







一、用户缓冲区和系统缓冲区
缓冲区的概念确实可以分为多个层次,其中最常见的两个层次是用户缓冲区和系统缓冲区。
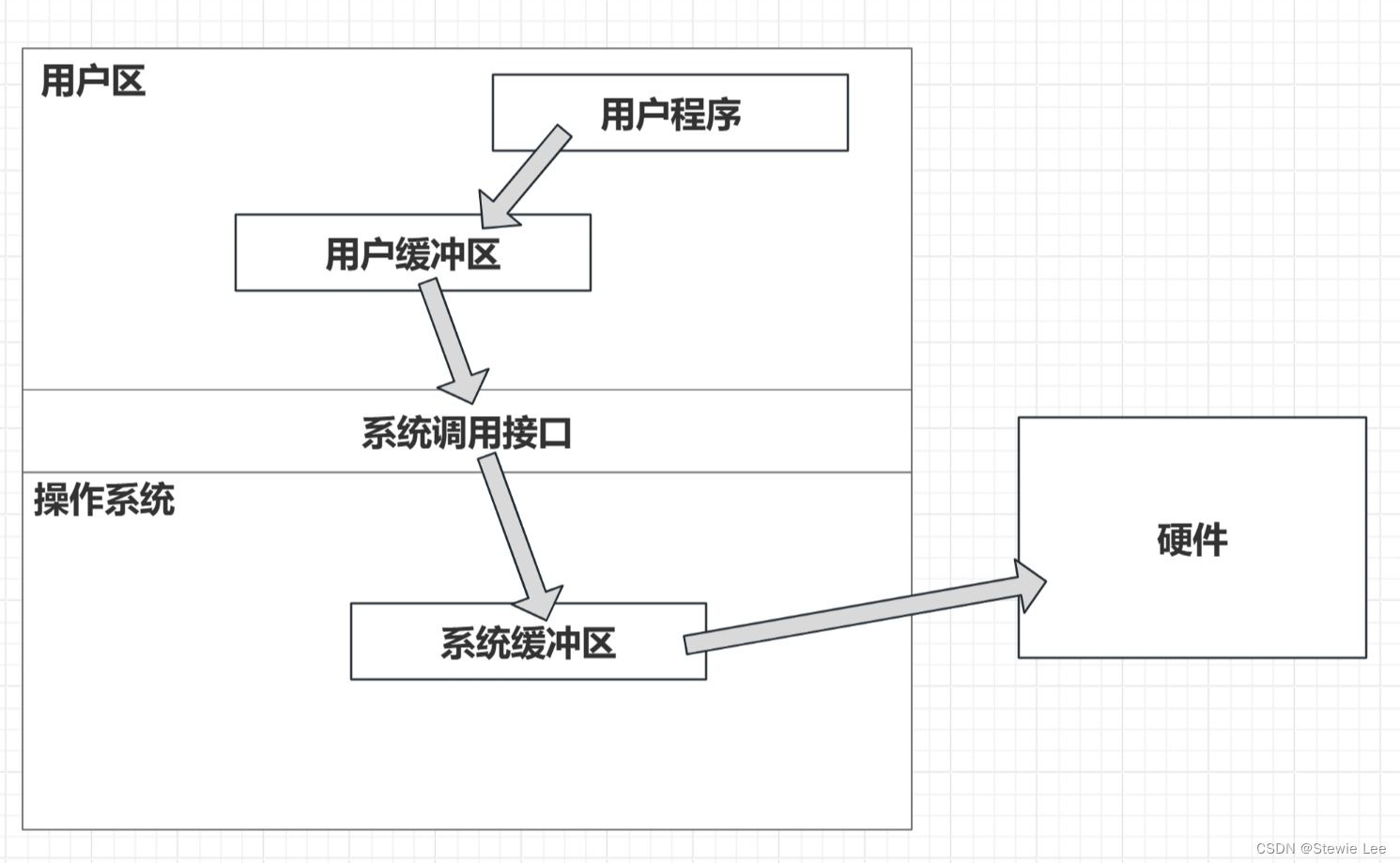
这里的用户缓冲区和系统缓冲区都包括输入输出缓冲区。
1、用户缓冲区(User-space Buffer)
用户缓冲区是指由用户程序(如C语言程序)在用户空间(即非内核空间)中分配和管理的内存区域。在C语言中,当使用标准I/O库(如stdio.h中定义的函数)进行文件操作时,标准I/O库会自动为每个打开的文件流(FILE*)分配一个用户缓冲区。这个缓冲区用于暂存读取或写入的数据,以减少对系统调用的依赖,从而提高I/O效率。我们下面将对这个缓冲区进行详细的讲解。
用户缓冲区的特点:
-
由用户程序控制,通常由C标准I/O库管理。
-
用于减少系统调用的次数,提高I/O效率。
-
可以通过
setvbuf或setbuf函数来设置缓冲区的大小和类型(全缓冲、行缓冲、无缓冲)。
2、系统(内核)缓冲区(Kernel-space Buffer)
系统缓冲区是指由操作系统内核在系统空间中分配和管理的内存区域。当用户程序通过系统调用(如read、write)进行文件I/O
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









