






1. 要求
通过对各种机器学习算法的函数调用,实现疑似冠心病患者(高、中、低)危险等级自主分类。输出训练集、测试集精度, loss, DICE, Jarccard值,ROC曲线和PR 曲线(Precision, Recall)。
2. 原理
实验数据分为高危,中危和低危,将这三者作为类标,转换为Integer-Encoder和One-Hot编码用于提交给多分类器。
机器学习中可以选择以下分类器进行实验
- Logistic Regression,
- Support Vector Machine,
- Gaussian Naïve Bayes,
- k-NearestNeighbor,
- Random Forest,
- xgBoost
模型的评价指标有如下几种:
- Accuracy(Train):评价模型对训练集的准确性
- Accuracy(Test):评价模型对测试集的准确性
- Loss:估量模型的预测值predict与真实值y_test的不一致程度
- Jaccard :是预测值和真实值的交集数量除以预测标签和真实标签的并集数量
- Dice :相当于F1值,均衡衡量Precision 和 Recall的指标
- ROC & PR:能均衡客观的反映出模型整体好坏的指标
- Confusion Matrix:ROC PR作图的准备步骤,能总体看分类效果
特异度(specificity)与灵敏度(sensitivity)
考虑一个二分类的情况,类别为1和0,我们将1和0分别作为正类(positive)和负类(negative),则实际分类的结果有4种,表格如下:

从这个表格中可以引出一些其它的评价指标:
ACC:classification accuracy,描述分类器的分类准确率
计算公式为:ACC=(TP+TN)/(TP+FP+FN+TN)
BER:balanced error rate
计算公式为:BER=1/2*(FPR+FN/(FN+TP))
TPR:true positive rate,描述识别出的所有正例占所有正例的比例
计算公式为:TPR=TP/ (TP+ FN)
FPR:false positive rate,描述将负例识别为正例的情况占所有负例的比例
计算公式为:FPR= FP / (FP + TN)
TNR:true negative rate,描述识别出的负例占所有负例的比例
计算公式为:TNR= TN / (FP + TN)
PPV:Positive predictive value
计算公式为:PPV=TP / (TP + FP)
NPV:Negative predictive value
计算公式:NPV=TN / (FN + TN)
其中TPR即为敏感度(sensitivity),TNR即为特异度(specificity)。
3. 实验过程
为了更直观的看出不同特征之间的关系,我将数据进行可视化处理,将每两组特征作为一个组合进行绘制,其结果如下所示

1.首先采用k近邻算法来进行实验,先将实验样本进行处理,包括类标和特征,由于实验样本较少,所以我加入了噪音提升数据的维度,然后采用train_test_split函数对训练集数据集进行选取,测试集占比0.3。
接下来建立模型并且进行训练

图1 训练数据
训练后计算相关指标,结果如下:
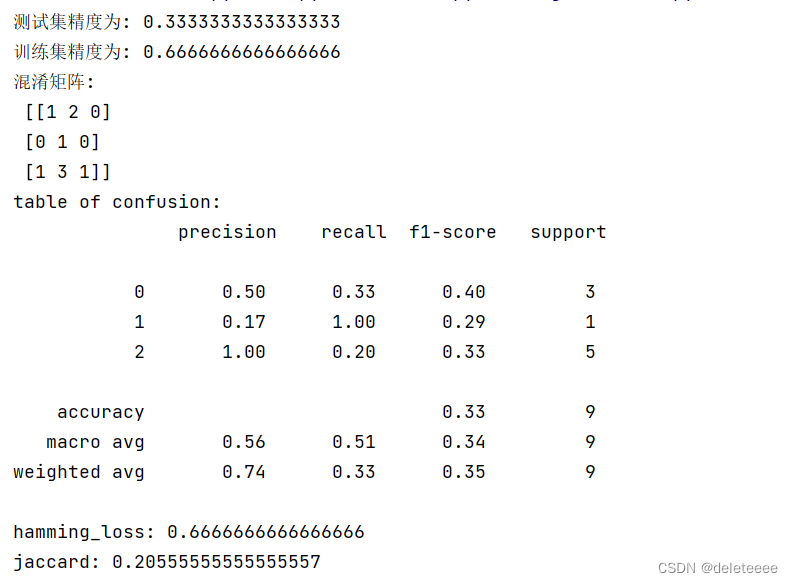
图2 最近邻算法分类结果1
由于程序中,训练集测试集的选取是随机的,所以每次结果可能会有不同,多次次运行程序结果如下:

图3 最近邻算法分类结果2

图4 最近邻算法分类结果3
2.接下来再尝试使用Logistic Regression, Support Vector Machine这两种分类方式进行分类,由于考虑到类标存在三类,为了更好的使用sklearn封装好的precision_recall_curve()函数,所以我将类标进行二值化处理,在本次实验中,高危中危低危三个类标对应0,1,2,二值化后使其类标分别为[1 0 0],[0 1 0],[0 0 1]。同样对数据加入噪音升维。然后分别建立svm和lr模型,对数据分别进行训练,然后使用下图所示方式得到预测的置信度:

图5 分别获取svm,lr模型的预测置信度
置信度结果如下:

图6 置信度
然后再分别查看两类模型的分类结果:

图7 SVM模型分类结果

图8 lr模型分类结果
接下来,获取Precision, Recall, TPR, FPR的值为绘图作准备,结果如下:

图9 SVM模型Precision, Recall, TPR, FPR的值

图10 lr模型Precision, Recall, TPR, FPR的值
接下来开始进行绘制模型的ROC和PR 曲线:
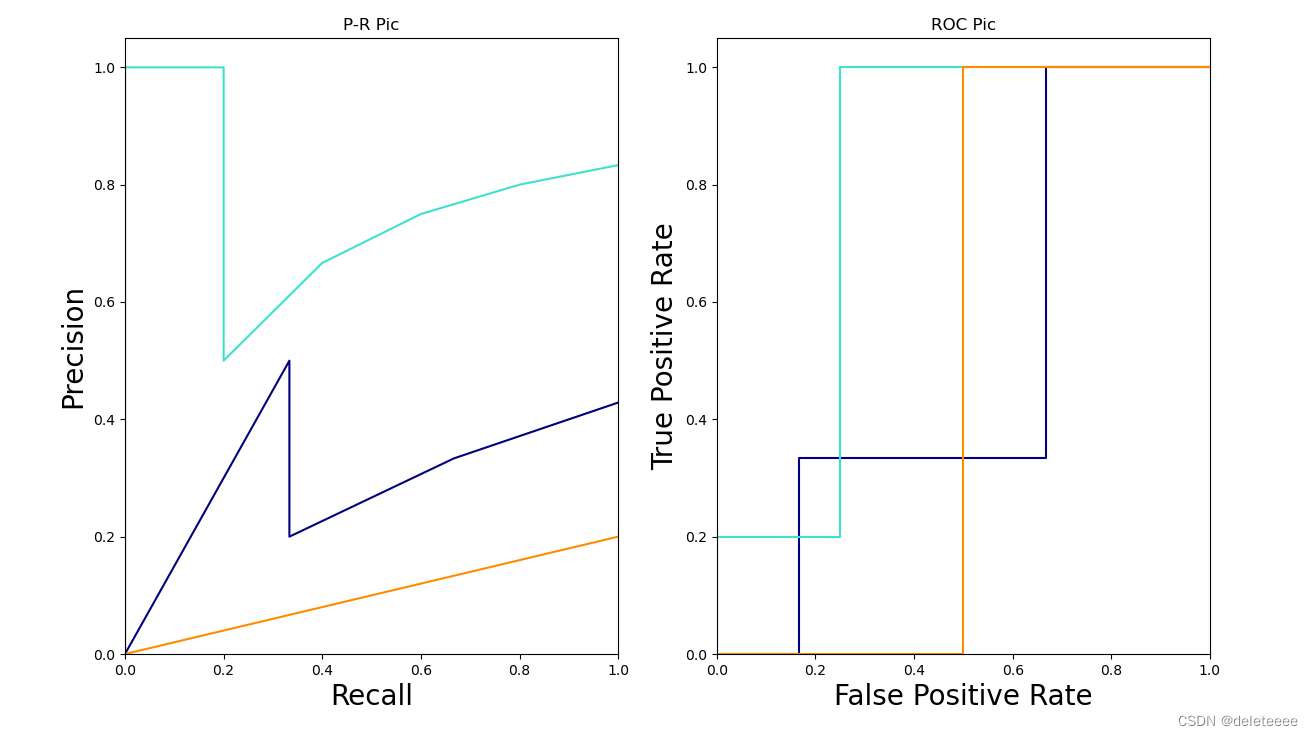
图11 SVM模型曲线

图12 lr模型曲线
发现上述两幅图中PR曲线存在从零开始上升的异常曲线,与PR曲线定义不符合,于是我选择图11中两条异常线单独绘制出来,结果如下

图 13 图11PR曲线中两条异常曲线实际趋势
同样的方式,得出图12中PR曲线中两条异常曲线的实际趋势:

图14 图12中PR曲线中两条异常曲线实际趋势
结果正常。
4. 代码
以下代码中使用的是KNN分类器,可以在相应地方修改成所需分类器即可。
from itertools import cycle
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier # 利用邻近点方式训练数据
from sklearn.preprocessing import label_binarize
from sklearn.metrics import multilabel_confusion_matrix, precision_recall_curve, roc_auc_score
from sklearn import svm
from sklearn.multiclass import OneVsRestClassifier
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
###引入数据###
szx = [[148.004, 71, 1026.561, 1585.218, 2920.418, 3946.309, 138.818, 180.025, 1061.236, 740.416],
[244.948, 68.042, 1081.502, 1676.727, 2995.63, 4140.143, 145.002, 145.345, 809.15, 378.717],
[141.483, 75.728, 1028.488, 1642.513, 2766.681, 3422.091, 64.557, 102.774, 104.309, 209.315],
[227.421, 68.424, 1203.214, 1812.705, 3100.961, 4221.391, 443.53, 543.979, 444.915, 258.943],
[294.345, 60.48, 1187.432, 1929.65, 3365.506, 4397.294, 522.396, 803.599, 346.235, 199.495],
[269.622, 74.127, 842.258, 1729.385, 3126.506, 4071.157, 989.957, 459.421, 419.165, 389.649],
[130.676, 74.238, 856.278, 1316.467, 2844.9, 3530.199, 99.514, 89.302, 1426.556, 695.504],
[187.118, 61.08, 1049.2, 1765.326, 2859.306, 3961.547, 927.502, 359.82, 703.217, 717.785],
[182.988, 75.649, 1069.614, 1617.42, 2809.565, 3918.169, 118.644, 146.152, 371.631, 217.34],
[130.715, 65.407, 925.864, 1727.784, 2825.293, 4070.821, 191.351, 133.566, 126.485, 564.661],
[199.676, 64.189, 900.887, 1630.035, 2998.414, 3856.071, 183.93, 114.576, 508.882, 341.951],
[163.745, 65.157, 964.366, 1712.517, 2909.095, 3818.905, 135.436, 92.855, 552.14, 311.054],
[118.487, 67.401, 886.081, 1563.89, 2751.811, 3772.353, 73.283, 163.583, 960.798, 808.768],
[85.074, 63.26, 865.384, 1564.582, 2711.182, 3751.69, 633.723, 269.258, 774.814, 384.615],
[94.199, 67.827, 891.044, 1507.299, 2862.042, 3938.947, 84.661, 73.962, 171.438, 258.902],
[172.465, 57.945, 776.825, 1490.396, 2594.769, 3807.435, 207.685, 837.431, 224.311, 339.811],
[211.345, 85.66, 891.983, 1554.009, 2916.625, 3600.323, 221.92, 223.967, 484.418, 223.762],
[115.358, 59.441, 860.507, 1540.669, 2595.677, 3765.012, 137.979, 144.474, 164.925, 377.609],
[358.595, 46.197, 897.688, 1737.664, 3025.684, 4095.229, 458.881, 256.046, 484.461, 602.989],
[103.624, 61.269, 919.724, 1959.431, 2906.281, 3806.523, 538.353, 524.873, 1443.122, 65.82],
[125.633, 68.533, 776.588, 1546.08, 2716.154, 3905.38, 93.749, 111.53, 115.963, 241.417],
[131.685, 74.433, 734.216, 1508.945, 2616.841, 3879.876, 239.279, 525.594, 448.677, 329.212],
[205.55, 89.758, 1081.633, 1314.782, 2746.089, 3684.57, 175.676, 409.474, 665.798, 235.384],
[110.312, 70.962, 906.736, 1460.214, 2851.034, 3666.629, 145.606, 102.462, 1196.455, 55.487],
[175.761, 63.291, 1197.537, 2011.542, 3092.852, 4223.817, 268.937, 211.753, 196.99, 875.226],
[156.145, 76.663, 914.772, 1640.993, 3126.567, 3871.301, 112.114, 100.625, 299.36, 3359.796],
[110.287, 71.563, 827.735, 1600.577, 2827.654, 3992.727, 198.724, 121.724, 391.195, 674.699],
]
szx = np.array(szx)
szy = [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2]
szy = np.array(szy)
szy1 = label_binarize(szy, classes=[0, 1, 2])
print(szy1)
n_classes = szy1.shape[1]
random_state = np.random.RandomState(0) # 加入噪音
n_samples, n_features = szx.shape
szx_rand = np.c_[szx, random_state.randn(n_samples, 50 * n_features)]
X_trainS, X_testS, y_trainS, y_testS = train_test_split(szx_rand, szy1,test_size=0.3,random_state=random_state) # 利用train_test_split进行将训练集和测试集进行分开,test_size占30%
# 使用未二值化的标签,使得分割后的训练集正常
X_trainL, X_testL, y_trainL, y_testL = train_test_split(szx_rand, szy, test_size=0.5,random_state=random_state)
# 将测试集的标签二值化
y_testL = label_binarize(y_testL, classes=[0, 1, 2])
X_train, X_test, y_train, y_test = train_test_split(szx_rand, szy, test_size=0.3)
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)
prdtest=knn.predict(X_test)
prdtrain=knn.predict(X_train)
print('测试集精度为:',metrics.accuracy_score(y_test,prdtest))
print('训练集精度为:',metrics.accuracy_score(y_train,prdtrain))
print('混淆矩阵:\n',metrics.confusion_matrix(y_test, prdtest, labels=[0,1,2], sample_weight=None))
print('table of confusion:\n',metrics.classification_report(y_test, prdtest,labels=[0,1,2]))
print('hamming_loss:',metrics.hamming_loss(y_test,prdtest))
#fpr, tpr, thresholds = roc_curve(y_test,yscore,pos_label=2)
#print(fpr,tpr)
#print(y_test,prdtest)
print('jaccard:',metrics.jaccard_score(y_test,prdtest,average='macro'))#jaccard_similarity_score(y_test, prdtest, normalize=False))
clf1 = OneVsRestClassifier(svm.LinearSVC(random_state=random_state,max_iter=10000))
# 训练
clf1.fit(X_trainS, y_trainS)
prd1=clf1.predict(X_testS)
# 建立逻辑回归模型
clf2 = OneVsRestClassifier(LogisticRegression(random_state=random_state,max_iter=100000))
# 训练
clf2.fit(X_trainL, y_trainL)
prd2=clf2.predict(X_testL)
# 得到预测的置信度
y_scoreS = clf1.decision_function(X_testS)#svm
y_scoreL = clf2.decision_function(X_testL)#lr
print(sum(sum(y_scoreS))/len(y_scoreS)/3)
print(sum(sum(y_scoreL))/len(y_scoreL)/3)
print('svm 预测置信度:',y_scoreS,'\nlr 预测置信度:',y_scoreL)
def num_get(y_score, y_test, classes):
# 建立存储字典
Precision = dict()
Recall = dict()
TPR = dict()
FPR = dict()
# 由于我们是多标签模型,所以循环输出每种标签的值
for i in range(classes):
# 截取预测结果的第i列,_代表无关变量
Precision[i], Recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:, i])
FPR[i], TPR[i], _ = roc_curve(y_test[:, i], y_score[:, i])
print('auc:',roc_auc_score(y_test[:,i], y_score[:,i]))
plt.plot(Recall[0],Precision[0],Recall[2],Precision[2])
return Precision, Recall, TPR, FPR
def draw_line(Precision, Recall, TPR, FPR, classes, title):
colors = cycle(['navy', 'turquoise', 'darkorange'])
plt.figure(figsize=(14, 8))
plt.suptitle(title + ' ', fontsize=30)
ax1 = plt.subplot(1, 2, 1)
plt.xlabel("Recall",fontsize=20)
plt.ylabel("Precision",fontsize=20)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
for i, color in zip(range(classes), colors):
plt.plot(Recall[i][::-1], Precision[i][::-1], color=color)
ax2 = plt.subplot(1, 2, 2)
plt.xlabel("False Positive Rate",fontsize=20)
plt.ylabel("True Positive Rate",fontsize=20)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
for i, color in zip(range(classes), colors):
print(color)
l, = plt.plot(FPR[i], TPR[i], color=color)
ax1.set_title("P-R Pic")
ax2.set_title("ROC Pic")
plt.savefig(title + 'PR-ROC.png')
plt.show()
return 0
def draw_data(X_train,names,title):
fig = plt.figure('Iris Data', figsize=(50,50))
plt.suptitle('中医声诊', fontsize = 30)
for i in range(10):
for j in range(10):
plt.subplot(10,10,10*i+(j+1))#将画板分割为4x4的布局,并且轮流绘制
#当行列数相同(特征相同)时只显示特征的名称
if i==j:
plt.text(0.3,0.5,names[i],fontsize = 25)
else:
#两两组合绘制带有特征的散点图
plt.scatter(np.array(szx)[:,j], np.array(X_train)[:,i], c=np.array(X_train)[:,3], cmap = 'brg')
if i==0:
plt.title(names[j], fontsize=20)
if j == 0:
plt.ylabel(names[i],fontsize=20)
#调整布局
# plt.tight_layout(rect=[0,0,1,0.9])
plt.savefig(title+'data-view.png')
plt.show()
return 0
#draw_data(szx,['FO','I','F1','F2','F3','F4','B1','B2','B3','B4'],'12')
#Precision, Recall, TPR, FPR = num_get(y_scoreS, y_testS, 3)
#draw_line(Precision, Recall, TPR, FPR, 3, 'SVM')
Precision, Recall, TPR, FPR = num_get(y_scoreL, y_testL, 3)
draw_line(Precision, Recall, TPR, FPR, 3, 'Log')
print('Precision:',Precision,'\nRecall:' ,Recall,'\nTPR:', TPR,'\nFPR:', FPR)
#print(y_testL,prd2)
prd2=label_binarize(prd2, classes=[0, 1, 2])
print('log_loss:',metrics.log_loss(y_testL,prd2))
print('jaccard:',metrics.jaccard_score(y_testL,prd2,average='macro'))
print('有问题的预测子集数:',metrics.zero_one_loss(y_testL,prd2,normalize=False))
print('测试集精度:',metrics.accuracy_score(y_testL,prd2))
print('训练集精度:',metrics.accuracy_score(y_trainL,clf2.predict(X_trainL)))
print(metrics.classification_report(y_testL,prd2))
aa=clf1.predict(X_testS)
bb=0
for i in range(len(y_testS)):
if all(y_testS[i]==aa[i]):
bb+=1
print(bb/len(y_testS))














 3221
3221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











