









为什么想到要给大家介绍这个插件呢?因为这个插件在某些场景下,非常好使,不仅能节省成本,还能降低系统复杂度。零成本助力你完成某些随机场景验证。
CSV Data Set Config
在介绍它之前,我们先来回顾下 CSV Data Set Config的能力


bzm - Random CSV Data Set Config
再来看看我们的新工具:bzm - Random CSV Data Set Config
At the beginning of the test, the config reads file. There are a delay and a large memory consumption for large files.
在测试开始时,配置会读取文件。对于大文件,会有延迟和较大的内存消耗。
In preview area shows only 20 records from CSV file.
在预览区域中,仅显示CSV文件中的20条记录。
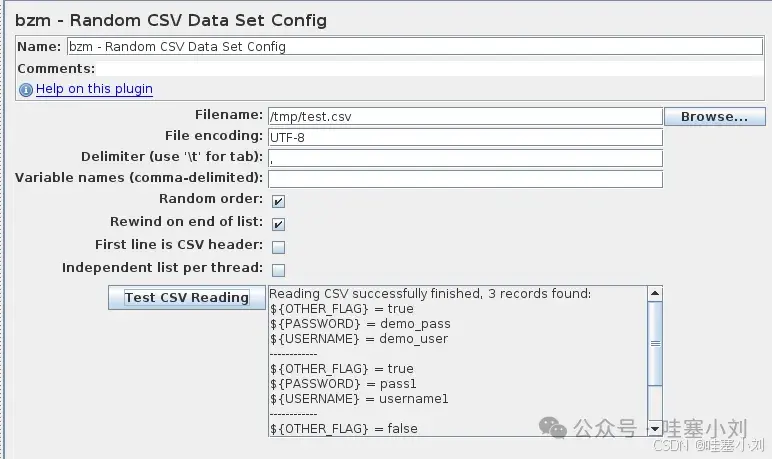
Random CSV Data Set Config is used to read CSV rows from file, split and put them into JMeter variables in random order.
随机CSV数据集配置用于从文件中读取CSV行,按随机顺序拆分并将它们放入JMeter变量中。
This plugin has following options that affect the behavior:
此插件具有以下影响行为的选项:
-
Filename- path to CSV file. Relative path are resolved with respect to the path of the active test plan. For distributed testing, the CSV file must be stored on the server host system in the correct relative directory to where the JMeter server is started.;
文件名 - CSV文件的路径。可给绝对路径,也可给相对路径 -
File encoding- encoding of this CSV file;
文件编码 - CSV文件的编码; -
Delimiter- delimiter that be used to split records in the file;
分隔符 - 文件中用于拆分记录的分隔符; -
Variable Names- list (comma-separated) of variable names;
变量名 - 变量名的列表(逗号分隔); -
Random order- The plugin will get records from the file in random order. This is the part that provides this element’s added value. If you don’t select this option, the element will work like the regular CSV Data Set Config.;
随机顺序 - 插件将按随机顺序从文件中获取记录。这是该元素提供附加价值的部分。如果不选择此选项,则元素将像常规CSV数据集配置一样工作; -
Rewind on end of list- if the flag is selected and an iteration loop has reached the end, the new loop will be started;
列表末尾回绕 - 如果选中此标志,并且迭代循环已达到末尾,则将开始新的循环; -
First line is CSV header- select this flag to skip header(used only ifVariable Namesis not empty);
第一行是CSV标题 - 选择此标志以跳过标题(仅当变量名不为空时使用); -
Independent list per thread- When this is checked with “Random order”, each thread runs its own copy of CSV values with random order. When unchecked, all of threads go over the same randomized list of values.
每个线程独立列表 - 当与“随机顺序”一起选中时,每个线程都会运行其自己的CSV值副本,且顺序为随机。如果未选中,则所有线程都会遍历相同的随机值列表。
适用场景
1、接口测试
2、单接口性能验证
3、分布式压测,K8S容器中为了节省成本,一般会统一挂一个 NAS盘,让多台施压机共享数据,但是这样带来的后果是多个施压机发出的请求参数及顺序是一致的,为了保证参数的随机性,一种办法是做参数文件拆分,每台施压机跑自己拿一份参数,这种开发成本高;另外可利用这里的随机顺序达到多台施压机发送请求时,参数随机;
4、涉及多环境部署的,比如本地化项目,可用这个来巡检,检验服务的稳定性
若大家日常工作中还有遇到其他场景,欢迎分享,一起添砖加瓦,共完善。

















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









