









真的好久没有写博客了,正好最近在研究PBFT,那就从PBFT开始写起吧!
先奉上大佬@byron1st写的PBFT代码:https://github.com/bigpicturelabs/simple_pbft
我会带着大家鹿一遍源代码!因为看到网上好多的博客都是互相抄袭,对大家一点帮助没有
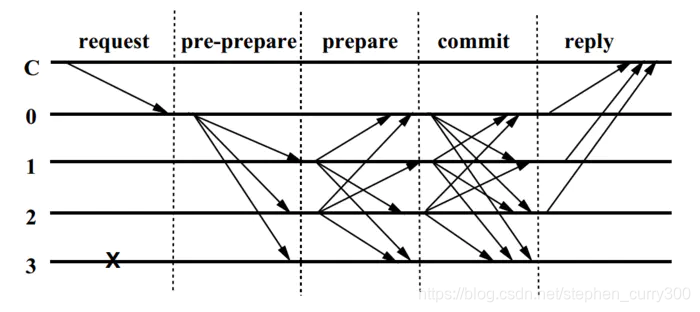
整个代码逻辑都是围绕这张图来的!
PBFT算法基础理论部分:https://www.jianshu.com/p/cf1010f39b84
文章目录
1.服务的启动主函数
func main() {
nodeID := os.Args[1] // 这边就是传进来的公司的名称
server := network.NewServer(nodeID)
server.Start()
}
这是整个PBFT的启动主函数,可以看到会获取用户输入的数值作为nodeID,然后调用network包中的NewServer函数定义一个服务(可以理解成一个节点的client窗口),然后开始启动server.Start()
2.NewServer函数
这里会给完整的流程图,等我写完所有的部分会重新画的
func NewServer(nodeID string) *Server {
// 根据传进来的NodeID新建了一个节点,节点的默认视图是1000000,并且该节点启动了三个协程:dispatchMsg、alarmToDispatcher、resolveMsg
node := NewNode(nodeID)
// 启动服务
server := &Server{node.NodeTable[nodeID], node}
// 设置路由
server.setRoute()
return server
}
我们可以看到NewServer函数主要干了三件事:
- 根据传进来的nodeID创建一个节点
- 创建一个server服务
- 设置路由
2.1 NewNode(nodeID)
我们先来看第一件事,就是创建一个node,进入node类,看一下node到底在干嘛!
func NewNode(nodeID string) *Node {
const viewID = 10000000000 // temporary.
node := &Node{
// Hard-coded for test.
NodeID: nodeID,
NodeTable: map[string]string{
"Apple": "localhost:1111",
"MS": "localhost:1112",
"Google": "localhost:1113",
"IBM": "localhost:1114",
},
View: &View{
ID: viewID,
Primary: "Apple", // 主节点是Apple公司
},
// Consensus-related struct
CurrentState: nil,
CommittedMsgs: make([]*consensus.RequestMsg, 0), // 被提交的信息
MsgBuffer: &MsgBuffer{
ReqMsgs: make([]*consensus.RequestMsg, 0),
PrePrepareMsgs: make([]*consensus.PrePrepareMsg, 0),
PrepareMsgs: make([]*consensus.VoteMsg, 0),
CommitMsgs: make([]*consensus.VoteMsg, 0),
},
// Channels
MsgEntrance: make(chan interface{}), // 无缓冲的信息接收通道
MsgDelivery: make(chan interface{}), // 无缓冲的信息发送通道
Alarm: make(chan bool),
}
// 启动消息调度器
go node.dispatchMsg()
// Start alarm trigger
go node.alarmToDispatcher()
// 开始信息表决
go node.resolveMsg()
return node
}
这边的NewNode其实就是新建了一个节点,并且定义了node结构体中的一些属性信息,node结构体如下:
// 节点
type Node struct {
NodeID string
NodeTable map[string]string // key=nodeID, value=url
View *View
CurrentState *consensus.State
CommittedMsgs []*consensus.RequestMsg // kinda block.
MsgBuffer *MsgBuffer
MsgEntrance chan interface{}
MsgDelivery chan interface{}
Alarm chan bool
}
我们一步步剖析NewNode
- 初始化视图编号
const viewID = 10000000000 - 定义了node结构体中的一些属性信息
| 属性 | 值 | 说明 |
|---|---|---|
| NodeID | nodeID | 节点ID |
| NodeTable | map[string]string | 节点索引表 |
| View | &View | 设置视图编号和主节点 |
| CurrentState | nil | 默认当前节点的状态为nil |
| CommittedMsgs | make([]*consensus.RequestMsg, 0) | 被提交的信息 |
| MsgBuffer | &MsgBuffer | 四种消息类型缓冲列表 |
| MsgEntrance | make(chan interface{}) | 无缓冲的信息接收通道 |
| MsgDelivery | make(chan interface{}) | 无缓冲的信息发送通道 |
| Alarm | make(chan bool) | 警告通道 |
- 紧接着我们可以看到每一个node都开启了3个
goroutine- dispatchMsg
- alarmToDispatcher
- resolveMsg
我们先重点关注一下两个协程goroutine
2.1.1 协程1:dispatchMsg
func (node *Node) dispatchMsg() {
for {
select {
case msg := <-node.MsgEntrance: // 如果MsgEntrance通道有消息传送过来,拿到msg
err := node.routeMsg(msg) // 进行routeMsg
if err != nil {
fmt.Println(err)
// TODO: send err to ErrorChannel
}
case <-node.Alarm:
err := node.routeMsgWhenAlarmed()
if err != nil {
fmt.Println(err)
// TODO: send err to ErrorChannel
}
}
}
}
这里需要你对
for select多路复用有所了解!
我们可以从dispatchMsg的代码中看到,只要MsgEnrance通道中有值,就会传递给一个中间变量msg,然后进行消息路由转发routeMsg。
func (node *Node) routeMsg(msg interface{}) []error {
switch msg.(type) {
case *consensus.RequestMsg:
if node.CurrentState == nil {
// Copy buffered messages first.
msgs := make([]*consensus.RequestMsg, len(node.MsgBuffer.ReqMsgs))
copy(msgs, node.MsgBuffer.ReqMsgs)
// Append a newly arrived message.
msgs = append(msgs, msg.(*consensus.RequestMsg))
// Empty the buffer.
node.MsgBuffer.ReqMsgs = make([]*consensus.RequestMsg, 0)
// Send messages.
node.MsgDelivery <- msgs
} else {
node.MsgBuffer.ReqMsgs = append(node.MsgBuffer.ReqMsgs, msg.(*consensus.RequestMsg))
}
... 其他类型的信息数据
return nil
}
我们刚开始先以RequestMsg为例,因为其他类型的消息数据的执行逻辑与RequestMsg几乎是一致的!这是节点会面临两种选择:
- 当CurrentState 为 nil 时,将consensus.RequestMsg的信息复制给中间变量msgs,然后清空重置!并将msgs中的信息发送给MsgDelivery通道!(我们还记得node一直开了3个goroutine嘛,这边传出去,另外一个goroutine
resolveMsg会立马接受这个通道中的信息) - 当CurrentState 不为 nil 时,直接往MsgBuffer缓冲通道中进行添加,这边会涉及到数组扩容的问题(可以了解一下)
2.1.2 协程2:resolveMsg
func (node *Node) resolveMsg() {
for {
// 从调度器中获取缓存信息
msgs := <-node.MsgDelivery
switch msgs.(type) {
case []*consensus.RequestMsg:
// 节点表决决策信息
errs := node.resolveRequestMsg(msgs.([]*consensus.RequestMsg))
if len(errs) != 0 {
for _, err := range errs {
fmt.Println(err)
}
// TODO: send err to ErrorChannel
}
... 替他类型的信息数据
}
}
}
这边我也先只以RequestMsg进行讲解!我们可以清楚的看到node.MsgDelivery这边在等着调度器dispatchMsg那边传递消息过来,因为两个缓冲通道都是无缓冲的,没有消息会一直阻塞在这边!
下面就是执行resolveRequestMsg函数了:
// 节点表决请求阶段的信息
func (node *Node) resolveRequestMsg(msgs []*consensus.RequestMsg) []error {
errs := make([]error, 0)
// 表决信息
for _, reqMsg := range msgs {
err := node.GetReq(reqMsg)
if err != nil {
errs = append(errs, err)
}
}
if len(errs) != 0 {
return errs
}
return nil
}
在resolveRequestMsg代码块中,我们可以看到主要的执行逻辑就是调用了GetReq函数
// 主节点开始全局的共识
func (node *Node) GetReq(reqMsg *consensus.RequestMsg) error {
LogMsg(reqMsg)
// Create a new state for the new consensus.
err := node.createStateForNewConsensus()
if err != nil {
return err
}
// 开始共识程序
prePrepareMsg, err := node.CurrentState.StartConsensus(reqMsg)
if err != nil {
return err
}
LogStage(fmt.Sprintf("Consensus Process (ViewID:%d)", node.CurrentState.ViewID), false)
// 发现getPrePrepare信息
// 这边主节点开始向其他节点发送预准备消息了
if prePrepareMsg != nil {
node.Broadcast(prePrepareMsg, "/preprepare")
LogStage("Pre-prepare", true)
}
return nil
}
- 创建一个新的共识状态
createStateForNewConsensus - 对节点当前状态开始共识
StartConsensus - 共识完成之后,主节点向其他节点广播
prePrepareMsg阶段的信息!
这边先去看第3章共识过程
2.2 setRoute函数
func (server *Server) setRoute() {
http.HandleFunc("/req", server.getReq)
http.HandleFunc("/preprepare", server.getPrePrepare)
http.HandleFunc("/prepare", server.getPrepare)
http.HandleFunc("/commit", server.getCommit)
http.HandleFunc("/reply", server.getReply)
}
3.Request共识过程
3.0 共识流程图
这张流程图是为了方便大家理解,等你梳理完整个流程,再回过头来重新看我画的这个流程图,思路应该会更清晰一点!
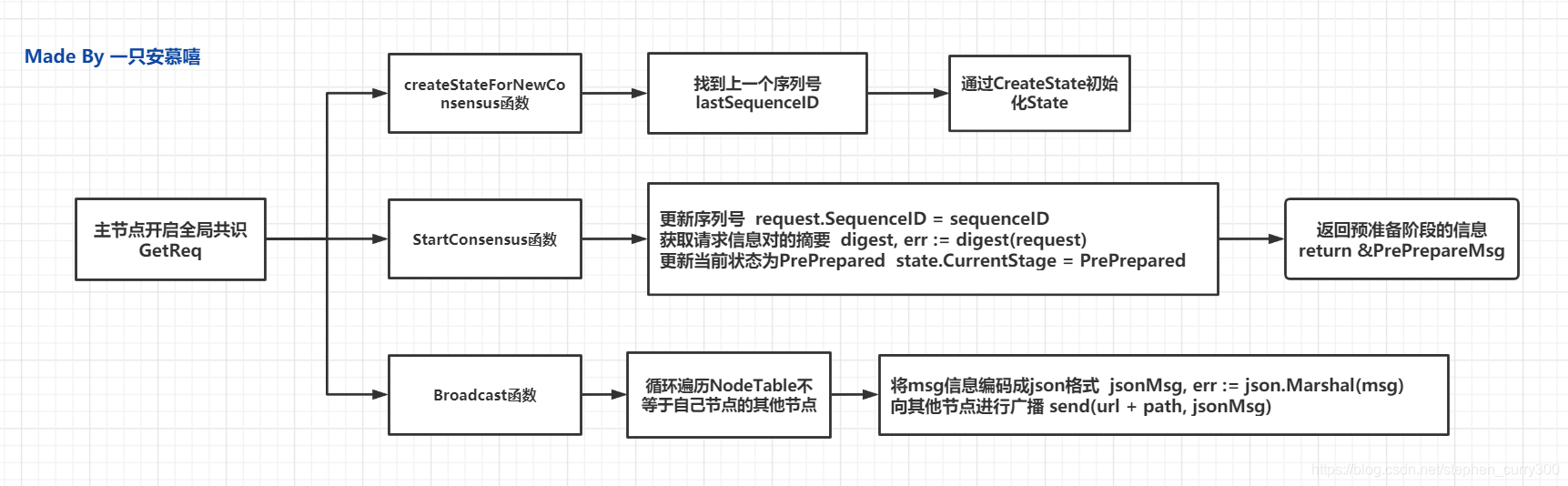
一只安慕嘻是我的B站账号,大家也可以关注 o(´^`)o
3.1 创建状态createStateForNewConsensus
func (node *Node) createStateForNewConsensus() error {
// Check if there is an ongoing consensus process.
if node.CurrentState != nil {
return errors.New("another consensus is ongoing")
}
// Get the last sequence ID
var lastSequenceID int64
if len(node.CommittedMsgs) == 0 {
lastSequenceID = -1
} else {
lastSequenceID = node.CommittedMsgs[len(node.CommittedMsgs) - 1].SequenceID
}
// Create a new state for this new consensus process in the Primary
node.CurrentState = consensus.CreateState(node.View.ID, lastSequenceID)
LogStage("Create the replica status", true)
return nil
}
- 首选判断当前节点的状态是不是为nil,也就是说判断当前节点是不是处于其他阶段(预准备阶段或者准备阶段等等)
- 判断当前阶段是否已经发送过消息,如果是首次进行共识,则上一个序列号
lastSequenceID设置为-1,否则我们取出上一个序列号 - 创建状态
CreateState,主要是初始化State之后返回
func CreateState(viewID int64, lastSequenceID int64) *State {
return &State{
ViewID: viewID,
MsgLogs: &MsgLogs{
ReqMsg:nil,
PrepareMsgs:make(map[string]*VoteMsg),
CommitMsgs:make(map[string]*VoteMsg),
},
LastSequenceID: lastSequenceID,
CurrentStage: Idle,
}
}
3.2 开始共识StartConsensus
// 主节点开始共识
func (state *State) StartConsensus(request *RequestMsg) (*PrePrepareMsg, error) {
// 消息的序号为sequenceID,也就是当前时间
sequenceID := time.Now().UnixNano()
// Find the unique and largest number for the sequence ID
if state.LastSequenceID != -1 {
for state.LastSequenceID >= sequenceID {
sequenceID += 1
}
}
// Assign a new sequence ID to the request message object.
request.SequenceID = sequenceID
// Save ReqMsgs to its logs.
state.MsgLogs.ReqMsg = request
// 得到客户端请求消息requestMsg的摘要
digest, err := digest(request)
if err != nil {
fmt.Println(err)
return nil, err
}
// 将当前阶段转换到PrePrepared阶段
state.CurrentStage = PrePrepared
// 这边其实就是主节点向其他节点发送消息的格式:视图ID,请求的序列号,请求信息和请求信息的摘要
return &PrePrepareMsg{
ViewID: state.ViewID,
SequenceID: sequenceID,
Digest: digest,
RequestMsg: request,
}, nil
}
- 首先使用当前的时间戳作为序列号
- 如果上一个序列号 >= 当前序列号,当前序列号+1,目的很简单,主节点每开始一次共识,序列号+1
- 进行序号号
SequenceID的更新,获取请求信息的摘要digest(request),将当前状态转化为PrePrepared
3.3 广播消息Broadcast
// 节点广播函数
func (node *Node) Broadcast(msg interface{}, path string) map[string]error {
errorMap := make(map[string]error)
for nodeID, url := range node.NodeTable {
// 因为不需要向自己进行广播了,所以就直接跳过
if nodeID == node.NodeID {
continue
}
// 将msg信息编码成json格式
jsonMsg, err := json.Marshal(msg)
if err != nil {
errorMap[nodeID] = err
continue
}
// 将json格式传送给其他的节点
send(url + path, jsonMsg) // url localhost:1111 path:/prepare等等
// send函数:http.Post("http://"+url, "application/json", buff)
}
if len(errorMap) == 0 {
return nil
} else {
return errorMap
}
}
- 遍历node节点初始化时自带的节点列表
node.NodeTable - 将msg信息编码成json格式
json.Marshal(msg),然后发送给其他节点send(url + path, jsonMsg)
func send(url string, msg []byte) {
buff := bytes.NewBuffer(msg)
_, _ = http.Post("http://"+url, "application/json", buff)
}
4.PrePrepare共识过程
顺便帮助大家回忆一下,在resolveMsg相应的goroutine中会判断传进来的
信息类型,前面一直说的是request类型,现在我们开始鹿PrePrepare的代码
case []*consensus.PrePrepareMsg:
errs := node.resolvePrePrepareMsg(msgs.([]*consensus.PrePrepareMsg))
if len(errs) != 0 {
for _, err := range errs {
fmt.Println(err)
}
// TODO: send err to ErrorChannel
}
调用resolvePrePrepareMsg函数,开启prePrepareMsg的共识
func (node *Node) resolvePrePrepareMsg(msgs []*consensus.PrePrepareMsg) []error {
errs := make([]error, 0)
// Resolve messages
for _, prePrepareMsg := range msgs {
err := node.GetPrePrepare(prePrepareMsg)
if err != nil {
errs = append(errs, err)
}
}
if len(errs) != 0 {
return errs
}
return nil
}
对于每一个prePrepareMsg 信息会调用GetPrePrepare函数,下面正式开始共识!
// 到了预准备阶段,所有节点开始参与共识
func (node *Node) GetPrePrepare(prePrepareMsg *consensus.PrePrepareMsg) error {
LogMsg(prePrepareMsg)
// Create a new state for the new consensus.
err := node.createStateForNewConsensus()
if err != nil {
return err
}
prePareMsg, err := node.CurrentState.PrePrepare(prePrepareMsg)
if err != nil {
return err
}
if prePareMsg != nil {
// Attach node ID to the message
prePareMsg.NodeID = node.NodeID
LogStage("Pre-prepare", true)
node.Broadcast(prePareMsg, "/prepare")
LogStage("Prepare", false)
}
return nil
}
4.1 创建状态createStateForNewConsensus
这边跟request阶段是一样的,所以就省略啦!
4.2 开始共识PrePrepare
// 预准备阶段的共识
func (state *State) PrePrepare(prePrepareMsg *PrePrepareMsg) (*VoteMsg, error) {
// Get ReqMsgs and save it to its logs like the primary.
state.MsgLogs.ReqMsg = prePrepareMsg.RequestMsg
// 验证视图ID、消息序列号和信息摘要是否正确
if !state.verifyMsg(prePrepareMsg.ViewID, prePrepareMsg.SequenceID, prePrepareMsg.Digest) {
return nil, errors.New("当前节点预准备阶段消息是错误的")
}
// Change the stage to pre-prepared.
state.CurrentStage = PrePrepared
return &VoteMsg{
ViewID: state.ViewID,
SequenceID: prePrepareMsg.SequenceID,
Digest: prePrepareMsg.Digest,
MsgType: PrepareMsg,
}, nil
}
- 进行状态验证
- 将当前阶段改为
PrePrepared
4.2.1 验证过程
// 验证
func (state *State) verifyMsg(viewID int64, sequenceID int64, digestGot string) bool {
// Wrong view. That is, wrong configurations of peers to start the consensus.
if state.ViewID != viewID {
return false
}
// Check if the Primary sent fault sequence number. => Faulty primary.
// TODO: adopt upper/lower bound check.
if state.LastSequenceID != -1 {
if state.LastSequenceID >= sequenceID {
return false
}
}
digest, err := digest(state.MsgLogs.ReqMsg)
if err != nil {
fmt.Println(err)
return false
}
// Check digest.
if digestGot != digest {
return false
}
return true
}
- 验证传进来的视图ID是否与当前状态的视图ID一致
- 验证序号号是否为当前最大值
- 验证当前的摘要是否与原始的request信息摘要是一致的
4.3 广播Broadcast
广播和request阶段也是一样的,所以也忽略啦!

















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









