









卷积(Convolution)
卷积神经网络一直都是计算机视觉任务的标配。卷积有两个基本的性质:
- 空间不变性(spatial-agnostic)
空间不变性使得卷积能够在所有位置共享参数,并充分利用视觉特征的“平移等变性”。 - 通道特异性(channel-specific)
通道特异性使得卷积能够充分建模通道之间的关系,提高模型的学习能力。
卷积过程
-
Standard Convolution

设 X ∈ R H × W × C i X \in R^{H \times W \times C_i} X∈RH×W×Ci是输入的特征图像, H , W H,W H,W是特征图的高度和宽度, C i C_i Ci是输入的通道数。在特征向量 X X X的立方体内部,位于图像点阵单元中的每个特征向量 X i , j ∈ R C i X_{i,j} \in R^{C_i} Xi,j∈RCi认为是代表某些高级语义模式的像素。一组固定核大小为 K × K K \times K K×K的 C 0 C_0 C0卷积滤波器表示为 F ∈ R C 0 × C i × K × K F \in R ^{C_0 \times C_i \times K \times K} F∈RC0×Ci×K×K, 其中每个滤波器 F k ∈ R C i × K × K , k = 1 , 2 , . . . , C 0 F_k \in R ^{C_i \times K \times K}, k=1,2,...,C_0 Fk∈RCi×K×K,k=1,2,...,C0,包含 C i C_i Ci卷积核 F k , c ∈ R K × K , c = 1 , 2 , . . . , C i F_{k,c} \in R ^{K \times K}, c=1, 2, ..., C_i Fk,c∈RK×K,c=1,2,...,Ci。并以滑动窗口的方式对输入特征图执行乘加运算以产生输出特征图 Y ∈ R H × W × C 0 Y \in R^{H \times W \times C_0} Y∈RH×W×C0
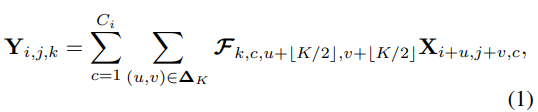
其中, Δ K ∈ Z 2 \Delta K \in Z^2 ΔK∈Z2是指考虑在中心像素上进行卷积的邻域中的一组偏移量, × \times ×表示笛卡尔积。
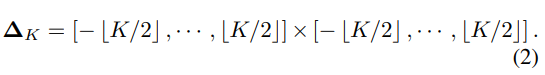
-
Depthwise Convolution

不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。常规卷积每个卷积核是同时操作输入图片的每个通道。Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。即Depthwise层,只改变feature map的大小,不改变通道数。深度卷积将组卷积 的公式推到了极致,其中每个过滤器(实际上退化为单个内核) G k ∈ R K × K , k = 1 , 2 , ⋅ ⋅ ⋅ , C o G_k \in R^{K×K}, k = 1, 2, · · · ,Co Gk∈RK×K,k=1,2,⋅⋅⋅,Co,对由 k k k 索引的单个特征通道严格执行卷积,因此在假设输出通道数等于输入通道数的情况下,从 F k F_k Fk 中消除第一维以形成 G k G_k Gk。 就目前而言,卷积运算变为
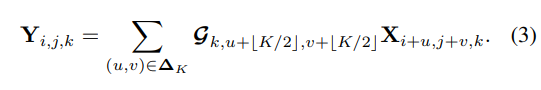
请注意,从通道的角度来看,内核 G k G_k Gk 特定于第 k k k 个特征切片 X ⋅ , ⋅ , k X·,·,k X⋅,⋅,k,并在该切片内的所有空间位置之间共享。
-
Pointwise Convolution

Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。即Pointwise层只改变通道数,不改变大小。
-
Depthwise Separable Convolution
depthwise层,只改变feature map的大小,不改变通道数。而Pointwise 层则相反,只改变通道数,不改变大小。这样将常规卷积的做法(改变大小和通道数)拆分成两步走。是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
卷积分类
二维卷积有full卷积、same卷积核valid卷积。例如:3x3的二维张量
x
x
x和2x2的二维张量
K
K
K进行卷积。
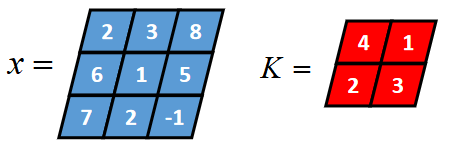
- full卷积
full卷积的计算过程是: K K K沿着 x x x从左到右,从上到下移动,每移动一个固定位置,对应位置的值相乘再求和,计算过程如下:


- same卷积
假设卷积核的长度为FL,如果FL为奇数,锚点位置在 ( F L − 1 ) / 2 (FL-1)/2 (FL−1)/2处,如果FL为偶数,锚点位置在 ( F L − 2 ) / 2 (FL-2)/2 (FL−2)/2处。
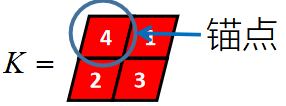
卷积核K都有一个锚点,然后将锚点从左到右,从上到下移动到张量想的每一个位置处,对应位置相乘再求和,计算过程如下:


- valid卷积
对于full卷积,如果K靠近x,就会有部分延伸到x之外,valid卷积值考虑x能完全覆盖K的情况,即K在x的内部移动的情况,计算过程如下:


-
三种卷积类型的关系

-
具有深度的二维卷积
比如x是一个长度为3、宽度为3、深度为2的张量,卷积核K是一个长度为2、宽度为2、深度为2的张量.

其valid卷积过程如下,卷积核K的锚点在张量x范围内从左到右,从上到下移动,输入张量的深度和卷积核的深度是相等的。

-
具备深度的张量与多个卷积核的卷积
1个3行3列2深度的x 与 3个2行2列2深度的卷积核卷积:

Involution
CVPR’21|Involution:超越Convolution和Self-Attention的神经网络新算子是作者和SENet的作者胡杰一起完成的,分享了作者对网络结构设计(CNN和Transformer)的理解。
主要贡献:
- 提出了一种新的神经网络算子(operator或op)称为Involution,它比Convolution更轻量更高效,形式上比Self-Attention更加简洁,可以用在各种视觉任务的模型上取得精度和效率的双重提升。
- 通过Involution的结构设计,能够以统一的视角来理解经典的卷积操作和近来流行的自注意力操作。
Motivation与Convolution的反对称性
普通convolution的kernel享有空间不变性(spatial-agnostic)和通道特异性(channel-specific)两大基本特性;而involution则恰恰相反,具有通道不变性(channel-agnostic)和空间特异性(spatial-specific)。
Convolution

-
空间不变性

-
通道特异性

Involution








Discussion与Self-Attention的相关性
Self-Attention



Vision Transformer

实验结果
总体来讲:
- 参数量、计算量降低,性能反而提升。
- 能加在各种模型的不同位置替换Convolution,比如backbone,neck和head,一般来讲替换的部分越多,模型性价比越高。
ImageNet图像分类

我们使用involution替换ResNet bottleneck block中的3x3 convolution得到了一族新的骨干网络RedNet,性能和效率优于ResNet和其他self-attention做op的SOTA模型。
COCO目标检测和实例分割

其中fully involution-based detectors(involution用在backbone,neck和head)在保证性能略有提升或不变的前提下,能够将计算复杂度减至~40%。
Cityscapes语义分割

COCO检测任务中针对大物体的指标
A
P
L
AP_L
APL提升最多(3%-4%),Cityscapes分割任务中也是大物体(比如墙,卡车,公交车等)的单类别IoU提升最明显(高达10%甚至20%以上),这也验证了我们在之前分析中所提到的involution相比于convolution在空间上具有动态建模长距离关系的显著优势。
Convolution和Involution总结
Convolution更加关注于通道进行的交互,所以在空间维度上进行参数共享;Involution更加关注于空间维度上的信息建模,所以在通道维度上进行了参数共享。但是在实际应用中很可能是通道信息和空间信息都是非常重要的,所以如果能够在空间和通道维度上都基于一定的偏置进行必要的参数共享,达到更好的speed-accuracy trade off。
参考资料
Involution:Inverting the Inherence of Convoution for Visual Recognition(2021)
d-li14/involution
Involution(附对Involution的思考):港科大、字节跳动、北大提出“内卷”神经网络算子,在CV三大任务上提点明显
深度学习面试题10:二维卷积(Full卷积、Same卷积、Valid卷积、带深度的二维卷积)
Depthwise Convolution与普通卷积的区别以及其他卷积方法
CVPR’21 | involution:超越convolution和self-attention的神经网络新算子
Involution=Inverse-Convolution,反着来的卷积?内卷?















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









