









Image Based Virtual Try-on Network from Unpaired Data
Image-Based-Virtual-Try-on-Network-from-Unpaired-Data

摘要
本文提出了一种新的基于图像的虚拟试穿方法(Outfit-VITON),该方法可帮助可视化从各种参考图像中选择的衣物组成如何在查询图像中的人身上形成凝聚力的衣服。我们的算法具有两个独特的属性。首先,它不昂贵,因为它只需要一大套穿着各种服装的人的(独立的)(真实的和分类的)图像(没有真实的3D信息)。训练阶段只需要单个图像,而无需手动创建图像对,其中一个图像显示穿着特定服装的人,另一个图像仅显示相同类别的服装。其次,它可以合成构成一个连贯服装的多件服装的图像。 它可以控制最终服装中所呈现服装的类型。经过训练后,我们的方法便可以从穿着衣服的人体模型的多个图像中合成出具有凝聚力的服装,同时使服装适合查询人员的身体形状和姿势。在线优化步骤负责处理精细的细节,例如复杂的纹理和徽标。 与现有的最新方法相比,对包含较大形状和样式变化的图像数据集进行定量和定性评估显示出更高的准确性,尤其是在处理高度详细的服装时。
介绍
在美国,在线服装销售在服装和配饰销售总额中所占的份额以比其他任何电子商务部门更快的速度增长。在线服装购物可让您在家中舒适自在地购物,提供多种选择的商品以及使用最新产品,从而为购物提供了便利。但是,在线购物无法进行物理试穿,从而限制了客户对服装实际外观的理解。这一关键局限性促进了虚拟试衣间的发展,在虚拟试衣间中,将综合生成穿着所选服装的顾客的图像,以帮助比较和选择最理想的外观。
3D方法
用于合成穿着者的逼真的图像的常规方法依赖于从深度相机或多个2D图像构建的详细3D模型。3D模型可以在几何和物理约束下实现逼真的服装模拟,并可以精确控制观看方向,照明,姿势和纹理。然而,它们在数据捕获、注释、计算以及在某些情况下对专用设备(如3D传感器)的需要方面产生了巨大的成本。这些巨大的成本阻碍了向数百万客户和成衣的扩展。
条件图像生成方法
最近,更经济的解决方案建议将虚拟试戴问题公式化为有条件的图像生成问题。这些方法从两个输入图像中生成人们穿着所选服装的逼真的图像:一个显示人物,另一个被称为店内服装,仅显示服装。根据使用的训练数据,这些方法可以分为两个主要类别:(1)配对数据,单服装方法,该方法使用一组训练成对的图像对来描述多幅图像中的同一件衣服。例如,有和没有人穿衣服的图像对(例如[10、30]),或以相同的人体模型在两个不同姿势下呈现特定服装的图像对。(2)将训练数据中的整个服装(由多件服装组成)视为一个实体的单数据,多服装方法(例如[25])。两种方法都有两个主要局限性:首先,它们不允许客户选择多种服装(例如衬衫,裙子,夹克和帽子),然后将它们组合在一起以适合客户的身体。其次,他们接受了几乎难以大规模收集的数据培训。在成对数据,单件服装图像的情况下,很难为每种可能的服装收集几对。对于单数据,多服装图像,很难收集到足以覆盖所有可能服装组合的实例。
新奇
在本文中,我们提出了一种新的基于图像的虚拟试戴法,该方法是:1)提供廉价的数据收集和训练过程,其中包括仅使用单个2D训练图像,该图像比成对的训练图像或3D数据更容易进行大规模收集 。2)通过合成构成一个整体的服装的多件服装的图像,提供高级的虚拟试穿体验(图2),并使用户能够控制最终服装中渲染的服装的类型。3)引入了用于虚拟试穿的在线优化功能,该功能可以准确地综合精细的服装功能,例如纹理,徽标和刺绣。我们对包含较大形状和样式变化的图像集评估提出的方法。 定量和定性结果均表明我们的方法比以前的方法取得了更好的结果。

相关工作
生成对抗网络
生成对抗网络(GAN)[7,27]是生成模型,经过训练可以合成与原始训练数据没有区别的真实样本。GAN在图像生成[24,17]和操纵[16]中已显示出令人鼓舞的结果。但是,最初的GAN公式缺乏控制输出的有效机制。
有条件的GAN(cGAN)[21]试图通过在生成的示例上添加约束来解决此问题。GAN中使用的约束可以采用类别标签[1],文本[36],姿势[19]和属性[29]的形式(例如,张开/闭合,胡须/无胡须,眼镜/无眼镜,性别)。Isola等 [13]提出了一种称为pix2pix的图像到图像转换网络,该网络将图像从一个域映射到另一个域(例如,草图到照片,分割到照片)。这种跨域关系已在图像生成中显示出令人鼓舞的结果。Wang等人的pix2pixHD [31]从单个分割图生成多个高清输出。它通过添加自动编码器来实现,该编码器学习可限制GAN并支持更高级别的本地控制的特征图。最近,[23]建议使用空间自适应的归一化层,该层在图像级别而不是局部地对纹理进行编码。另外,已经使用GAN证明了图像的组成[18,35],其中使用几何变换将前景图像的内容传输到背景图像,从而生成具有自然外观的图像。最近已经证明在测试阶段可以对GAN进行微调[34],用于面部重现。
虚拟试穿
深度神经网络的最新进展激发了仅使用2D图像而不使用任何3D信息的方法。例如,VITON [10]方法使用形状上下文[2]来确定如何通过构图阶段然后进行几何变形来使服装图像变形以适合查询人的几何形状。CP-VITON [30]使用卷积几何匹配器[26]确定几何变形函数。WUTON [14]是这项工作的扩展,它使用对抗性损失进行更自然,更详细的合成,而无需合成阶段。PIVTONS [4]扩展了[10]用于姿势不变的服装,而MG-VTON [5]扩展了用于多姿势虚拟试穿。原始VITON [10]的所有不同变体都需要一组成对的训练图像,即在有或没有人体模型的情况下都可以捕获每件服装。因为获得这样的配对图像非常费力,所以这限制了可以收集训练数据的规模。同样,在测试过程中,只能将服装的目录(店内)图像传输到用户的查询图像中。在[32]中,GAN用于将参考服装变形到查询人的图像上。不需要目录服装图像,但是仍然需要在多个姿势下穿着相同服装的同一个人的相应对。上述工作仅涉及上身服装的转换(除[4]外,仅适用于鞋子)。Sangwoo等人[22]应用分段蒙版,以控制生成的形状,例如将裤子转换为裙子。然而,在这种情况下,仅控制平移衣服的形状。此外,每个形状转换任务都需要其自己的专用网络。[33]的最新工作生成了穿着多件衣服的人的图像。但是,生成的人体模型仅由姿势控制,而不是由身体形状或外观控制。另外,该算法需要一套完整的成对图像的训练集,这尤其难以大规模获得。[25](SwapNet)的工作使用GAN在两个查询图像之间交换整个服装。它有两个主要阶段。 最初,它会生成查询人对参考服装的翘曲分割,然后覆盖服装纹理。此方法使用自我监督来学习形状和纹理转移,并且不需要成对的训练集。但是,它在装配级别而不是服装级别运行,因此缺乏可组合性。[9,12]的最新著作还通过形状和纹理生成的两个阶段来生成时尚图像。
装备虚拟试穿(O-VITON)
我们的系统使用形状和样式各异的穿着衣服的人的多个参考图像。用户可以在这些参考图像中选择服装,以接收算法生成的服装输出,该输出显示了穿着这些选定服装的个人图像(查询)的真实图像。
pix2pixHD方法[31]成功地完成了图像到图像的翻译任务,启发了我们解决这一难题的方法。类似于此方法,我们的生成器G以语义分割图和编码器E生成的外观图为条件。自动编码器为分割图中的每个语义区域分配一个代表区域外观的低维特征向量。这些基于外观的功能使您可以控制输出图像的外观,并解决不使用不使用它们的条件GAN经常出现的多样性不足的问题。
我们的虚拟试穿合成过程(图2)包括三个主要步骤:(1)生成分割图,该图始终将所选参考服装的轮廓(形状)与查询图像的分割图结合在一起。(2)生成在查询图像中显示该人穿着从参考图像中选择的服装的人的真实感图像。(3)在线优化以优化最终输出图像的外观。
我们将更详细地描述我们的系统:第3.1节描述了前馈综合管道及其输入,组件和输出。第3.2节描述了形状和外观网络的训练过程,第3.3节描述了用于微调输出图像的在线优化。
前馈生成
系统输入
我们系统的输入包括一个H×W RGB查询图像 x 0 x^0 x0,该图像有一个希望试穿各种服装的人。这些服装由一组M个附加参考RGB图像 ( x 1 , x 2 , . . . , x M ) (x^1,x^2,...,x^M) (x1,x2,...,xM)表示,其中包含分辨率与查询图像 x 0 x^0 x0相同的各种服装。请注意,这些图像可以是穿着不同衣服的人的自然图像,也可以是显示单个衣物的目录图像。另外,参考服装M的数量可以变化。为了获得时尚图像的分割图,我们训练了一个PSP [37]语义分割网络S,该网络输出大小为H×W×Dc的 s m = S ( x m ) s^m = S(x^m) sm=S(xm),其中 x m x^m xmxm中的每个像素都使用一热编码标记为Dc类之一。换句话说,s(i,j,c)= 1表示像素(i,j)被标记为c类。类别可以是身体部位,例如面部/右臂,也可以是服装类型,例如上衣,裤子,夹克或背景。我们使用分割网络S来计算查询图像的分割图 s 0 s^0 s0和参考图像(1≤m≤M,)的 s m s^m sm个分割图。类似地,捕获人的姿势和身体形状的DensePose网络[8]用于估计大小为H×W×Db的身体模型 b = B ( x 0 ) b = B(x^0) b=B(x0)。
形状生成网络组件
形状生成网络负责上述第一步:它将查询图像 x 0 x^0 x0中人的身体模型b与 { s m } m = 1 M \{s^m\}^M_{m = 1} {sm}m=1M表示的所选服装的形状结合起来(图2绿色 盒子)。如第3.1.1节所述,语义分割图 s m s^m sm为 x m x^m xm中的每个像素分配一个热矢量表示。因此,通过深度尺寸 s m ( ⋅ , ⋅ , c ) s^m(·,·,c) sm(⋅,⋅,c)的 s m s^m sm的W×H×1切片提供了二进制掩码 M m , c M_{m,c} Mm,c,它表示映射到图像 x m x^m xm中的c类的像素区域。形状自动编码器 E s h a p e E_{shape} Eshape和随后的局部合并步骤将此蒙版映射到8×4×Ds尺寸的形状特征切片 e m , c s = E s h a p e ( M m , c ) e^s_{m,c }= E_{shape}(M_{m,c}) em,cs=Eshape(Mm,c)。即使图像m中不存在类型c的服装,Dc可能的分割类别的每个类别c仍由 e m , c s e^s_{m,c} em,cs表示。即,它将在 E s h a p e E_{shape} Eshape中输入零值蒙版 M m , c M_{m,c} Mm,c。
当用户希望使用参考图像m中类型为c的衣服为查询图像中的人穿衣服时,我们只需将 e 0 , c s e^s_{0,c} e0,cs替换为 e m , c s e^s_{m,c} em,cs的相应形状特征切片即可,而无需考虑衣服c是否存在于 查询图像与否。我们通过沿深度维度进行级联来合并所有服装类型的形状特征切片,从而生成8×4×DsDc尺寸的粗略形状特征图 e ˉ s \bar e ^ s eˉs。我们将 e s e^s es表示为 e ˉ s \bar e ^ s eˉs的升级版本,并将其扩展为H×W×DsDc维度。本质上,仅通过将参考图像的相应形状特征切片替换为参考图像的形状特征切片即可完成将不同服装类型组合为查询图像的操作。
形状特征图 e s e^s es和人体模型b被输入到形状生成器网络 G s h a p e G_{shape} Gshape中,以生成穿着所选参考服装 s y = G s h a p e ( b , e s ) s^y = G_{shape}(b,e^s) sy=Gshape(b,es)的查询人的新的变换后的分割图 e y e^y ey。
外观生成网络组件
我们的外观生成网络中的第一个模块(图2蓝色框)受到[31]的启发,并获取RGB图像及其相应的分割图 ( x m , s m ) (x^m,s^m) (xm,sm),并应用外观自动编码器 E a p p ( x m , s m ) E_{app}(x^m,s^m) Eapp(xm,sm)。外观自动编码器的输出表示为H×W×Dt尺寸的 e ˉ m t \bar e^t_m eˉmt。通过根据掩码 M m , c M_{m,c} Mm,c进行区域平均池化,我们形成了描述该区域外观的Dt维向量e^t_{m,c}。最后,通过将外观特征向量 e m t e^t_m emt,c向其对应的由掩模 M m , c M_{m,c} Mm,c标记的区域进行区域广播来获得外观特征图 e m t e^t_m emt。当用户从图像 x m x^m xm中选择类型为c的服装时,仅需要在产生外观特征 e t e^t et的区域广播之前,用服装图像 e m , c t e^t_{m,c} em,ct的外观矢量替换查询图像 e 0 , c t e^t_{0,c} e0,ct中的外观矢量即可。
外观生成器Gapp将前一形状生成阶段生成的分割图 s y s^y sy作为输入,并将外观特征图 e t e^t et作为条件,并生成表示前馈虚拟试戴输出 y = G a p p ( s y , e t ) y = Gapp(s^y,e^t ) y=Gapp(sy,et)。
训练阶段
形状和外观代网络采用单输入图像的训练集相同的人在不同的姿势和服装培训的独立(图3)。在每种训练方案中,发生器,鉴别器和自动编码器都是联合训练的。

外观训练阶段
对于图像到图像的翻译任务,我们使用类似于[31]的条件GAN(cGAN)方法。在cGAN框架中,训练过程旨在优化Minimax损失[7],该损失代表了生成器G和鉴别器D竞争的游戏。给定训练图像x,生成器将接收到相应的分割图S(x)和外观特征图
e
t
(
x
)
=
E
a
p
p
(
x
,
S
(
x
)
)
e^t(x)= E_{app}(x,S(x))
et(x)=Eapp(x,S(x))作为条件。注意,在训练阶段,从相同的输入图像x提取分割和外观特征图,而在测试阶段,从多个图像计算分割和外观特征图。我们将在第3.1节中描述此步骤。 生成器旨在合成
G
a
p
p
(
S
(
x
)
,
e
t
(
x
)
)
G_{app}(S(x),e^t(x))
Gapp(S(x),et(x)),当尝试将生成的输出与原始输入(例如x)分离时,这会混淆鉴别器。鉴别器也由分割图S(x)的条件。如[31]中所述,生成器和鉴别器旨在最小化LSGAN损耗[20]。为简便起见,我们将在以下方程式中从外观网络组件中省略应用程序下标。
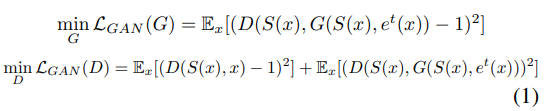
生成器Gapp的体系结构类似于[15,31]使用的体系结构,由卷积层,残差块和转置的卷积层组成,用于上采样。鉴别器Dapp的体系结构是PatchGAN [13]网络,如[31]中所述,该网络已应用于多个图像比例。鉴别器的多层结构使其既可以在粗略的范围内以较大的接收场工作,从而获得更全面的视野,又可以在细微的范围内进行操作,以测量细微的细节。E的体系结构是标准的卷积自动编码器网络。
除了对抗性损失外,[31]还提出了一种额外的特征匹配损失,以稳定训练并迫使其遵循多个尺度上的自然图像统计数据。在我们的实现中,我们添加了特征匹配损失,如[15]所述,该特征匹配损失可直接比较使用预训练的感知网络(VGG-19)计算的生成的图像激活和真实的图像激活。设
ϕ
l
\phi _l
ϕl为跨通道的层激活的矢量形式,尺寸为
C
l
×
H
1
⋅
W
l
C_l×H_1·W_l
Cl×H1⋅Wl。 我们使用超参数
λ
l
λ_l
λl来确定层l对损耗的贡献。 此损失定义为:
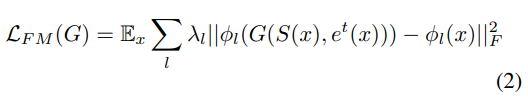
我们将这些损失合并在一起,以获得外观生成网络的损失函数:
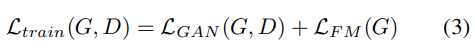
形状训练阶段
用于训练形状生成网络的数据与用于外观生成网络的训练数据相同,我们对该网络也使用类似的条件GAN损失。类似于解耦从形状的外观,在3.2.1所描述的,我们希望在测试阶段从参考图像与查询图像解耦从衣服的轮廓的身体形状和姿势以传递服装。我们通过使用随机仿射变换为s = S(x)的每个切片s(·,·,c)应用不同的空间扰动来鼓励这种情况。这是受到SwapNet [25]中描述的自我监督的启发。另外,我们对Eshape的输出应用平均池,以将H×W×Ds尺寸映射到8×4×Ds尺寸。这是针对测试阶段完成的,该阶段需要对姿势和身体形状均不变的形状编码。Gshape和鉴别器Dshape的损失函数与(3)类似,生成器以输入图像的形状特征 e s ( x ) e^s(x) es(x)而不是外观特征映射 e t e^t et为条件。鉴别器旨在将s = S(x)与 s y = G s h a p e ( S ( x ) , e s ) s y = G_{shape}(S(x),e^s) sy=Gshape(S(x),es)分开。将(2)中的特征匹配损失替换为交叉熵损失 L C E L_{CE} LCE组件,该组件比较语义分割图的标签。
在线优化
外观网络(自动编码器和生成器)的前馈操作有两个主要限制。首先,具有不重复图案的较不频繁穿着的服装更具挑战性,这是由于它们的不规则图案和训练集中的减少。图6显示了我们训练集中各种纹理属性的频率。 最常见的图案是实心的(无特征的纹理)。其他常见的纹理(例如徽标,条纹和花卉图案)非常多样化,并且属性分布具有其他不常见的非重复图案相对较长的尾巴。这构成了一项艰巨的学习任务,其中神经网络旨在准确生成训练集中稀缺的模式。第二,无论训练集有多大,它都永远不会足够大以覆盖所有可能的服装样式和形状变化。因此,我们提出了一种受样式转换启发的在线优化方法[6]。该优化在测试阶段微调外观网络,以将服装从参考服装合成为查询图像。最初,我们使用3.1.3中描述的前馈出现网络的参数。然后,我们微调发生器Gapp(为简便起见,用G表示),以通过最大程度地减少参考损耗,从参考图像
x
m
x^m
xm更好地重建服装。正式地,给定参考服装,我们使用由
s
m
s^m
sm给出的其对应区域二进制掩码
M
m
,
c
M_{m,c}
Mm,c来定位参考损耗(3):

因此,我们的在线损失将参考服装损失(4)和查询损失(5)结合在一起:

注意,在线优化阶段分别应用于每件参考服装(另请参见图5)。 由于查询图像中的所有区域均未在空间上对齐,因此我们丢弃了特征匹配损失(2)的相应值。


实验
我们的实验是在从亚马逊商品目录中删除的各种服装和姿势的人(男性和女性)数据集上进行的。数据集被分为训练集和测试集,分别包含45K和7K图像。 将所有图像调整为固定的512×256像素大小。我们进行了一些实验,以合成单个项目(上衣,裤子,裙子,夹克和连衣裙),以及将成对的项目合成在一起(即上衣和裤子)。
实施细节
-
设定值
我们用于自动编码器Eshape,Eapp,生成器Gshape,Gapp和鉴别器Dshape,Dapp的体系结构与[31]中的相应组件相似,但有以下区别。首先,自动编码器输出具有不同的尺寸。 在我们的示例中,对于Eshape,输出尺寸为Ds = 10,对于Eapp,输出尺寸为Dt = 30。对于人体模型,分割图中的类数为Dc = 20和Db = 27维。其次,我们使用单级生成器Gshape,Gapp而不是两个级生成器G1和G2,因为我们使用的是较低的512×256分辨率。我们使用ADAM优化器训练了40个和80个时期的形状和外观网络,批次大小分别为21和7个。其他训练参数为lr = 0.0002,β1= 0.5,β2= 0.999。 在线损耗(第3.3节)也通过ADAM使用lr = 0.001,β1= 0.5,β2= 0.999进行了优化。当两个连续迭代之间的在线损耗差异小于0.5时,优化将终止。 在我们的实验中,我们发现该过程平均在80次迭代后终止。 -
基准线
VITON [10]和CP-VITON [30]是基于图像的最新虚拟试穿方法,可在线实现。我们主要关注与CP-VITON的比较,因为它在[30]中被证明优于原始的VITON。请注意,除了下面报告的评估差异外,CP-VITON(和VITON)方法比我们提出的方法受到更多限制,因为它们仅支持生成在配对数据集上训练的顶部。 -
评估协议
我们采用了以前的虚拟尝试方法(即[30,25,10])中的相同评估协议,该方法同时使用了定量指标和人类主观感知研究。定量指标包括:(1)Frechet初始距离(FID)[´11],用于测量所生成图像与实际图像的Inception-v3激活分布之间的距离。 (2)初始分数(IS)[27],用于测量应用于生成图像的预训练的Inception-v3网络(ImageNet)的输出统计信息。我们还进行了成对的A / B测试人体评估研究(如[30]),其中向人类受试者(工人)显示了250对参考和查询图像及其相应的虚拟试穿结果(两种比较方法) 。具体来说,给定一个人的图像和目标服装的图像,要求工作人员选择更真实的图像,并在两次虚拟试穿结果之间保留目标服装的更多细节。
比较(表1)分为3种变化:(1)合成上衣(2)合成一件衣服(例如上衣,夹克,裤子和衣服)(3)从两个不同的参考图像同时合成两件衣服( 例如上衣和裤子,上衣和夹克)。

定性评估
图4(左)显示了与CP-VITON相比,带有和不带有在线优化步骤的O-VITON方法的定性示例。为了公平起见,我们仅包括上衣,因为CP-VITON仅接受过衬衫转让方面的培训。请注意,在线优化如何更好地保留印刷品,徽标和其他非重复性图案的精细纹理细节。此外,CP-VITON严格遵守原始查询服装的轮廓,而我们的方法对查询人员的原始服装不太敏感,从而生成了更自然的外观。图4(右)显示了有/无在线优化步骤的夹克,连衣裙和裤子的综合结果。两种方法都使用相同的形状生成步骤。我们可以看到,我们的方法成功完成了查询人体模型的封闭区域,例如四肢或新暴露的皮肤。在线优化步骤使模型能够适应训练数据集中未出现的形状和服装纹理。图1显示,即使建议的方法同时合成了两件或三件服装,细节合成的水平仍保持不变。

- 失败案例
图7显示了我们的方法的失败案例,这些失败案例是由不频繁的姿势,具有独特轮廓的服装以及具有复杂非重复纹理的服装引起的,这些事实证明对在线优化步骤更具挑战性。我们会向读者介绍补充材料,以获取更多故障案例的示例。

定量评估
表1列出了我们的O-VITON结果与CP-VITON的结果比较,以及我们单独使用前馈(FF)和FF +在线优化(为简便起见)得到的结果的比较。与CP-VITON相比,我们的在线优化FID误差降低了约17%,IS得分提高了约15%。(但是请注意,单独使用前馈的FID错误要比CP-VITON高)。 人体评估研究与FID和IS得分均具有良好的相关性,在65%的测试中,我们的结果优于CP-VITON。
-
在线优化的消融研究
为了证明在线步骤的额外计算成本是合理的,我们将在线优化步骤(第3.3节)与(在线)和不使用(FF)方法进行了比较。类似于与CP-VITON的比较,我们使用FID和IS得分以及人工评估。如表1所示,在线优化步骤显示出上衣的FID得分显着提高,并且一件和两件服装的结果相当。我们将上衣的改进归因于以下事实:上衣通常比裤子,夹克和裙子具有更复杂的图案(例如纹理,徽标,刺绣)。请参阅补充材料以获取更多示例。 在线优化步骤还显示出所有三种情况下IS得分的优势或可比的结果。人工评估清楚地证明了在线与单独进给方案相比具有优势,上衣的偏好度为94%,一件衣服的偏好度为78%,两件衣服的偏好度为76%。 -
在线损失是衡量综合质量的标准
我们测试了合成图像的质量与在线优化方案3.3的最小损失值(公式6)之间的关系。我们在高度纹理化的顶部子集上计算了FID和IS得分,并随着优化的进行,测量了一系列损耗值。从1.0的固定间隔1.0的高损耗值开始,直到2.0的损耗值。 图6显示了FID错误(红色)和IS得分(蓝色)的行为。 随着损失值的减少,我们看到FID错误明显减少,IS评分增加。 我们认为在线损耗值与合成质量高度相关。
概括
我们提出了一种新颖的算法(O-VITON),可以改善虚拟的试穿体验,用户可以选择将多件服装组合在一起,形成逼真的外观。O-VITON可直接处理单个2D训练图像,这比成对的训练图像更容易收集和缩放。我们的方法生成了几何上正确的分割图,该图可以更改所选参考服装的形状以符合目标人的要求。该算法使用在线优化方案准确地合成精细的服装特征,例如纹理,徽标和刺绣,该方案可以对合成图像进行微调。 定量和定性评估显示出比现有的最新技术更好的准确性和灵活性。















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









