









转载自:http://blog.csdn.net/PeaceInMind/article/details/50003319
导语
在上一章节中我们介绍了怎么在一幅图片中提取潜在的字符(character proposals)。一般情况下基本上都会发生两种不想要的情况。第一种就是有些字符没提取出来,称之为false negative,这个可以通过多通道(如梯度幅值或者其他颜色通道)提取MSER来减轻。另外一种是提取出来的字符有很多不是真的字符,称之为false positive,这个需要一些过滤算法来过滤.这一节主要关注第二点,怎么去过滤false positive,这其中主要会介绍文献[2]RST的MSER Tree过滤,文献[3]的EST特征分类过滤和CNN过滤,CNN在论文中用的不多,不过个人做了一点实验,顺便也对比下,其中疏漏与错误,也请批评与指正。
1 MSER Tree过滤
MSER tree过滤的核心思想是字不能包含字。MSER就是一个个的字符,“包含”代表的就是父子关系。因此它的意思就是如果一个MSER节点是字,那么它的子节点、孙节点、曾孙节点里面都不会是字,同理它的父节点,祖父节点也都不会字。那么我们就可以过滤掉很多不是字的MSER。那我们怎么去判断一个MSER到底是不是字呢,在这里,论文并没有用特征分类器的方法,而是用了一个取巧的方法。我们不需要去判断一个MSER到底是不是字,只要判断一棵树里面哪些最像字。而像不像用的是MSER长宽比(aspect ratio)矫正后的variation进行评价,参见下面的公式,矫正后的variation越小,是字的可能性越大,其中的参数如下,论文没有提怎么得到,应该是多次试验得到或者搜索得到。


因此接下来我们就要去分析哪些最像字,去提取"disconnectedMSER"。这里并不是想象中那么非常简单,只要比较父节点和子节点,其实还是比叫孙节点,曾孙节点,祖父节点,曾祖父节点点。另外一颗树中也不一定只有一个字,也有多个"disconnectedMSER"的可能,比如在一个父节点下有多个子节点,而父节点的variation较大,我们就选了下面的几个子节点。一个可能的例子是一个大框里面有多个字符。因此这里面会涉及一些算法的问题,主要有两个算法,LinearReduction和Tree Accumulation,两者顺序执行。
LinearReduction主要是应对子节点只有一个的MSER。如果是当前节点更像MSER,我们就可以把它的子节点去掉,把孙节点直接链接到当前节点,反之类似。如果一个节点有多个子节点,我们就对这几个子节点做Linear Reduction,经过这一步处理后,MSER节点的子节点数目就不会等于1.伪代码如下

个人写的OPENCV代码如下(由于更好的演示,修改了一些Contour的一些成员名)
- CvContour* LinearReduction(CvContour* root)
- {
- switch (root->childNum)
- {
- case 0:
- {
- return root;
- break;
- }
- case 1:
- {
- CvContour* c = LinearReduction((CvContour*)(root->v_next));
- if (c->variation < root->variation)
- {
- return c;
- }
- else
- {
- //link c's children to root
- CvSeq* cc = c->v_next;
- root->v_next = cc;
- while (cc != NULL)
- {
- cc->v_prev = (CvSeq*)root;
- cc = cc->h_next;
- }
- return root;
- }
- break;
- }
- default:
- {
- CvSeq* c = root->v_next;
- vector<CvContour*> children;
- while (c != NULL)
- {
- CvContour* tmp = LinearReduction((CvContour*)c);
- children.push_back(tmp);
- tmp->v_prev = (CvSeq*)root;// reset parents;
- c = c->h_next;
- }
- root->v_next = (CvSeq*)(children[0]);
- for (size_t i = 0; i < children.size() - 1; ++i)//reset prev and next
- {
- children[i]->h_next = (CvSeq*)(children[i + 1]);
- children[i + 1]->h_prev = (CvSeq*)(children[i]);
- }
- return root;
- break;
- }
- }
- }
CvContour* LinearReduction(CvContour* root)
{
switch (root->childNum)
{
case 0:
{
return root;
break;
}
case 1:
{
CvContour* c = LinearReduction((CvContour*)(root->v_next));
if (c->variation < root->variation)
{
return c;
}
else
{
//link c's children to root
CvSeq* cc = c->v_next;
root->v_next = cc;
while (cc != NULL)
{
cc->v_prev = (CvSeq*)root;
cc = cc->h_next;
}
return root;
}
break;
}
default:
{
CvSeq* c = root->v_next;
vector<CvContour*> children;
while (c != NULL)
{
CvContour* tmp = LinearReduction((CvContour*)c);
children.push_back(tmp);
tmp->v_prev = (CvSeq*)root;// reset parents;
c = c->h_next;
}
root->v_next = (CvSeq*)(children[0]);
for (size_t i = 0; i < children.size() - 1; ++i)//reset prev and next
{
children[i]->h_next = (CvSeq*)(children[i + 1]);
children[i + 1]->h_prev = (CvSeq*)(children[i]);
}
return root;
break;
}
}
}
Tree Accumulation是用于子节点大于1的情况下,经过LinearReduction后,节点的子节点数目要么是0。要么就大于1.对于子节点数目大于2的,我们去找到子树里面像字的,然后看子树里有没有比当前节点更像字的节点,如果有,则保存子树中像字的,否则,就保存当前节点。执行完后我们就获得了disconnected MSER,伪代码和c++的代码如下,c++代码为了演示方便,修改了contour的一些成员名。

- vector<CvContour*> RobustSceneText::TreeAccumulation(CvContour* root)
- {
- //need to recalcu childNum due to linear reduction
- vector<CvContour*> vTmp;
- vTmp.push_back(root);
- CalcChildNum(vTmp);
- assert(root->childNum!=1);
- vector<CvContour*> result;
- if ( root->childNum >= 2 )
- {
- CvContour* c = (CvContour*)(root->v_next);
- while ( c != NULL )
- {
- vector<CvContour*> tmp;
- tmp = TreeAccumulation(c);
- result.insert( result.end(), tmp.begin(), tmp.end());
- c = (CvContour*)c->h_next;
- }
- for (size_t i = 0; i < result.size(); ++i)
- {
- if ( std::abs(result[i]->variation) < std::abs( root->variation) )
- {
- return result;
- }
- }
- result.clear();
- result.push_back(root);
- return result;
- }
- else
- {
- result.push_back(root);
- return result;
- }
- }
vector<CvContour*> RobustSceneText::TreeAccumulation(CvContour* root)
{
//need to recalcu childNum due to linear reduction
vector<CvContour*> vTmp;
vTmp.push_back(root);
CalcChildNum(vTmp);
assert(root->childNum!=1);
vector<CvContour*> result;
if ( root->childNum >= 2 )
{
CvContour* c = (CvContour*)(root->v_next);
while ( c != NULL )
{
vector<CvContour*> tmp;
tmp = TreeAccumulation(c);
result.insert( result.end(), tmp.begin(), tmp.end());
c = (CvContour*)c->h_next;
}
for (size_t i = 0; i < result.size(); ++i)
{
if ( std::abs(result[i]->variation) < std::abs( root->variation) )
{
return result;
}
}
result.clear();
result.push_back(root);
return result;
}
else
{
result.push_back(root);
return result;
}
}
下图展示了对比图,MSER是依照文献[3]在HSV里H和V两通道中提取

2 特征分类过滤
特征分类过滤主要是利用人工设计的一些特征,比如说Stroke width, Stroke variance, Aspectratio, hull ratio等等并送到分类器中进行分类,我们就知道哪些是字符,哪些不是字符。但是请注意由于特征设计和分类器的不同,会导致判别的错误。在这里我们主要是介绍stroke相关的知识,主要是文献[1]里的SWT(stroke widthtransform)和文献[3]的stroke supportpixels(SPPs).
Stroke width称之为笔画宽度,最早见于文献[1],并且作者申请了专利,一般算法很难申请专利,所以可见其独到之处。当我们在用中性笔在写字的时候,一撇一划的笔画宽度一般都固定在一定的范围之类,与你笔芯的滚珠有关系,比如下图的'h',它的笔画宽度大约在2左右。

文献[1]中的计算算法比较复杂,本人也实现了c++的版本,但今天介绍一种更简单的近似解法,方便讲解,利用opencv也能很快实现。具体的计算方法如下
(1)第一步首先根据MSER或者连通域等构建出二值图像,比如背景是0,前景是255

(2)接着对所有前景像素计算它与离其最近的0点的距离,这里的参数与文献[3]保持一致,得到distance map
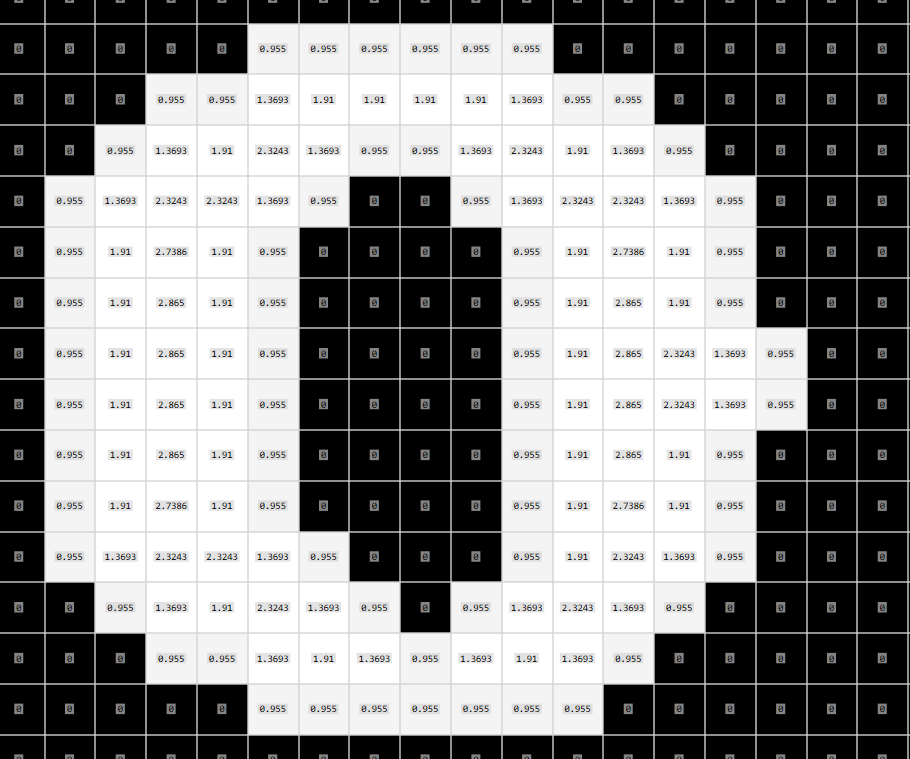
(3)接着提取出字符的骨架,我这里用的是Guo_Huo_Thinner算法,得到skeleton

(4)计算骨架上像素的distance的均值,就得到了我们的stroke width.过滤的时候还可以用strokewidth variance,这幅图上计算出来Stroke均值和方差分别为2.27和0.52
个人觉得stroke的特征还是非常好用的,能区分很多的字与非字。文献[3]stroke均值和方差特征进行了改变,提出了strokesupport pixels(SSPs)和Strke Area ratio. SSPs跟上面的步骤的不同之处是不再找字符的骨架,而是利用第二步中的ditance map图找局部最大点,如下图的红色点(论文中局部是3*3的),我们把这些点称之为SSPs。

SSPs一般都在stroke的中间位置。最后通过这些点去估计整个字符的stroke Area ratio,计算公式如下,Ni是3*3局部区域内SSPs的的个数。当你的笔画很工整时,一般这个值会接近1(一个特殊的情况是当stroke width为1的时候这个值远超1,按照论文的公式strokeAreaRatio在0.88左右。

按照文献[3]训练的分类器的精度不是特高,在85%-90%左右,可能是本人训练的原因或是程序bug.

3 CNN字符过滤
现在的论文用CNN过滤的不太很多。CNN用起来比较简单,不需要手工去设计特征,但是对硬件要求比较高,如果说硬件比较挫,速度可能就跟不上。但是CNN有一个好处是它能根据你的数据集提从更高层面上区分字和非字符。以英文为例,我可以设计出很多不是字,但是按照人工特征很难区分的图形,比如下图

但是CNN会一定程度上会判断这个图像是不是像26个字母中的一个,因此能过滤更多的非字符。个人做了一些实验,如下图,请注意这里采用了了梯度幅值通道,并且首先利用了MSER tree进行过滤。但是这样一来,它不能适用于所有文字。不过个人感觉这种情况现实中不太多。

至此,这一小节就已讲完,错误与疏漏,恳请批评和指正。
上一博客 文字检测与识别1-MSER
下一博客 文字检测与识别3-字符合并
[1]Epshtein B, Ofek E, WexlerY. Detecting text in natural scenes with stroke width transform[C]//ComputerVision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010:2963-2970.
[2]Yin X C, Yin X, Huang K, etal. Robust text detection in natural scene images[J]. Pattern Analysis andMachine Intelligence, IEEE Transactions on, 2014, 36(5): 970-983.
[3]Neumann L, Matas J.Efficient Scene Text Localization and Recognition with Local CharacterRefinement[J]. arXiv preprint arXiv:1504.03522, 2015.
[4]Zhu Y, Yao C, Bai X. Scenetext detection and recognition: Recent advances and future trends[J]. Frontiersof Computer Science, 2015.
[5]Zhang Z, Shen W, Yao C, etal. Symmetry-Based Text Line Detection in Natural Scenes[C]//Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition. 2015: 2558-2567.
[6]Huang W, Qiao Y,Tang X. Robust scene text detection with convolution neural network inducedmser trees[M]//Computer Vision–ECCV 2014.Springer International Publishing, 2014: 497-511.
[7]Sun L, Huo Q, Jia W, et al.Robust Text Detection in Natural Scene Images by Generalized Color-EnhancedContrasting Extremal Region and Neural Networks[C]//Pattern Recognition (ICPR),2014 22nd International Conference on. IEEE, 2014: 2715-2720.
[8]Jaderberg M, Simonyan K,Vedaldi A, et al. Reading text in the wild with convolutional neuralnetworks[J]. International Journal of Computer Vision, 2014: 1-20.
[9]Jaderberg M,Vedaldi A, Zisserman A. Deep features for text spotting[M]//Computer Vision–ECCV 2014. Springer International Publishing, 2014: 512-528.
[10]Gomez L, Karatzas D. A fasthierarchical method for multi-script and arbitrary oriented scene textextraction[J]. arXiv preprint arXiv:1407.7504, 2014.
[11]Coates A, Carpenter B, CaseC, et al. Text detection and character recognition in scene images withunsupervised feature learning[C]//Document Analysis and Recognition (ICDAR),2011 International Conference on. IEEE, 2011: 440-445.
[12]Neumann L, Matas J.Real-time scene text localization and recognition[C]//Computer Vision andPattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 3538-3545.
[13]Shi B, Yao C, Zhang C, etal. Automatic Script Identification in the Wild[J]. arXiv preprintarXiv:1505.02982, 2015.
[14]Wang T, Wu D J, Coates A,et al. End-to-end text recognition with convolutional neuralnetworks[C]//Pattern Recognition (ICPR), 2012 21st International Conference on.IEEE, 2012: 3304-3308.














 8551
8551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









