







Avalanche是个用来做continual learning的end-to-end的库。作用是帮助研究者编写continual learning的程序。在保证了每个模块的完整性和独立性的基础上,保留了它们的扩展性和有效性,即使用者可以利用其框架编写自己的CL算法或导入自己的数据集。
官网:https://avalanche.continualai.org/
paper:https://arxiv.org/abs/2104.00405
github:https://github.com/ContinualAI/avalanche
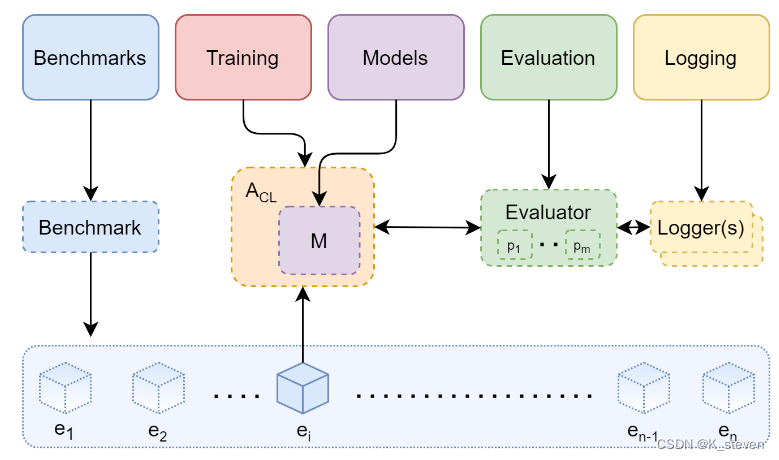
对Continual Learning框架的定义:
整个过程可以看作对Continual Learning算法A的不断更新。所谓更新是指改变它内部的模型M和数据结构D。更新手段是使用一系列的不固定的经验流(e1,…, en)进行训练。更新的目标是让其在测试的经验流(e1t,…,ent)上的evaluation指标有更好的表现。

主要框架:
1. Benchmarks
a. datasets:import现有的数据集
b. classic benchmarks:经典的benchmarks
c. generators:新建Benchmarks
2. Training
a. Strategies:使用现有的continual learning方法或baselines
包括Naive, CWRStar, Replay, GDumb, Cumulative, LwF, GEM, AGEM, EWC, AR1
b. Create Strategy:编写自己的strategy
3. Evaluation
a. Evaluation: 使用Metrics和Loggers对模型进行评估和记录
Metrics 包括Accuracy, Forgetting, Memory Usage, Running Times, etc.
代码demo,前面是每个模块的使用方法,最后一部分是测试example
################## 1. Benchmarks
# ---------------------------- 1.1 import datasets ---------------------------------------- #
from avalanche.benchmarks.datasets import MNIST, FashionMNIST, KMNIST, EMNIST, \
QMNIST, FakeData, CocoCaptions, CocoDetection, LSUN, ImageNet, CIFAR10, \
CIFAR100, STL10, SVHN, PhotoTour, SBU, Flickr8k, Flickr30k, VOCDetection, \
VOCSegmentation, Cityscapes, SBDataset, USPS, HMDB51, UCF101, CelebA, \
CORe50Dataset, TinyImagenet, CUB200, OpenLORIS, MiniImageNetDataset, \
Stream51, CLEARDataset
# ---------------------------- 1.2 classic benchmarks ---------------------------------------- #
from avalanche.benchmarks.classic import CORe50, SplitTinyImageNet, SplitCIFAR10, \
SplitCIFAR100, SplitCIFAR110, SplitMNIST, RotatedMNIST, PermutedMNIST, SplitCUB200
# creating the benchmark (scenario object)
perm_mnist = PermutedMNIST(
n_experiences=3,
seed=1234,
)
# recovering the train and test streams
train_stream = perm_mnist.train_stream
test_stream = perm_mnist.test_stream
# iterating over the train stream
for experience in train_stream:
print("Start of task ", experience.task_label)
print('Classes in this task:', experience.classes_in_this_experience)
# The current Pytorch training set can be easily recovered through the
# experience
current_training_set = experience.dataset
# ...as well as the task_label
print('Task {}'.format(experience.task_label))
print('This task contains', len(current_training_set), 'training examples')
# we can recover the corresponding test experience in the test stream
current_test_set = test_stream[experience.current_experience].dataset
print('This task contains', len(current_test_set), 'test examples')
# ---------------------------- 1.3 benchmarks generators ---------------------------------------- #
from avalanche.benchmarks.generators import nc_benchmark, ni_benchmark
from torchvision.datasets import MNIST
mnist_train = MNIST('.', train=True, download=True)
mnist_test = MNIST('.', train=False)
benchmark = ni_benchmark(
mnist_train, mnist_test, n_experiences=10, shuffle=True, seed=1234,
balance_experiences=True
)
benchmark = nc_benchmark(
mnist_train, mnist_test, n_experiences=10, shuffle=True, seed=1234,
task_labels=False
)
# ---------------------------- 1.4 generic generators ---------------------------------------- #
from avalanche.benchmarks.generators import filelist_benchmark, dataset_benchmark, \
tensors_benchmark, paths_benchmark
################## 2. Training
# ---------------------------- 2.1 strategies ---------------------------------------- #
from avalanche.models import SimpleMLP
from avalanche.training import Naive, CWRStar, Replay, GDumb, \
Cumulative, LwF, GEM, AGEM, EWC, AR1
from torch.optim import SGD
from torch.nn import CrossEntropyLoss
model = SimpleMLP(num_classes=10)
cl_strategy = Naive(
model, SGD(model.parameters(), lr=0.001, momentum=0.9),
CrossEntropyLoss(), train_mb_size=100, train_epochs=4, eval_mb_size=100
)
# ---------------------------- 2.2 create new strategy ---------------------------------------- #
from torch.utils.data import DataLoader
class MyStrategy():
"""My Basic Strategy"""
def __init__(self, model, optimizer, criterion):
self.model = model
self.optimizer = optimizer
self.criterion = criterion
def train(self, experience):
# here you can implement your own training loop for each experience (i.e.
# batch or task).
train_dataset = experience.dataset
t = experience.task_label
train_data_loader = DataLoader(
train_dataset, num_workers=4, batch_size=128
)
for epoch in range(1):
for mb in train_data_loader:
# you magin here...
pass
def eval(self, experience):
# here you can implement your own eval loop for each experience (i.e.
# batch or task).
eval_dataset = experience.dataset
t = experience.task_label
eval_data_loader = DataLoader(
eval_dataset, num_workers=4, batch_size=128
)
# eval here
# ---------------------------- 2.2 create new strategy - use it ---------------------------------------- #
from avalanche.models import SimpleMLP
from avalanche.benchmarks import SplitMNIST
# Benchmark creation
benchmark = SplitMNIST(n_experiences=5)
# Model Creation
model = SimpleMLP(num_classes=benchmark.n_classes)
# Create the Strategy Instance (MyStrategy)
cl_strategy = MyStrategy(
model, SGD(model.parameters(), lr=0.001, momentum=0.9),
CrossEntropyLoss())
# Training Loop
print('Starting experiment...')
for exp_id, experience in enumerate(benchmark.train_stream):
print("Start of experience ", experience.current_experience)
cl_strategy.train(experience)
print('Training completed')
print('Computing accuracy on the current test set')
cl_strategy.eval(benchmark.test_stream[exp_id])
################## 3. Evaluation
# utility functions to create plugin metrics
from avalanche.evaluation.metrics import accuracy_metrics, loss_metrics, forgetting_metrics
from avalanche.logging import InteractiveLogger, TensorboardLogger
from avalanche.training.plugins import EvaluationPlugin
eval_plugin = EvaluationPlugin(
# accuracy after each training epoch
# and after each evaluation experience
accuracy_metrics(epoch=True, experience=True),
# loss after each training minibatch and each
# evaluation stream
loss_metrics(minibatch=True, stream=True),
# catastrophic forgetting after each evaluation
# experience
forgetting_metrics(experience=True, stream=True),
# add as many metrics as you like
loggers=[InteractiveLogger(), TensorboardLogger()])
# pass the evaluation plugin instance to the strategy
# strategy = EWC(..., evaluator=eval_plugin)
# THAT'S IT!!
# ---------------------------- Example ---------------------------------------- #
from avalanche.benchmarks.classic import SplitMNIST
from avalanche.evaluation.metrics import forgetting_metrics, accuracy_metrics,\
loss_metrics, timing_metrics, cpu_usage_metrics, StreamConfusionMatrix,\
disk_usage_metrics, gpu_usage_metrics
from avalanche.models import SimpleMLP
from avalanche.logging import InteractiveLogger, TextLogger, TensorboardLogger
from avalanche.training.plugins import EvaluationPlugin
from avalanche.training import Naive
from torch.optim import SGD
from torch.nn import CrossEntropyLoss
benchmark = SplitMNIST(n_experiences=5)
# MODEL CREATION
model = SimpleMLP(num_classes=benchmark.n_classes)
# DEFINE THE EVALUATION PLUGIN and LOGGERS
# The evaluation plugin manages the metrics computation.
# It takes as argument a list of metrics, collectes their results and returns
# them to the strategy it is attached to.
# log to Tensorboard
tb_logger = TensorboardLogger()
# log to text file
text_logger = TextLogger(open('log.txt', 'a'))
# print to stdout
interactive_logger = InteractiveLogger()
eval_plugin = EvaluationPlugin(
accuracy_metrics(minibatch=True, epoch=True, experience=True, stream=True),
loss_metrics(minibatch=True, epoch=True, experience=True, stream=True),
timing_metrics(epoch=True),
cpu_usage_metrics(experience=True),
forgetting_metrics(experience=True, stream=True),
StreamConfusionMatrix(num_classes=benchmark.n_classes, save_image=False),
disk_usage_metrics(minibatch=True, epoch=True, experience=True, stream=True),
loggers=[interactive_logger, text_logger, tb_logger]
)
# CREATE THE STRATEGY INSTANCE (NAIVE)
cl_strategy = Naive(
model, SGD(model.parameters(), lr=0.001, momentum=0.9),
CrossEntropyLoss(), train_mb_size=500, train_epochs=1, eval_mb_size=100,
evaluator=eval_plugin)
# TRAINING LOOP
print('Starting experiment...')
results = []
for experience in benchmark.train_stream:
print("Start of experience: ", experience.current_experience)
print("Current Classes: ", experience.classes_in_this_experience)
# train returns a dictionary which contains all the metric values
res = cl_strategy.train(experience, num_workers=4)
print('Training completed')
print('Computing accuracy on the whole test set')
# eval also returns a dictionary which contains all the metric values
results.append(cl_strategy.eval(benchmark.test_stream, num_workers=4))
报错与解决:
- TypeError: No loop matching the specified signature and casting was found for ufunc greater
解决:降低numpy版本从1.24到1.22 - The “freeze_support()” line can be omitted if the program is not going to be frozen to produce an executable.
参考issue
解决:将num_workers设置为num_workers=0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









