









本文是学习 多线程服务端编程的练习
书籍作者陈硕的博客也有提到这个题目
http://blog.csdn.net/solstice/article/details/8497475
第一个层次很简单 单机 一个小文件 读进来进行处理 然后对每个单词进行统计排序 记录每个单词出现频率
#include <algorithm>
#include <iostream>
#include <unordered_map>
#include <vector>
#include <sstream>
#include <fstream>
using namespace std;
std::unordered_map<std::string, int> mapStringFrequent;
void SplitStrig(std::string& line, std::vector<std::string>& vecString) {
typedef std::string::size_type strSize;
strSize i = 0;
while (i != line.size()) {
while (i != line.size() && isspace(line[i]))
++i;
strSize j = i;
while (j != line.size() && !isspace(line[j]))
++j;
if (i != j) {
vecString.push_back(line.substr(i, j - i));
i = j;
}
}
}
bool CheckWord(std::string s) {
typedef std::string::size_type strSize;
strSize i = 0;
while (i != s.size()) {
if (isalpha(s[i])) {
i++;
}
else {
return false;
}
}
return true;
}
void VecInputMap(std::vector<std::string>& vecString, std::unordered_map<std::string, int>& mapStringFrequent) {
for (auto it : vecString) {
if (CheckWord(it)) {
transform(it.begin(), it.end(), it.begin(), ::tolower);
mapStringFrequent[it]++;
}
}
}
bool ReadFile(const string& fileName) {
bool ret = false;
std::ifstream in(fileName);
if (in.bad() || !in) {
return ret;
}
std::string line;
std::vector<std::string> vecString;
try {
while (getline(in, line))
{
//std::cout << line << std::endl;
SplitStrig(line, vecString);
}
VecInputMap(vecString, mapStringFrequent);
}
catch (std::exception& e) {
std::cout << line << std::endl;
in.close();
std::cerr << e.what() << std::endl;
return ret;
}
in.close();
ret = true;
return ret;
}
void WriteToFile(const string& fileName, std::vector<std::pair<int, std::string>>& vecWordFreq) {
std::ofstream out(fileName);
if (out.bad() || !out) {
return;
}
for (auto& it : vecWordFreq) {
out << it.second << '\t' << it.first << std::endl;
}
out.close();
}
//============================================================
int main()
{
bool ret = ReadFile("1.txt");
if (!ret)
return -1;
//ret = ReadFile("2.txt");
//if (!ret)
// return -1;
//ret = ReadFile("3.txt");
//if (!ret)
// return -1;
//ret = ReadFile("4.txt");
//if (!ret)
// return -1;
//ret = ReadFile("5.txt");
//if (!ret)
// return -1;
//ret = ReadFile("6.txt");
//if (!ret)
// return -1;
//ret = ReadFile("7.txt");
//if (!ret)
// return -1;
//ret = ReadFile("8.txt");
//if (!ret)
// return -1;
//ret = ReadFile("9.txt");
//if (!ret)
// return -1;
//ret = ReadFile("10.txt");
//if (!ret)
// return -1;
std::vector<std::pair<int, std::string>> freq;
freq.reserve(mapStringFrequent.size());
for (auto& it : mapStringFrequent){
freq.push_back(make_pair(it.second, it.first));
}
std::sort(freq.begin(), freq.end(), [](const std::pair<int, std::string>& lhs, // const auto& lhs in C++14
const std::pair<int, std::string>& rhs) {
return lhs.first > rhs.first;
});
//for (auto it : freq) {
// std::cout << it.first << '\t' << it.second << '\n';
//}
WriteToFile("freqResult.txt", freq);
return 0;
}
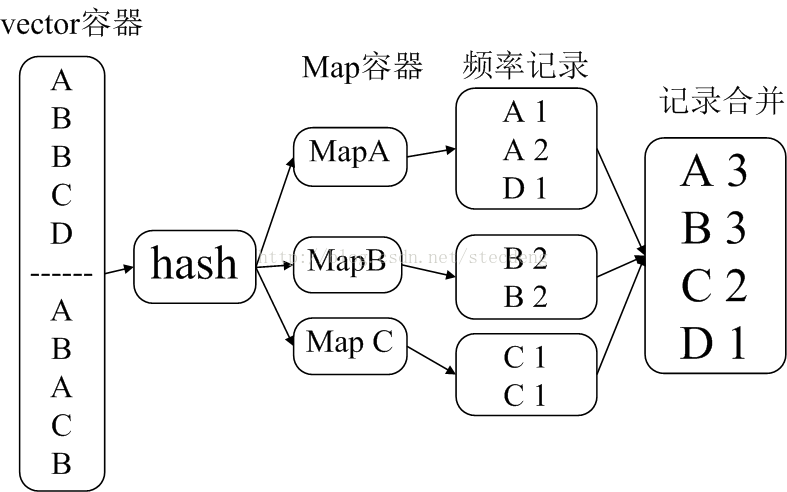
第二个层次 就是文件较大 单词量较多 如果一次性读入并使用vector容器存放 以及使用hash容器进行统计频率 会出现内存等资源不足现象
那么就依次读取进内存 将解析的单词存放进vector中,当vector中的容量到达一个阈值 将vector中的单词放进map容器中统计单词出现频率 vector容器清空
但是map容器有多个 各个单词存放进那个map容器根据hash函数决定
当map容器的容量达到阈值后 写入文件 map容器清空
这样我们就得到多个记录单词出现频率的文本 供后继步骤分析合并 但是一个单词的出现频率肯定只出现在一个记录文本中(因为相同的单词具有相同的hash值 对应同一个记录文本)
如图
代码如下(记录合并代码后继完成)
#include <algorithm>
#include <iostream>
#include <unordered_map>
#include <vector>
#include <sstream>
#include <fstream>
using namespace std;
#define BUCKET_NUM 10
std::unordered_map<std::string, int> mapStringFrequent[BUCKET_NUM];
std::ofstream out[BUCKET_NUM];
#define MAX_WORD_SIZE 1024*1024
void SplitStrig(std::string& line, std::vector<std::string>& vecString) {
typedef std::string::size_type strSize;
strSize i = 0;
while (i != line.size()) {
while (i != line.size() && isspace(line[i]))
++i;
strSize j = i;
while (j != line.size() && !isspace(line[j]))
++j;
if (i != j) {
vecString.push_back(line.substr(i, j - i));
i = j;
}
}
}
bool CheckWord(std::string s) {
typedef std::string::size_type strSize;
strSize i = 0;
while (i != s.size()) {
if (isalpha(s[i])) {
i++;
}
else {
return false;
}
}
return true;
}
void VecInputMap(std::vector<std::string>& vecString, std::unordered_map<std::string, int> mapStringFrequent[]) {
for (auto it : vecString) {
if (CheckWord(it)) {
transform(it.begin(), it.end(), it.begin(), ::tolower);
int idx = std::hash<string>()(it) % BUCKET_NUM;
mapStringFrequent[idx][it]++;
if (mapStringFrequent[idx].size() >= MAX_WORD_SIZE) {
for (auto& it : mapStringFrequent[idx]) {
out[idx] << it.second << '\t' << it.first << std::endl;
}
mapStringFrequent[idx].clear();
}
}
}
}
bool ReadFile(const string& fileName) {
bool ret = false;
std::ifstream in(fileName);
if (in.bad() || !in) {
return ret;
}
std::string line;
std::vector<std::string> vecString;
try {
while (getline(in, line))
{
SplitStrig(line, vecString);
//std::cout << line << std::endl;
if (vecString.size() >= MAX_WORD_SIZE) {
//std::cout << "too many words" << std::endl;
VecInputMap(vecString, mapStringFrequent);
vecString.clear();
}
}
for (int i = 0; i < BUCKET_NUM; i++) {
for (auto& it : mapStringFrequent[i]) {
out[i] << it.second << '\t' << it.first << std::endl;
}
mapStringFrequent[i].clear();
}
}
catch (std::exception& e) {
in.close();
std::cerr << e.what() << std::endl;
return ret;
}
std::cout << vecString.size() << std::endl;
ret = true;
return ret;
}
int main()
{
std::string fileName = "0bucket.txt";
for (int i = 0; i < BUCKET_NUM; i++) {
out[i].close();
out[i].open(fileName);
fileName[0]++;
}
ReadFile("LargeFile.txt");
return 0;
}
运行效果如图
运行前
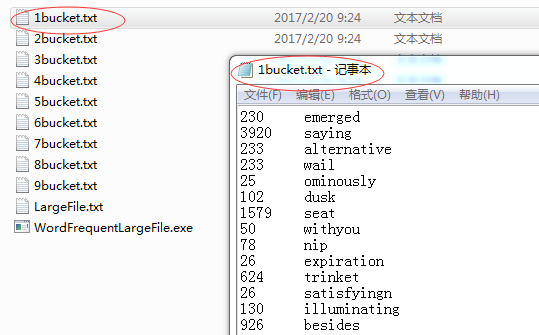
运行后
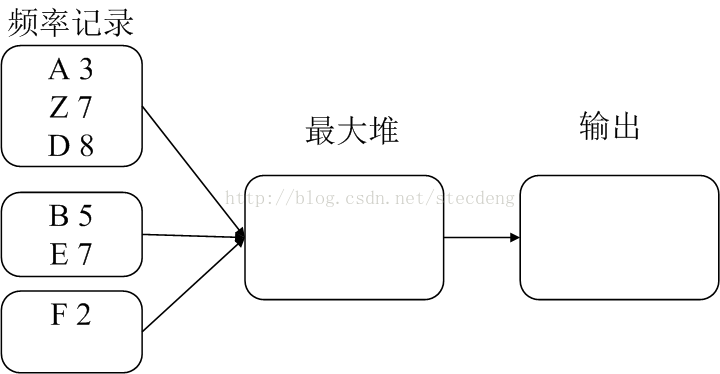
合并步骤如图:
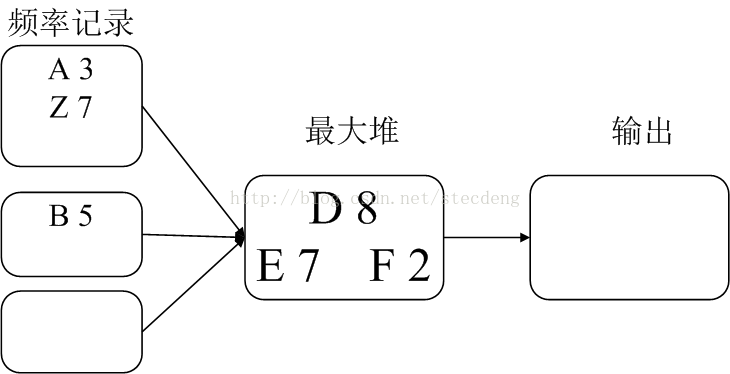
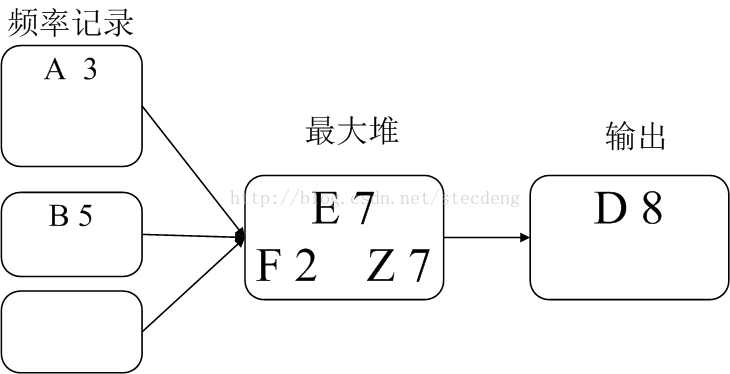
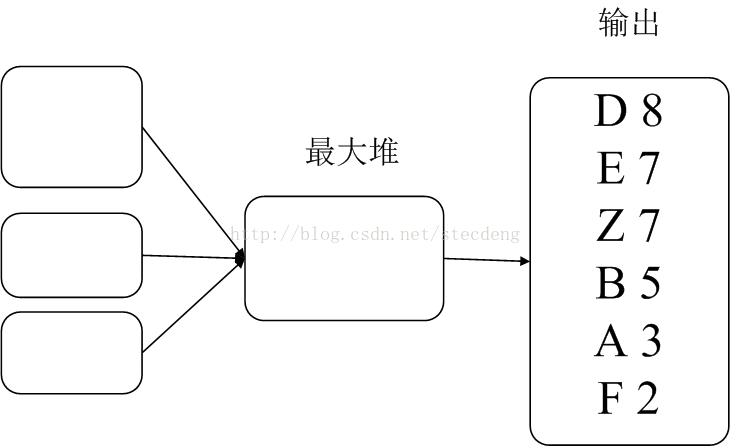
合并代码如下
// WordFrequentMerge.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <algorithm>
#include <iostream>
#include <unordered_map>
#include <deque>
#include <vector>
#include <sstream>
#include <fstream>
using namespace std;
#define DEFAULT_FILE_NAME "0bucket.txt"
#define BUCKET_NUM 10
std::ifstream in[BUCKET_NUM];
std::deque<std::pair<int, std::string>> deqFreqRecord[BUCKET_NUM];
void OpenFile() {
std::string fileName = "0bucket.txt";
for (int i = 0; i < BUCKET_NUM; i++) {
in[i].close();
in[i].open(fileName);
if (in[i].bad() || !in[i]) {
std::cerr << "open file error.exit!!" << std::endl;
return;
}
fileName[0]++;
}
}
void ReadSortEle_(std::ifstream& in, std::deque<std::pair<int, std::string>>& d) {
std::string line,word;
int freq;
try {
while (getline(in, line)) {
std::string::size_type pos = line.find('\t');
if (pos != std::string::npos) {
freq = std::stoi(line.substr(0, pos));
word = line.substr(pos + 1);
//std::cout << word << "\t" << freq << std::endl;
d.push_back(std::make_pair(freq, word));
}
}
}
catch (std::exception& e) {
std::cout << e.what() << std::endl;
return;
}
std::sort(d.begin(),d.end(), [](const std::pair<int, std::string>& lhs,
const std::pair<int, std::string>& rhs) {
return lhs.first > rhs.first;
});
}
void ReadSortEle(std::ifstream in[], std::deque<std::pair<int, std::string>> d[]) {
for (int i = 0; i < BUCKET_NUM; i++) {
ReadSortEle_(in[i],d[i]);
}
}
bool HeapCompareFunc(std::pair<int, std::string>& l,
std::pair<int, std::string>& r) {
return l.first < r.first;
}
void MergeFrequent(std::deque<std::pair<int, std::string>> d[]) {
vector<std::pair<int, std::string>> vecHeap;
for (int i = 0; i < BUCKET_NUM; i++) {
if (!d[i].empty()) {
vecHeap.push_back(d[i].front());
d[i].pop_front();
}
}
std::make_heap(vecHeap.begin(), vecHeap.end(), HeapCompareFunc);
while (!vecHeap.empty()) {
std::pop_heap(vecHeap.begin(), vecHeap.end(), HeapCompareFunc);
std::pair<int, std::string> p = vecHeap.back();
vecHeap.pop_back();
std::cout << p.second << "\t" << p.first << std::endl;
int idx = std::hash<string>()(p.second) % BUCKET_NUM;
if (!d[idx].empty()) {
vecHeap.push_back(d[idx].front());
std::push_heap(vecHeap.begin(), vecHeap.end(), HeapCompareFunc);
d[idx].pop_front();
}
}
}
int main()
{
OpenFile();
ReadSortEle(in, deqFreqRecord);
MergeFrequent(deqFreqRecord);
return 0;
}
代码还有诸多待优化地方
比如读入单词后 另开线程处理而不是等待处理完毕后再读取单词
比如数据的传递 考虑传递指针和起始位置 而不是传递拷贝
技术博客 http://blog.csdn.net/stecdeng 技术交流群 群号码:324164944 欢迎c c++ windows驱动爱好者 服务器程序员沟通交流














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









