






在文章开始前先澄清一个概念,需要区分形近的单词"LoRa"(long range),这是一项通信技术。熟悉物联网行业的朋友相对会比较熟悉LoRa这项技术,因为有些设备比如电梯的控制就使用了这个技术进行本地数据和命令的传输。
本文介绍的LoRA(最后两个字母大写),是Low-Rank Adaptation的缩写,Low-Rank来自于对权重矩阵的分解。LoRA技术通过将权重矩阵分解成低秩矩阵的乘积,降低了参数数目,进而达到减少硬件资源、加速微调进程的目的。
众所周知,大模型所涉及的参数都是以10亿起的,往往上百亿千亿级的参数。这些模型进行预训练后的基座模型(Base Model)在具体的应用场景下需要进一步微调。这时面临两种选择:
- 全参数的微调:毫无疑问,这个需要加载所有的参数进行调整训练,费时费力更费钱。
- 部分参数的微调:只针对某些层的权重和参数进行调整训练,能够减少存储空间和加速部署,但存在一些性能和模型质量的损耗。
LoRA在保留基座模型全部参数的同时,拆分出权重矩阵的更新并进行矩阵分解,通过调整训练这个由低秩矩阵乘积表示的更新矩阵来减少存储空间的同时保留了模型的质量和微调速度。
LoRA原理
LoRA的详细论文介绍可以阅读参考资料2(LORA: LOW-RANK ADAPTATION OF LARGE LAN- GUAGE MODELS)。其原理如下图所示:对于一个预训练好的基座模型,保留其原有的权重矩阵W不变,仅微调训练更新部分,且这个更新权重矩阵被分解成A和B两个低秩矩阵。下图中A矩阵初始化为高斯分布矩阵,B矩阵初始化为0矩阵。

数学表达:
,
其中的,
,同时r << d。
这里的好处显而易见,假设d=10000, r = 8,在使用LoRA前需要对10000 * 10000共计1亿个参数进行计算更新,而LoRA仅需要10000*8 + 8*10000共计16万个参数的更新计算。论文中使用的模型是“GPT-3 175B”,这个差距读者可以自行计算。
具体微调时会引入两个超参数:和
,它俩的比
对
进行缩放,类似学习率(learning rate)超参数来控制
的更新步长。
这里有个疑问,为什么将能进行分解呢?这里就涉及到矩阵秩和列向量的线性相关性之类的数学概念,以及参考资料3中的发现。有兴趣的读者可以自己再深究。
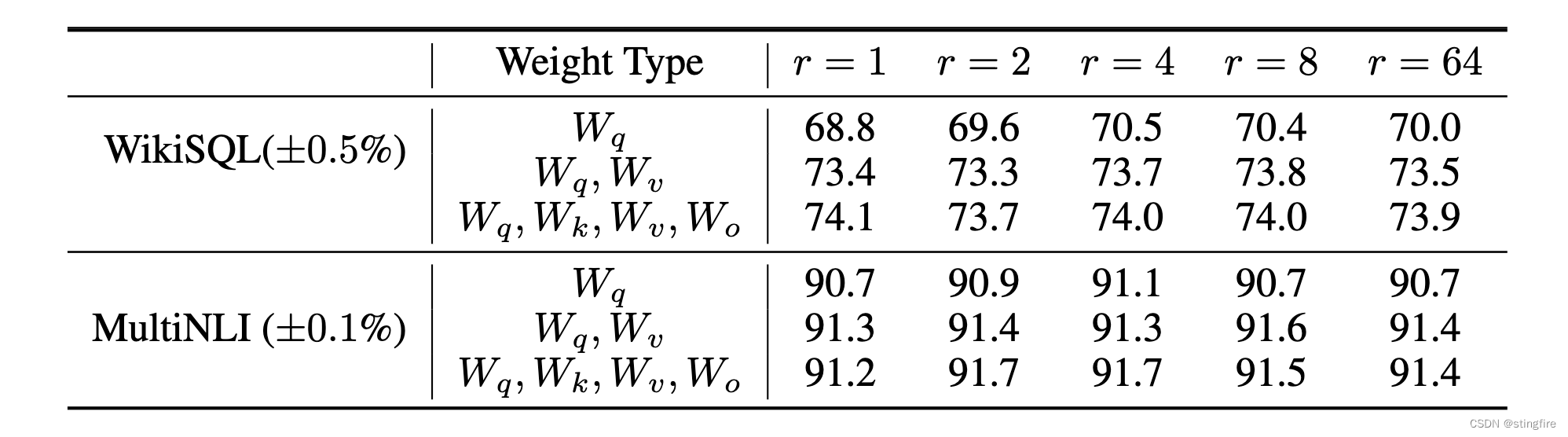
同时,参考资料2作者还发现仅对进行分解更新的效果不够,但对全部4个权重矩阵进行更新并没有大幅提升,对
和
进行分解更新就能取得足够好的效果,一般r取4或者8:
参考资料:
1. YouTube LoRA explained (and a bit about precision and quantization)
2. LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
3. INTRINSIC DIMENSIONALITY EXPLAINS THE EFFEC- TIVENESS OF LANGUAGE MODEL FINE-TUNING
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









