







关系型数据库常用语句及一些数据库知识整理
(一)数据库常用语句
创建测试环境
在线数据库 http://sqlfiddle.com/
给后台看的初级入门知识:【《跟着孙兴华学习MySQL》关系型数据库教程[初级篇完结]-哔哩哔哩】 https://b23.tv/nStbOCd
〇、 sql分类
数据库语句大全
DDL(Data Definition Language):数据定义语⾔,⽤来定义数据库对象:库、表、列等;
DML(Data Manipulation Language):数据操作语⾔,⽤来定义数据库记录(数据);
DCL(Data Control Language):数据控制语⾔,⽤来定义访问权限和安全级别;
DQL(重要)(Data Query Language):数据查询语⾔,⽤来查询记录(数据)。 注意:sql语句以;结尾
一、最基本的增删改查
链接: 数据库常用语句
增删改查
select 'A'||name||'A' ana, concat('A',name) an, lastname, firstname from persons
insert into persons values ('gates', 'bill', 'xuanwumen 10', 'beijing')
update person set firstname = 'fred' where lastname = 'wilson'
delete from person where lastname = 'wilson'
--子查询
select a.name,a.age from (select t.name,t1.age from workerid t left join workerinfo t1 on t.id=t1.id) a --表
Select * from People where PeopleAddress = (select PeopleAddress from People where PeopleName = '赵云') --值
1字段去重
如果一个表里有历史数据,如
(我 男 程序员 十万 去年)
(我 男 程序员 二十万 今年)
对于名称字段,不希望在结果中重复出现,则
select distinct name, sex from worker;
2加上分页条件
1、oracle写法
rownum使用技巧
select * from table1 where rownum <=20;
oracle的写法,特别地,rownum<=1可用来检查表中是否有数据。简单的单表查询写法时不能对rownum用>(大于等于1的值) >=(大于1的值),也不能=(大于1的值)。
因为rownum是个伪列,是作为符合查询条件的返回结果的逐增记行值,只有符合查询条件的结果才会计为一行而使返回的rownum增1,也就是说用rownum>1的条件查到的结果rownum始终无法大于1而被舍弃。如下面写法的count结果为0。
select count(*)from people where rownum >1;
当然>0时返回的是正确的行数。
如果想查第5列,可用下面写法
select object_id,object_name
from (select object_id,object_name, rownum as rn from t_test1)
where rn = 5;
查询6到10列用下面写法
select * from
(
select a.*, rownum as rn from css_bl_view a
where capture_phone_num = '(1) 925-4604800'
) b
where b.rn between 6 and 10;
配合order by使用也需注意:对于order by主键,是先排序再计算ROWNUM。但如果order by 非主键,oracle会先按物理存储位置(rowid)顺序取出满足rownum条件的记录,即物理位置上的前5条数据,然后在对这些数据按照Order By的字段进行排序。所以需要写法上做些处理,如下
select object_id,object_name
from (select object_id,object_name from t_test1
order by object_name)
where rownum <= 5;
--主键是object_id,排序用非主键object_name时
2、mysql写法 ——使用limit
MySql分页查询
# 放在查询语句的末尾
LIMIT 【位置偏移量off,】 行数n
--位置偏移量off值可不写,则取前n行。相当于每n行为1页时,取第1页。
注意off是跳过的行数,可取0,查询返回结果从第off+1行开始。
20行每页,取第3页:
SELECT
employee_id,
last_name
FROM
employees
LIMIT 40, 20 ;
分页查询公式:
(当前页数-1) * 每页条数,每页条数
取第32、33行
SELECT
*
FROM
employees
LIMIT 31, 2 ;
MySql8.x的新写法
SELECT
*
FROM
employees
LIMIT 2 OFFSET 31 ;
3字段拼接为一个字段
concat(字段1,字段2,…) as 新字段
用|| : col1||‘任意字符串’||col2 …
4字段左填充
lpad(字段a,8,‘*’)填充数个星号使字符串长度为8
5截取
substr(字段a,3,3)从第三个字符开始截取3个
substr(字段a,3)从第三个截到最后
二、加上条件和运算,分组或窗口的查询
在实际应用中,我们往往会加上排序、分组、指针查询、计算等语句或函数来达到查询所需数据的目的。
SQL Server:八、条件查询:where、比较运算符、子查询、条件语句
select * from People where PeopleAddress in('武汉','北京')
select * from People where PeopleSalary >= 10000 and PeopleSalary <= 20000
select * from People where PeopleSalary between 10000 and 20000
select * from People where PeopleSalary <> 10000 --不等于
select top 5 * from People order by PeopleSalary desc --前5行
select top 10 percent * from People order by PeopleSalary desc --前百分之10
select * from People where PeopleAddress is not null
//获取时间的月 select to_char(sysdate,'dd') as nowDay from dual
查询消费者总消费额
select customer,sum(cost) from costrecord
where year>2021 and type='厨卫'
group by customer
order by viplevel
查询消费者总消费次数
select customer,count(cost) from costrecord
group by customer order by viplevel
group by(分组)、order by(排序)、where(条件)
说明下分组group by、排序order by和条件where的关系
写法:group by必须位于where 后,order by前。
即from > where > group by > having > order
- group一般与order by一起使用,先执行group by 后执行order by。
- 使用group by 后,若想进行再次筛选可以使用having,即having是在分组后进行筛选。
- 与where同时用 :先执行筛选条件后分组。
- having对一组数据进行操作;where是对行进行操作。
窗口函数 PARTITION BY()函数简介
partition by 和 group by
partition by可在保留全部数据基础上,只对其某些字段做分组排序,不会聚合同类数据,用于筛选计算范围;
group by则只保留参与分组的字段和聚合函数的结果
# 查询每种商品的id,name,同类型商品数量(ps:感觉这个应用的有点问题)
select id,name,count(*) over (partition by type) from product;
# 查询每个城市每个类型价格最高的商品名称
select
name,
price, --这里的列应该是address?
type,
max(price) over (partition by address,type) as 'max_price'
from product;
窗口函数 详细 over (partition by _ order by _ )
1、关键字含义:
partition by:根据某个字段来分组,类似于group by,但是不会聚合同类数据,用于筛选计算范围
order by:分组后根据某个字段进行排序
ROWS:物理行维度,筛选计算范围。
RANGE:根据列的值,来筛选行的范围
CURRENT ROW :当前行
UNBOUNDED PRECEDING :当前行上侧所有行
UNBOUNDED FOLLOWING :当前行下侧所有行
__ PRECEDING:当前行上侧__行(__可以是数字,也可以是表达式)
__ FOLLOWING:当前行下侧__行(__可以是数字,也可以是表达式)
2、利用窗口函数排序并搭配聚合函数
(分组排序后,按窗口进行计算 sum + rows/range)
ps:下面写法是可以的,含义解释感觉有点问题,没亲自试。
-- 根据用户id分组,分数排序,当前行的sum()
sum(sroce) over(partition by user_id order by sroce rows current row) as sum1
-- 根据用户id分组,分数排序,从 组内首行? 到当前行的sum()
如果解释没错,那在统计每个人截止不同时间的总收入时可用
sum(sroce) over(partition by user_id order by sroce rows between 1 preceding and current row) as sum4
-- 根据用户id分组,分数排序,当前行且 相邻上下? 分数相等的sum()
sum(sroce) over(partition by user_id order by sroce range current row) as sum2
--根据用户id分组,分数排序,当前行且 相邻上下? 当前分数-1 和 当前分数+1之间
sum(sroce) over(partition by user_id order by sroce range between 1 preceding and 1 following) as sum3
3、利用窗口函数排序并得到组内的序号
组内序号
–如果组内有两个并列最高分
--顺序排序,顺序为1,2,3
ROW_NUMBER() over (partition by user_id order by score) as rn1
--并列排序,跳过重复序号,顺序为1,1,3
RANK() over (partition by user_id order by score) as rn2
--并列排序,不跳过重复序号,顺序为1,1,2
DENSE_RANK() over (partition by user_id order by score) as rn3
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by,但不晚于 order by 的执行。
窗口函数其他参考1
窗口函数其他参考2
三、多表查询
拼列 left join
select
a.schoolid,b.schoolname,b.schoolorder,
a.teacherid,c.teachername,d.teachersalary
from
schoolteacher a
left join school b on a.schoolid=b.schoolid
left join teacher c on a.teacherid=c.teacherid
left join teacherinfo d on a.teacherid=d.teacherid
拼列 where(+) --oracle
oracle中的左右连接
--(+)在哪一边,则返回另一边所有的记录。(+)在右面是左连接
select
a.schoolid,b.schoolname,b.schoolorder,
a.teacherid,c.teachername,d.teachersalary
from
schoolteacher a
school b
teacher c
teacherinfo d
where
a.schoolid=b.schoolid(+) and
a.teacherid=c.teacherid(+) and
a.teacherid=d.teacherid(+)
拼行 union / union all
见union和union all的区别
四、通过PID字段关联的树型数据的查询
查询当前节点与所有子节点:
SELECT * FROM YW_XYZB
CONNECT BY PRIOR ID = PARENT_ID
START WITH ID = '***';
查询当前节点与所有父节点:
SELECT * FROM YW_XYZB
CONNECT BY PRIOR PARENT_ID = ID
START WITH ID = '***'
五、按条件来转换返回值(case when)
case when then else end
select name ,
(case when age>65 then 2 when age<35 then 0 else 1 end) as type
from workerinfo;
推荐阅读:SQL- case when then else end 用法经验总结
SELECT a.*,
CASE
WHEN a.age BETWEEN 0 and 20 THEN '青年'
WHEN a.age BETWEEN 20 and 40 THEN '中年'
ELSE '非人类'
END AS '描述'
FROM c_20170920 a
select country,
sum( case when sex = '1' then
population else 0 end), --男性人口
sum( case when sex = '2' then
population else 0 end) --女性人口
from table_a
group by country;
Oracle 特有decode case when 和 decode 的比较分析
#其他查询条件
1、模糊查询like,查找表中num字段前面任意多个字符,中间字符a,后面1个字符(几个_就是代表有几个字符)
select num from table1 where num like '%a_';
2、指定范围查询in,在给定的取值里查找
select * from table1 where id in ('11','13','a1');
3、空值is null
4、中间取值 between 1and 5,是否包含边界要看是什么数据库
5、<> 不等于 and or not 与或非(建议写法)
6、中文星期几排序可借助 order by instr(‘周五、周四、周三’,day)这种写法,instr返回param2在param1的什么位置,从1起计,找不到返回0。
#建表改表建视图加注释
create or replace
comment on
#建模式和改权限
??
grant
#导入导出库
imp/impdp 和exp/expdp
#数据库里常用系统表
user_tables user_tab_columns user_tab_cols
user_tab_comments user_col_comments
取当前用户拥有的表名及表注释
select a.table_name as name,b.comments as remark
from (select table_name from user_tables ) a
inner join (select table_name,comments from user_tab_comments) b
on a.table_name=b.table_name
order by a.table_name
#一些函数
SYSTIMESTAMP SYSDATE TRUNC ROUND dbms_random(oracle) to_char to_date
#临时表
with queryname1 as(sql查询语句) select * from queryname1;
#触发器 过程/包
略
#MySql安装与重置与重设密码
MySql安装5.x
MySql安装8.x
mysql 重置数据库
mysql 重置数据库2
Mysql忘记密码和密码重置
(二)数据库基础知识
一、数据库设计原则(范式)
数据库六种范式详解
关于范式是否要遵守:
https://www.bilibili.com/video/BV1J94y1y75k/?spm_id_from=333.337.search-card.all.click&vd_source=6debe81be6c46d072d7be3a28fc4790e
各个范式依次递进,符合后面的则必然符合前面的。
该语境下的“依赖”指存在离散函数y=f(x1,x2)。
- 1NF是属性的原子性约束,属性不可分
- 2NF是记录的唯一性约束,实现上是表里必须有主键(一个或多个属性构成),非主属性必须依赖候选码
- 3NF是每个非主属性不依赖于其它非主属性,非主属性不能是其他非主属性派生出的信息,必须直接与主属性相关(去除非主属性信息的冗余)
- BCNF是非主属性不能对候选码有部分函数依赖关系,即不能在某候选码中只取部分属性即可决定非主属性值(去除该表中主属性信息的冗余)。“部分函数依赖”说的是"某属性值可以依赖于属性组的一部分属性而非整体"。
关于BCNF对3NF的改进:
遵循BCNF的结果是表中的候选码是唯一确定的且作为表的主键,从候选码中不能再拆分出子集候选码供非候选码依赖。否则在这个多属性构成的主键中,肯定有属性间存在一一对应关系,或是该主属性值在该表描述的业务中无甚意义,这个一一关系或多余的主属性在这个表描述的业务数据中一定是冗余的信息,应当只保留其中一个属性。还可能因为数据量不足连带导致这个一一对应关系的数据无法在该表数据中全量体现,不管怎么看都应该单独成一张关系表,而业务表的主键应该是个尽可能小的属性集合。
就刚刚讨论的“主键中属性一一对应”的情况延伸开来,可以想到一多对应又是怎样,我认为这个“多”应该不会是主键里的属性而是非主属性。 - 4NF去除多对多。我想了一种情况,“购物取向”K中的各种取向如果与“职业”A、“兴趣”B、“年龄”C等存在非平凡的多值依赖,且是多对多关系,则不应该出现在一个表中。
- 5NF实在没看懂。
推荐的命名规范:

二、 我对关系型数据表设计使用的经验及理解
按我的经验(非普遍性划分),设计表时有码表,关系表,记录表等。
码表:狭义的码表一般存放能提取码值的信息(表由编码、名称、序号构成),基本情况表存放基本固定不变的相关信息,比如编码为001的仓库位于编码0101的北京市区,容量1023平等等。广义的码表,可以把狭义的码表和基本情况表结合起来,把位置、容量这些基本固定的物理描述通通作为码表的扩展列而减少表的数量。
关系表:存放可变的关联关系。描述码表属性间的关联关系(把多个码表主属性关联起来成表,突出一个关联关系,而不是把他们作为另一个表的主属性/候选码来作为数据的标识)。基本的属性不变化时,对应关系可能发生变化,但一般这个关系的条目量不会太多变化。关联关系一般体现业务特征,比如仓库管理人关系表体现了仓库由人管理这一业务特征,又比如博客标签关系表体现了领域划分这一业务特征。
记录表:把多属性或单属性作为主键(一个表唯一可取的候选码),记录相关的当前状态或变化状态,随着时间发展,非主键数据会变化(状态表),或是增加新行记录新数据(状态变化表)。
再具体点分析:
码表:
比如仓库编码表。仓库全称一般不会重复也不会变,但还是可能变;而且名称较长重复存储仓库名称占用空间较多。故而设计编码表,而在其他表中用编码指代仓库。经纬度、容量(100平101平这种直接存数值,大仓库小仓库这种存放仓库容量等级的码值)可认为是仓库固定的关联信息/物理属性,可以放在仓库编码表里以免表太多。
比如管理人编码表。我们最关心的是管理人名称,但它可能重复,进一步明确数据需要的是身份证信息。可以直接将身份证作为编码,则管理人名称依赖于身份证。这样的话,即使一个管理员终身负责一个仓库,把该身份证和姓名的对应关系放在仓库表里来体现也是不合适的,仓库表里可以存身份证这一编码,身份证姓名关系则用管理员编码表来存。如果只关心管理人名称不关心身份证,但是管理人不是终身责任制,那这种可变的对应关系也应该算作关系表而不能认作为仓库码表里固定的关联信息。如果只关心管理人名称,且终身固定,那么可认为管理人名称是仓库的固有属性直接放在码表中)。
此外还有物资编码表、性别编码表(97种性别–流汗黄豆)等,编码存在有意义的情况(如身份证)和无意义(如随机码)的情况。
关系表:
多个码表主键间的对应关系,体现了一定的业务逻辑,而不是时间空间变化,业务逻辑不变,码表不变,则该表数据量级不会太大变化,而具体的关联关系可能随着时间发展,由于委派、任命而发生变化。仓库与管理员这种虽然可能是一对一的,但考虑业务改革、管理员变更,最好还是通过仓库管理员关系表来存储对应关系,而不是把管理员放在仓库编码中作为关联属性。
记录表:
体现时间空间性质。比如某仓某物资当前数量、当前占用空间,某仓库当前工人数量、打卡情况,或是物资今日入库出库数量等。用来经常性地insert或update变化的数值。这些数值往往对应于多个主属性构成的候选码。
三、理解数据库的运行
https://www.bilibili.com/video/BV12t4y1H7by/?spm_id_from=333.788&vd_source=6debe81be6c46d072d7be3a28fc4790e
查询时发生了什么:
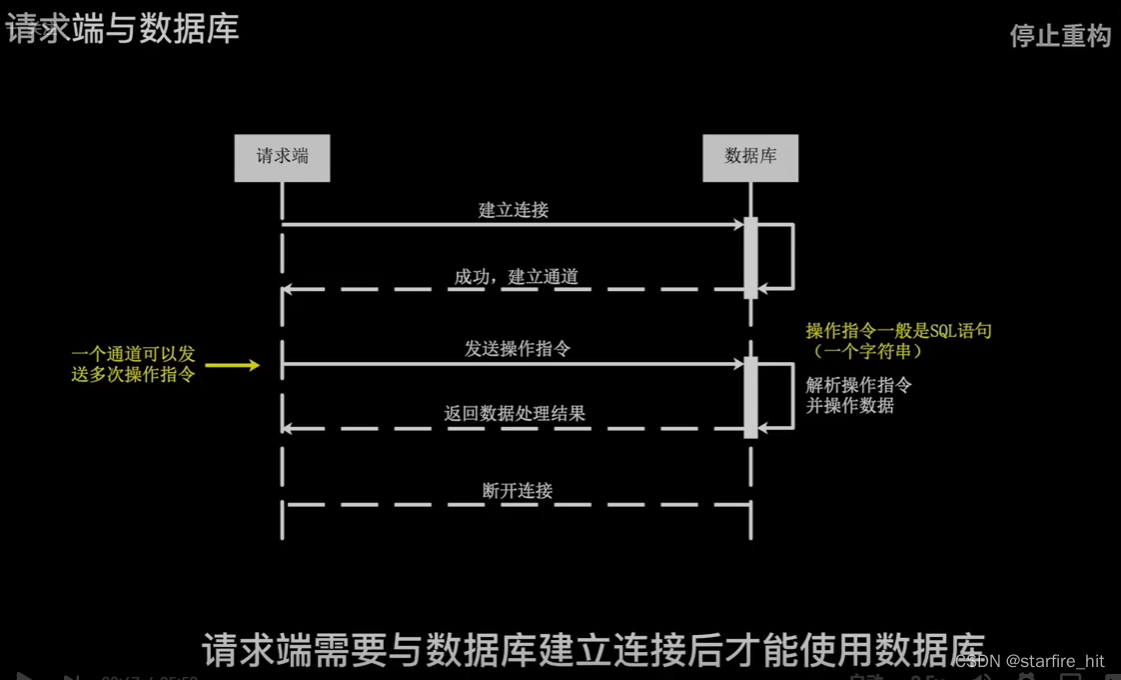
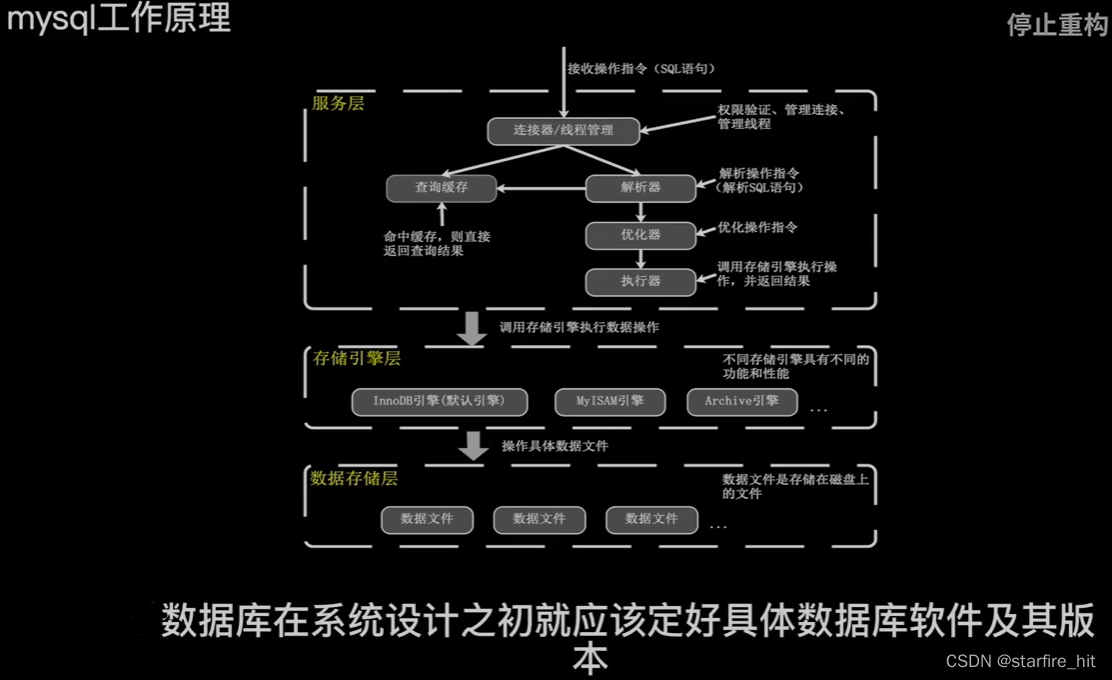
性能调优,根据服务器性能,通过测试确定较优参数:
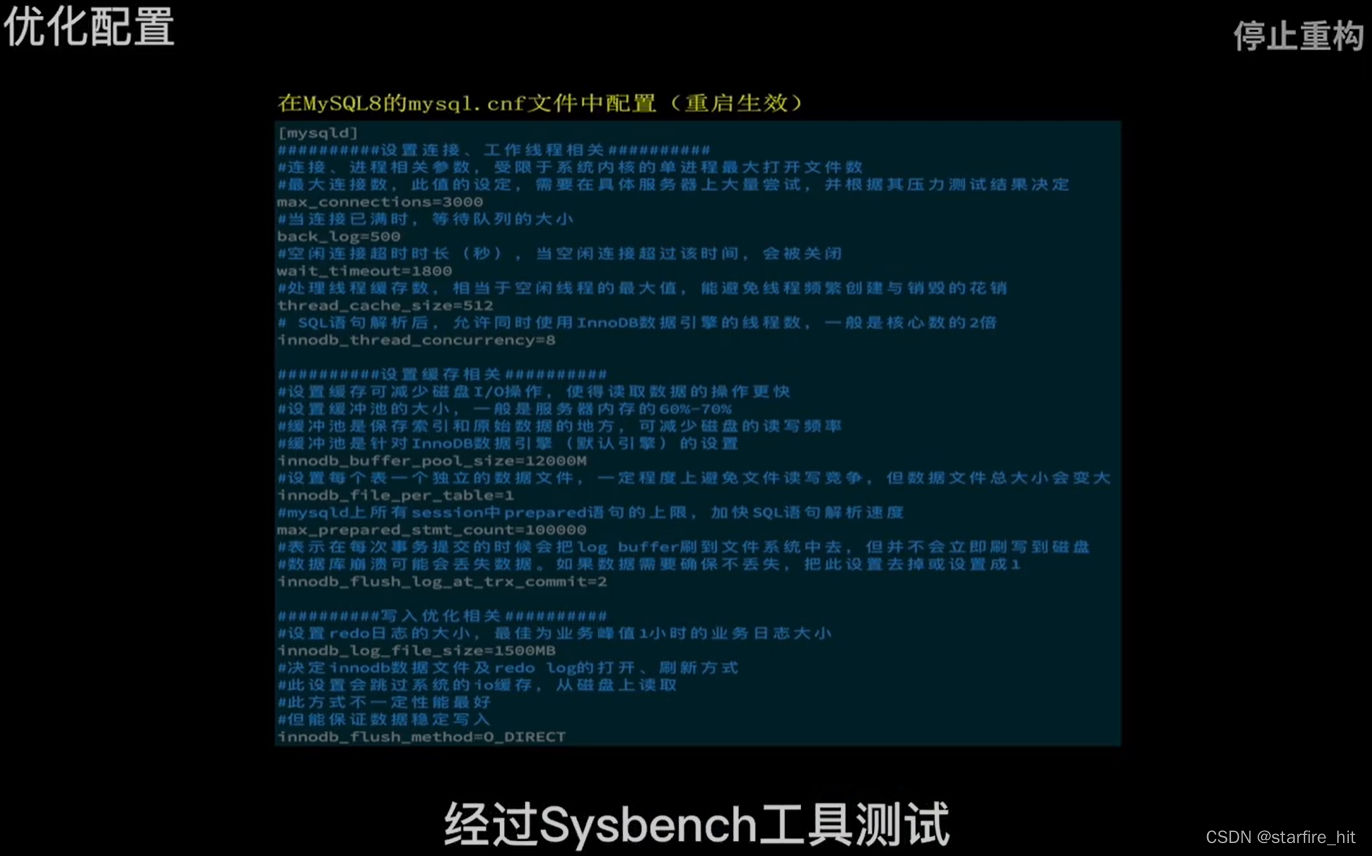
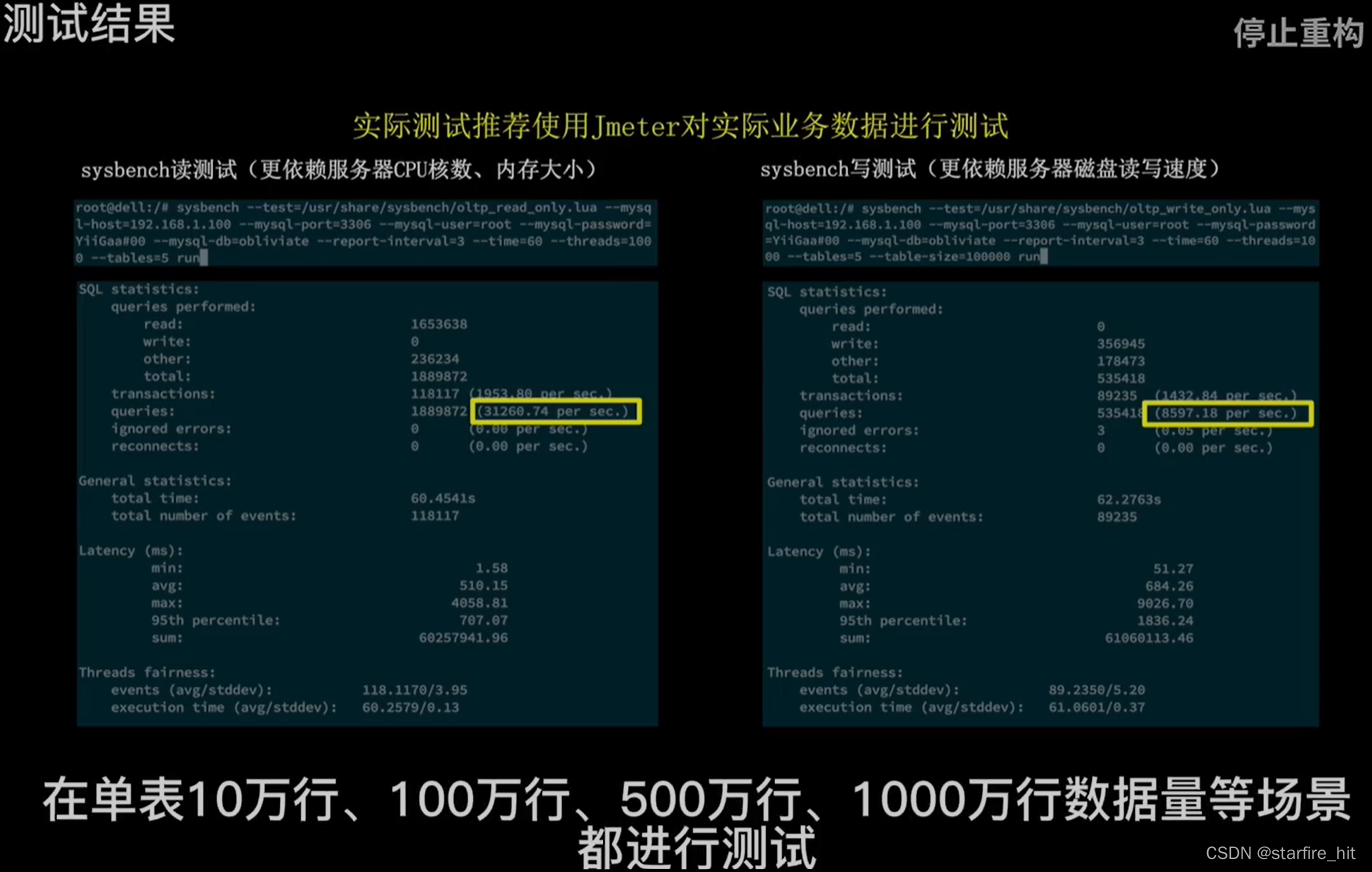
通过多场景测试,预测业务增长到什么情况下需要增加数据库服务器数量,以做读写分离、分片存储来降低单台服务器压力。MySQL单表超过1kW行以后会性能骤降。
四、文档和关系型数据库的区别
https://www.bilibili.com/video/BV1aL411G7Z9/?spm_id_from=333.999.0.0&vd_source=6debe81be6c46d072d7be3a28fc4790e
数据库的几种类型

#其他:
索引?














 25万+
25万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









