






响应CSDN小助手的要求,关于pipelines的内容部分来了!!
具体的爬虫可以去看作者的另一篇文章Scrapy爬虫基础讲解及案例-CSDN博客
1.1在pipelines.py中定义对数据的操作
-
定义一个管道
-
重写管道类的process_item方法
-
process_item方法处理完item之后必须返回给引擎
class MyspiderPipeline:
def process_item(self, item, spider):
print('itcast',item)
#默认使用完管道之后需要将数据返回给引擎
return item1.2配置并启用管道
✔未启用管道之前运行爬虫文件
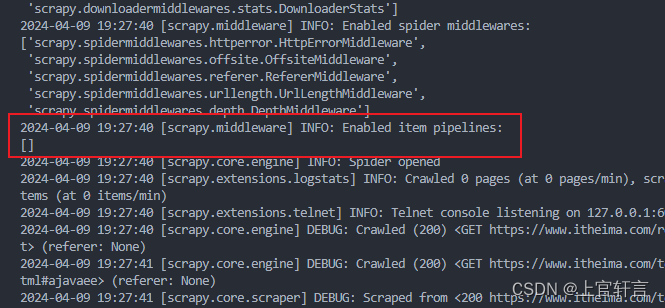
✔启用爬虫文件
ITEM_PIPELINES = {
"myspider.pipelines.MyspiderPipeline": 300, #目录.文件.定义的管道类
"myspider.pipelines.MyspiderPipeline1": 299, #数值越小优先执行
}-
Enabled item pipelines:激活的管道
可以有多个管道
✔启用管道之后运行爬虫文件(这里日志太多,vscode终端长度不够,使用windows自带的终端--命令提示符或者powershell)

✔查看打印
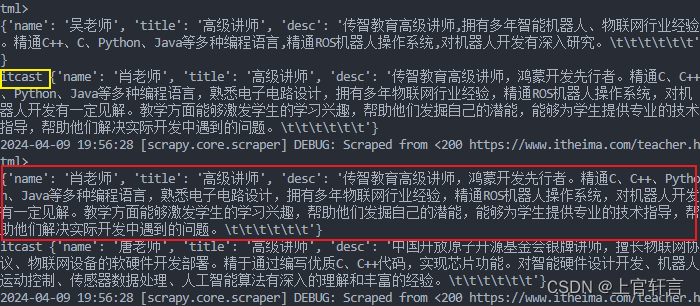
-
红框:原先日志自动打印的
-
黄框:管道自己设置打印的
1.3往文件中输出
from itemadapter import ItemAdapter
import json
class MyspiderPipeline:
def __init__(self):
self.file = open('itcast.json','w') #打开(创建)itcast.json并写入
def process_item(self, item, spider):
# print('itcast',item)
#将字典数据序列化
json_data = json.dumps(item,ensure_ascii=False) + ',\n' #修改json字符串编码
#将数据写入文件
self.file.write(json_data)
#默认使用完管道之后需要将数据返回给引擎
return item
def __del__(self):
self.file.close()
✔运行结果
-
这是没有修改ensure_ascii时管道以自动的Unicode转义序列输出的itcast.json文件

-
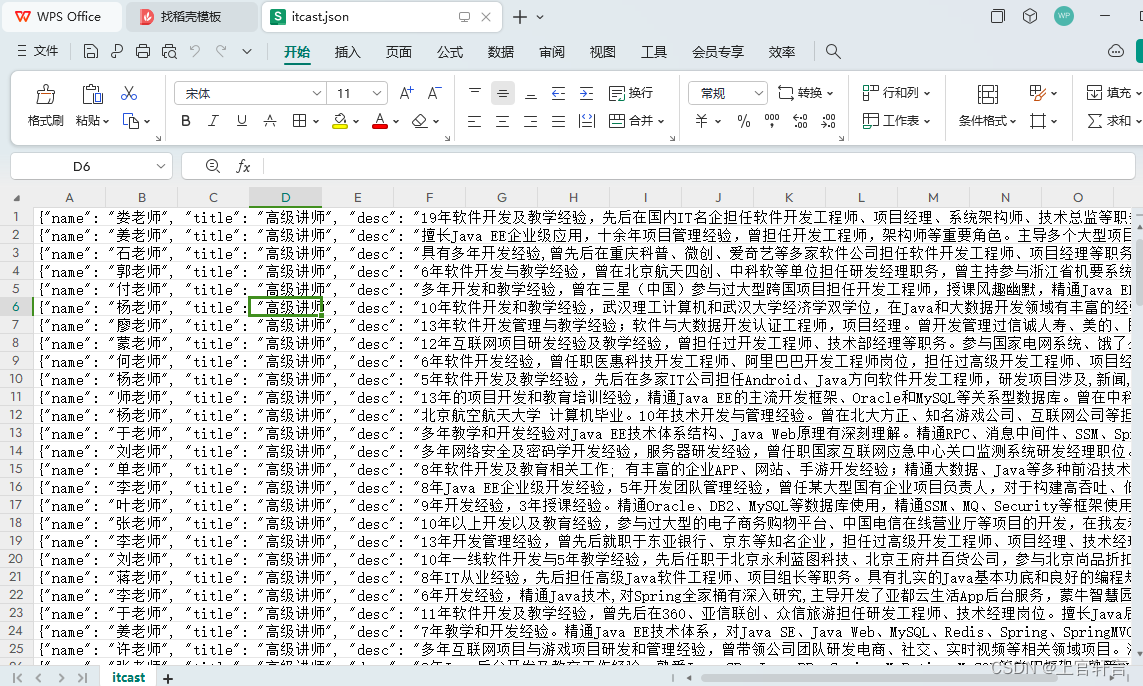
这是关闭ensure_ascii后管道打印出的itcast.json文件
(这里由于vscode字符编码的一些插件或者windows系统版本的问题会有乱码的问题)
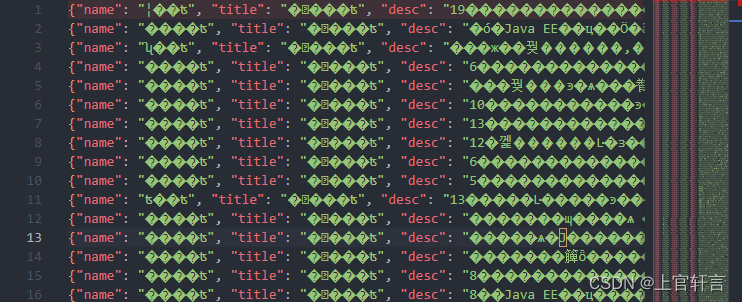
(但是在WPS中打开就没有任何报错)q(≧▽≦q)
配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管通类配置项中值为管道的使用顺序,设置的数值约小越优先执行,该值一般设置为1000以内。
到这里其实作者只是讲解了部分有关pipelines文件的说明,还有更多补充期待作者的下一篇文章















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









