 个 GPU,分成两个 PP Stage,每个 Stage 有 2 个 GPU,使用 TP 切分。比如下图 GPU(0, 1) 表示 PP Stage 0 的 1 号 GPU。
-
(a):两个 PP Stage 之间会有一个 PP Stage 0 内部的 AllReduce 操作,以及一个 PP Stage 0 与 Stage 1 之间的 P2P 操作。
-
(b):将数据拆分为多个 Chunk,并使用 ReduceScatter + AllGather 代替 AllReduce,即可实现一定的 Overlap,并减少冗余数据传输。
3.3 结果
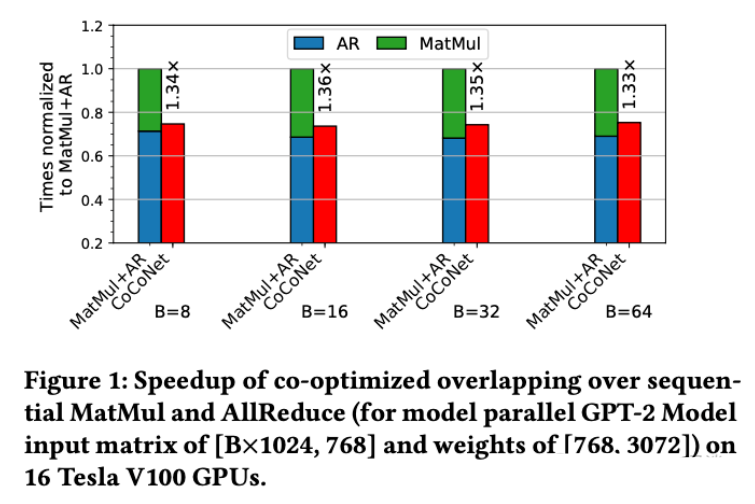
如下图 Figure 1 所示,MatMul 与 AllReduce 的细粒度 Overlap 执行可掩盖 80% 的 MatMul 执行时间,并带来 1.36x 的加速效果。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









