







1.Innodb数据存储
innodb如今能够做到mysql的默认数据存储引擎,肯定有着其好处的,那么innodb有什么好处呢?
1. 当意外断电或者重启, InnoDB 能够做到奔溃恢复,撤销没有提交的数据2.InnoDB 存储引擎维护自己的缓冲池,在访问数据时将表和索引数据缓存到主存中。经常使用的数据直接从内存中处理。这种缓存适用于许多类型的信息,并加快了处理速度。在专用数据库服务器上,高达80% 的物理内存通常分配给缓冲池3.where 、 groupby 、 orderBy 的自动优化、基于索引。4. 插入、更新和删除是通过一种称为更改缓冲的自动机制进行优化的
innodb存储引擎是作为数据存储的,那么肯定是要落盘的,那么落盘落到哪里?innodb又是如何管理这些数据的呢?
在Innodb中会有一个表空间的概念,又可以分为很多的类型,比如系统表空间、通用表空间、独立表空间等,我们的数据可以有选择的决定存入到哪个表空间中,关于表空间的具体介绍可以参考官网,这里不再介绍,MySQL :: MySQL 8.0 Reference Manual :: 17.6.3 Tablespaces
那么表空间又是如何管理的呢? 每个表空间都是由大小相同的page页来组成的,默认page页是16kb,也可以根据innodb_page_size来设定页的大小
在表空间中从上到下会依次划分为segment(段)、extent(区)、page(页)、rows(行)
segment: 段是表空间的分区,一个表空间中,会有多个段组成,常见的短有数据段、索引段、8.0之前有回滚段
extent: 区来管理页,当页的大小在16K以下,一个区的大小是1M,如果32K是2M,64K则为4M。后面磁盘释放分配都是以区为单位. 所以,一个extent下最少可以存储64个page页
page:对于4KB、8KB、16KB和32KB的innodb_page_size设置,最大行长度略小于数据库页面大小的一半。例如,对于默认的16KB InnoDB页面大小,最大行长度略小于8KB。对于64KB的innodb_page_size设置,最大行长度略小于16KB
rows:表的行格式决定了其行的物理存储方式,这反过来又会影响查询和 DML 操作的性能,为什么影响 我们在讲索引的时候会讲到
行存储如果超过,那么该页就只存储指针,其它内容交由外部溢出页来存储
行存储分为四种存储格式,不同的行格式,存储方式、空间性能都不一样
REDUNDANT: 冗余行格式,主要是旧版本 mysql 的兼容,数据和行索引信息分开存储,某些查询操作会快,但是需要额外的空间,所以是之前老版本的格式设计COMPACT: 减少了存储行间,官网说大约 20% ,但是增加了cpu 的负荷。导致一些查询的性能问题DYNAMIC: 动态行格式 该行格式允许长度可变,所以会根据情况来决定是否需要更多空间,5.7 后的默认行格式COMPRESSED: 压缩行格式 对 COMPACT 进行了压缩,减少了存储空间使用,比如text 长文本 会进行压缩,但是检索的时候,必须进行解压,牺牲了cpu
mysql默认的行格式是dynamic
也可以在创建表的时候定义表的行格式
CREATE TABLE t1 (c1 INT) ROW_FORMAT=DYNAMIC;2.Innodb内存加载及管理
我们已经知道,我们的数据最终是会落盘到磁盘中的,那么假如我们每次检索都去磁盘获取,明显性能会比较慢。所以Innodb为了性能的优化,采用了内存缓存机制,在内存中缓存相应的数据。这个内存区间叫做BufferPool.
缓冲池是主内存中的一个区域,在innodb访问时缓存表和索引数据。缓冲池允许直接从内存访问频繁使用的数据,从而加快处理速度
SELECT @@innodb_buffer_pool_size; -- 默认134217728字节/1024/1024 128M也可以设置bufferpool的大小
mysql> SET GLOBAL innodb_buffer_pool_size=402653184;既然有了这个内存缓冲区,那么这个内存与磁盘数据是怎么交互的呢?
2.1内存与磁盘数据交互机制
该交互机制采用的是页加载机制,这是为什么呢?
1. 如果用行交互,那么假如我查询 200 条数据,那么 200 条数据都不在我们内存的话,需要跟磁盘交互200 次,但是 page 可能只有 1.2 个 page 页2. 也不会用 extent 区来交互,因为一个 extent 包含 64 个页。可能我只需要查一条数据,但是会加载64 个页到内存,导致内存浪费。
处于内存的利用率与性能考虑,Innodb选择了page页
那么整体流程是什么样子的呢?
1. 假如一条查询语句 查询出的数据有 2.3.4.5.6.7 6 条数据2. 去 bufferpool 中查看 2.3.4.5.6.7 所在的 page 页是否存在3. 如果存在,直接返回4. 如果不存在,根据 2.3.4.5.6.7 的数据所在的 page 页,去磁盘加载,加载完后保存到内存5. 下次查询 id=5, 由于在内存中已经存在,直接返回
另外,mysql还提供了一种预读机制,我们每次读取数据的时候,会将对应的page页加载到内存,预读机制就是,我就算没读到,也能提前把一些可能读到的数据加载到内存。
预读请求是一种i/o请求,用于在缓冲池中异步预取多个页面,在请求某些页面时,预计即将需要extent的其它页面。那么这个预计的页面是怎么知道的呢?主要通过两种预读算法
线性预读:按照访问顺序的页来执行预加载 某个区里面的页面有多少个页按顺序访问了,那么就会预加载这个区里面所有的页。具体多少个页被顺序访问,具体配置为innodb_read_ahead_threshold
随机预读:根据缓存池中已有的页来预加载,如果在缓冲池中找到了来自同一个区连续的13个页面,InnoDB会异步发出一个请求来预取该区剩余的页面。开关控制:innodb_random_read_ahead
2.2BufferPool内存管理
假如我们查询到的页或者与加载的页都加载到我们的bufferpool,那么肯定要进行管理,因为我们的bufferpool内存也是有限的,不能无休无止的往里面添加。此时,就可以采用淘汰策略。(还记得redis中的淘汰策略吗)
历史总是惊人的相似,Mysql也是采用LRU算法去进行page页淘汰的,只不过实现方式稍有变化。
InnoDB 有预读机制,只是猜测会用,但是不一定真的会用到,那么假如如 果用传统的 LRU 实现,那么我们会发现,会预加载很多页到 bufferpool ,但 是可能用户根本不适用,但是又淘汰不了,既占用了内存,也没有得到很 大的性能提升!
针对Innodb的特殊情况,采用LRU的变种
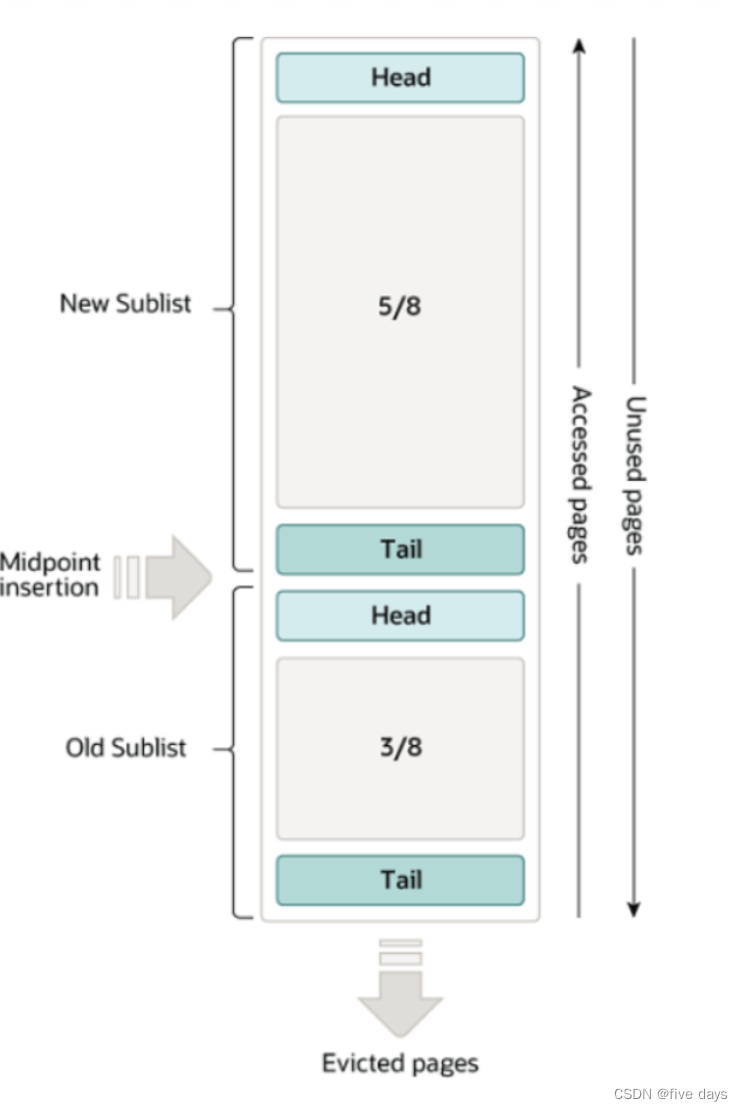
将LRU列表分为2段,链表的前面8分之5是新页列表,后面的8分之3是老页,然后淘汰页面从后面尾部进行淘汰。具体流程如下:
1. 当新的页面缓存到 BufferPool ,先加入到 oldSublist 的头部,包括预读的页。2. 当 old 的页面被访问时 , 会添加到 new 的头部成为一个最近访问的页3.new sublist 的链表会随着新数据的加入向后移动 同样的 old 的链表会随着新数据的加入向后移动;淘汰old sublist 的链尾。
分析: 既然不确定用到,那么就先放到一个中间位置,当用到了后再放到头部避免淘汰。如果加载了但没用到,随着推移,慢慢的进行淘汰掉,从而来提升内存的利用率。
3.数据同步机制
从第2节中我们可以知道我们的数据都会以page页的方式同步到我们的内存,那么在我们的系统中,就有2份数据,一份在内存,一份在磁盘,那么这2个数据是怎么去做数据同步的呢?怎么保证数据的一致性?
为什么不直接同步到磁盘呢?一致性问题不久解决了。假如说每次操作都需要先跟磁盘同步,那么就会出现以下问题:
1. 由于内存跟磁盘交互的最小单位是 page 页,那么你改动一行数据,整个页都需要跟磁盘进行交互同步。2. 这个更改的数据你是不知道在哪个磁盘位置的,属于一个随机 IO 。
上面的这两个问题 都会导致每次操作数据会非常慢。
所以innodb采用的是异步刷盘机制, 何为异步刷盘,就是我优先去更改内存的数据,然后通过异步线程去进行跟磁盘的同步。这个时候,肯定会出现内存跟磁盘不一样的页,这种页就叫做脏页。
出现脏页怎么办?innodb是如何才能够保证数据的一致性呢?
Mysql提供了一个doubleWrite机制,简单点,就是备份。
什么是双写呢?就是当page页刷新到磁盘的时候,把这个page数据写到不同的地方去,当出现问题时,由备份来达到持久性跟数据的一致性。
双写过程:
1. 当脏页被写入到缓存池(也称为内存池)时,它们将被写入到Doublewrite缓冲区中,而不是直接写入到磁盘上的表空间中2. Doublewrite 缓冲区是一个位于内存中的缓冲区,用于存储即将写入磁 盘的脏页的数据。在写入到 Doublewrite 缓冲区后,数据将被写入到两 个不同的磁盘区域,这样即使其中一个磁盘出现问题,数据也可以从另 一个磁盘恢复。在写入到磁盘之前,数据会被缓存到磁盘的 WriteCache 中,确保数据能够快速写入磁盘。3. 在数据被写入磁盘之前, Doublewrite 缓冲区中的每个脏页的 LSN (日志序列号)都会被更新,以确保数据的一致性。这是因为LSN 是一种用于恢复数据的唯一标识符,它可以确保在数据库出现故障时,数据可以恢复到一个一致的状态。4. 一旦数据被成功写入到磁盘上的两个不同区域并且 LSN 已经被更新,数据就被标记为干净页并从缓存池中移除。此时,这个脏页的数据已经被持久化到磁盘中,并且数据库可以确保数据的一致性和可靠性。
分析:DoubleWrite机制会占用一部分内存和磁盘的空间,同时也会导致一定的性能损失,但这是为了保证数据的安全性和可靠性而进行的权衡。
3.1 change-buffer
现在我们知道了,我们更改的数据都是异步同步到磁盘的,但是在更改之前呢,我们内存中不存在的数据,是不是还得从磁盘拿取,那可不可以再优化一下,我先改了放到内存,然后下次读取到相关数据再进行合并呢。
innodb中也有这样的优化,叫做change-buffer(更改缓冲区)
更改缓冲区是一种特殊的数据结构, 当这些页面不在缓冲池中时,它会缓存对二级索引 页面的更改, 稍后会在其他读取操作将页面加载到缓冲池中时合并。为啥是二级索引,因为二级索引的插入跟修改一般是无序的,所以 IO 开销更大,更需要提升性能。还有主键索引。唯一的,所以我们要去磁盘进行唯一校验,本来就需要去磁盘进行IO ,如果内存没有数据的话。
4.RedoLog
我们已经知道了innodb中的数据是异步刷新到磁盘的,那么假如,在刷新到磁盘之前就宕机了。那么数据是不是就丢失了,innodb怎么数据的一致性与持久性呢?
innodb引入了一个redolog。也叫做重做日志,当发生异常的时候,导致数据丢失的时候,从redolog日志中找到想要的数据。
因为 InnoDB 的数据操作是只会实时去操作我们的 bufferpool 的 page 页的,然后通过其他的一些异步方式将bufferpool 中的数据同步到磁盘,所以,数据丢失是很容易产生的。那么就需要我们的RedoLog 来保证数据的不丢失。它属于InnoDB 存储引擎层面实现
4.1 RedoLog格式
当操作数据时,就会记录一条redolog日志,这个日志只是一条记录,记录的是在什么表空间,什么页对数据惊醒了什么样的更改。

type: 操作类型 插入、修改还是删除'spaceId: 表空间 IDpage num : 锁在的页data: 修改的前后数据
这种记录在某个偏移量发生了什么变更的这种日志格式,也叫做物理日志。
4.2 redolog的存储与写入
innodb通过rdolog解决数据丢失的问题。所以redolog肯定是一个基于磁盘的数据结构,肯定会写入磁盘,每次sql语句提交的时候,都会去写入redolog
首先,要保证数据不丢失,那么肯定是要落到磁盘的。那么肯定会有redolog的磁盘文件。
思考: 既然都要写入磁盘,为什么不直接将数据同步到表空间的磁盘呢?
1. 因为 bufferPool 跟磁盘交互的最小单位是 page ,所以,只要 page 里面改 动一条数据,整个page 都会进行跟磁盘同步,导致不必要的同步。 RedoLog只会同步某些记录。2. 你改动的数据是随机的,不是顺序的,随机 IO 的性能比较慢,但是RedoLog是一直往上加,是顺序 IO ,速度比数据 page 同步要快。
另外,redolog为了保证数据的一致性跟持久性的同时,性能得到保证,减少磁盘IO,于是作者又开辟了一个logBuffer的内存区间,缓存redolog,redolog不马上写到磁盘,而是先写到logbuffer,然后一次性的从logbuffer同步到磁盘。
4.3 logbuffer 跟磁盘的同步
只要触发了刷新到磁盘,就能百分比保证数据不丢失吗?如果不丢失,性能是不是又会有所损耗
所以作者提供了不同的方案供选择:
SELECT @@innodb_flush_log_at_trx_commit; //RedoLog同步方案默认设置为11 : 每次事务提交时,将日志刷新到磁盘,安全性高,能够保证持久性,默认配置0 : 每秒从内存写到操作系统,并且刷新( fsync() )到硬盘,可能会导致数据丢失2 :每次写入 logbuffer 并且写到操作系统,但是每秒 fsync() 到磁盘,最终刷新交给操作系统操作,只要操作系统不挂,也能保证持久性,但是操作系统挂了,数据没刷新就会数据丢失

当然,除了配置 innodb_flush_log_at_trx_commit的 同步机制外,还有以下情况也会导致redolog同步到磁盘
a.buffer空间不足时
b. 后台异步线程定期刷新
c.正常关闭服务器
d.checkPoint检查哪些数据没有同步到磁盘的时候
4.4 redolog的开启与禁用
SHOW GLOBAL STATUS LIKE 'Innodb_redo_log_enabled'; -- 查看RedoLog是否开启
ALTER INSTANCE disable INNODB REDO_LOG -- 禁用RedoLog5.总结
innodb作为一个存储数据的引擎;利用了表空间,分段分区分页的思想对数据进行管控;并且采用了内存缓冲池的机制减少IO,提升数据交互的效率;但是就可能造成两处数据的不一致,形成脏页,innodb就又采用了双写机制,提前做好备份,能够应该故障和灾难时,数据的不一致性问题。但是这解决了更改的性能,更改之前还需要从磁盘中拿,于是innodb又提出了change-buffer(更改缓冲区),改了先放内存,下次用了再同步。当然,这些都是采用了异步刷盘的思想,如果,刷盘之前就宕机了呢?innodb又提出了一个很重要的概念,redolog,每一次变更,都会存储到该磁盘中,相较于存储到表空间的磁盘中,该磁盘是顺序添加的,顺序IO性能肯定比随机IO要好。说白了,innodb就是采用了各种内存缓存机制,来减少与磁盘的IO次数,从而提高性能的。有了缓存,那么就肯定少不了内存管理机制,数据的一致性和持久性。















 4438
4438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









