











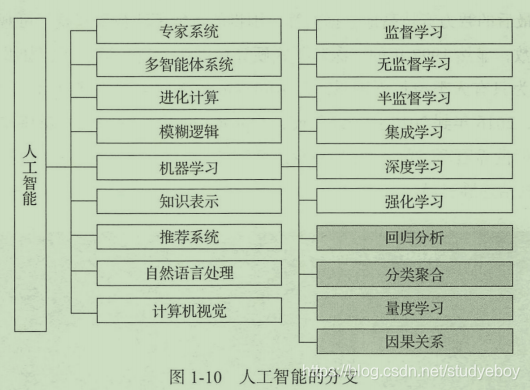
机器学习的研究旨在让计算机学会学习,能够模拟人类的学习行为,建立学习能力,用学习出来的思维模型对真实事件做出决策和预测。
Floyd深度学习云平台
Floyd是一种PaaS服务,用户可以不用关注硬件设备的细节配置方法,只需关注模型本身的实现即可。Floyd是一个便捷高效的深度学习平台,它的整体用户交互非常友好,可以很快的接入到本地的深度学习项目中。在本地项目代码调试完毕后,可以使用Floyd的命令行工具来对接GPU服务器以直接训练模型。Floyd官网
Floyd使用
- Floyd官网注册登录。
- 电脑终端下载Floyd的命令行工具floyd-cli。
pip install -U floyd-cli
- 通过命令行工具进行终端内部的登录,输入下列命令后安装提示输入用户名和密码即可。
floyd login -u <username>
- 在Floyd网页端新建一个项目,点击网右上角的加号,添加项目,然后进行创建,具体信息可以按照个人情况进行设置,免费账号目前仅可开启公开项目。
- 将网页上创建的项目与本地的项目相互绑定。
git clone <project path>
cd <project_name>
- 在项目中进行Floyd的初始化,注意填写的项目名称必须与平台上创建的项目名称保持一致。此外,如果项目添加了第三方库,记得新建一个floyd_requirements.txt文件并将它们写入。
floyd init <project_name>
- 项目完成后可直接通过Floyd工具运行代码,具体命令行参数可以查阅Floyd官网来进行配置。在执行命令后,Floyd工具会将本地代码传至云端,在GPU服务器上进行项目的运行。
floyd run --gpu --env tensorflow-1.3 --tensorboard 'python train.py'
- 在任务执行的过程中,使用状态命令查看实时运行状态,或者到网站的项目状态页进行查询。
Floyd status
- 终端实时查阅任务的日志信息
Floyd logs -t
- Floyd上使用可交互的Jupyter Notebook,在项目终端运行如下命令
Floyd run --gpu --mode jupyter
- 当项目中涉及数据量非常大时,需要先将数据上传到Floyd平台上。在Floyd网站上创建数据集。从终端进入本地的数据集目录中,进行数据集初始化,并执行上传命令。
floyd data init <data_name>
floyd data upload
生成对抗网络
生成模型
在概率论统计理论中,生成模型是指能够在给定某些隐含参数的条件下,随机生成观测数据的模型,它给观测值和标注数据序列指定一个联合概率分布。
在机器学习中,生成模型可以用来直接对数据建模,如根据某个变量的概率密度函数进行数据采样,也可以用来建立变量间的条件概率分布,条件概率分布可以由生成模型根据贝叶斯定理形成。
生成模型的特点在于学习训练数据,并根据训练数据的特点来产生特定分布的输出数据。
对生成模型来说,可以分为两个类型:
- 生成模型可以完全表示出数据确切的分布函数。
- 生成模型只能做到新数据的生成,而数据分布函数则是模糊的。该类型生成新数据的功能通常是大部分生成模型的主要核心目标。
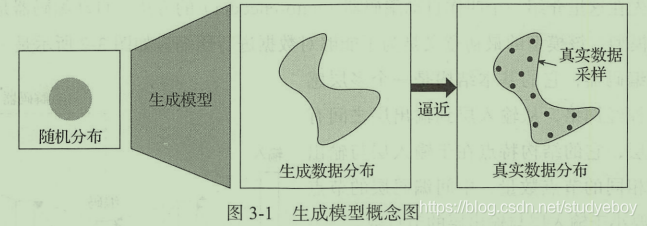
生成模型的功能在于生成“假”数据,但在科学界确实可以起到各种各样的作用。 - 生成模型局部了表现和处理高维度概率分布的能力,而这种能力可以有效运用在数学或工程领域。
- 生成模型尤其是生成对抗网络可以与强化学习领域相结合,形成更多有趣的研究。
- 生成模型可通过提供生成数据,从而能够优化完善半监督式学习。
在业内的应用:
- 使用生成模型用于超高解析度成像,可以将低分辨率的照片还原成高分辨率, 对于大量不清晰的老照片,可以采用该技术加以还原,或者对于各类低分辨率的摄像头等,也可以在不更换硬件的情况下提升其成像能力。
- 使用生成模型进行艺术创作,可以通过用户交互的方式,输入简单的内容,从而产生艺术作品的创作。
- 图像到图像的转换、文字到图像的转换。
自动编码器
生成模型是让机器学习大量的训练数据,从而具备能够产生同类型新数据的能力。
自动编码器(auto-encoder)是一种神经网络模型,该模型的最初意义是为了能够对数据进行压缩。它的基本结构是一个多层感知器的神经网络,从输入到输出层之间有多个隐层,它的结构特点在于输入层与输出层拥有相同的节点数量,中间编码层的节点数量需要小于输入层与输出层的节点数。
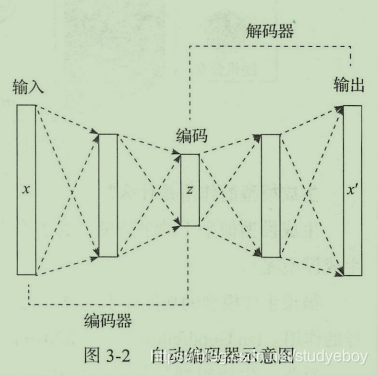
该网络结构希望能够在输出层产生的数据良好的还原输入层的数据,由于中间的编码层数据拥有的维度数量低于输入层与输出层的维度,所以如果输出层可以还原输入层的话相当于对输入数据进行了降维,即数据压缩。
在自动编码器中,把输入层到编码层的网络部分称为编码器,把编码层到输出层的网络部分称为解码器。编码器的作用是可以实现数据的压缩,将高维度数据压缩成低维度数据,解码器则可以将压缩数据还原成原始数据,当然由于对数据进行了降维处理,所以在还原的过程中数据会有一些损失。
自动编码器的训练过程需要将编码器与解码器绑定在一起进行训练,训练数据一般是无标签数据,因为我们会把数据本身作为它自身的标签。
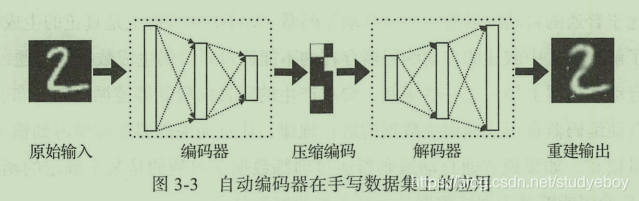
在生成模型的应用中我们仅使用模型的后半部分,当我们对解码器输入任意编码器时,解码器会给出相应的输出数据。由于受到训练数据集的限制,生成的数据往往也是与输入数据相关的内容。
虽然自动编码器看起来似乎是生成模型的一个不错的实现方案,但是在实际使用中存在很多问题,导致自动编码器其实并不太适合用来做数据生成,现在的自动编码器网络结构仅仅能够记录数据,除了通过编码器以外我们无法产生任何隐含编码(latent code)用来生成数据。
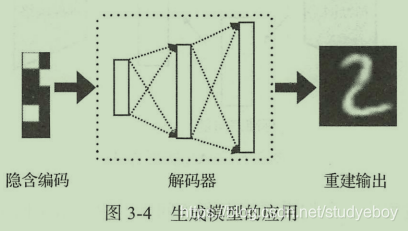
对于一个手写数字我们会产生一个相应的编码,当我们对解码器输入相应的编码的时候往往能够很好还原出当时的手写数字,然而当我们对解码器输入一个训练集中未出现过的编码时,我们可能会发现输出的内容居然是噪声,即与手写数字数据集完全没有关系。这不是我们想要的结果,我们希望生成模型能够对任意的输入编码产生有相关意义的数据,针对这个问题,研究人员提出了自动编码器的升级版本–变分自动编码器(Variational Auto-Encoder, VAE)。
变分自动编码器
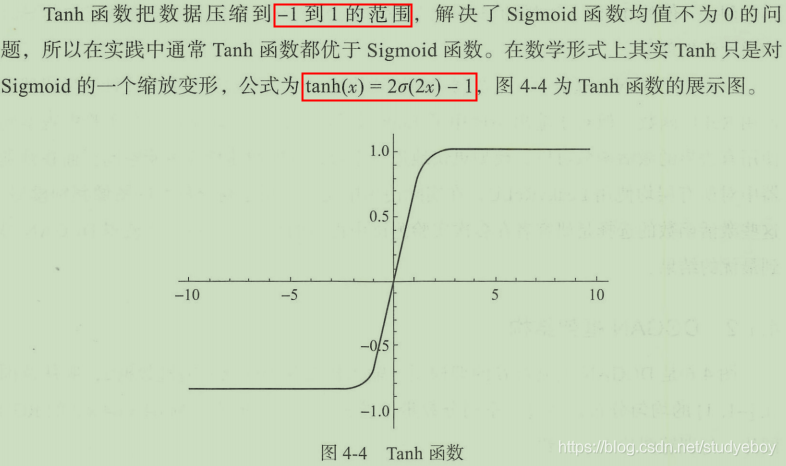
相比于普通的自动编码器,变分自动编码器(VAE)才算的上是真正的生成模型。VAE在普通的自动编码器上加入了一些限制,要求产生的隐含向量能够遵循高斯分布,这个限制帮助自动编码器真正读懂训练数据的潜在规律,让自动编码器能够学习到输入数据的隐含变量模型。如果说普通自动编码器通过训练数据学习到的是某个确定的函数的话,那么VAE希望能够基于训练数据学习到参数的概率分布。
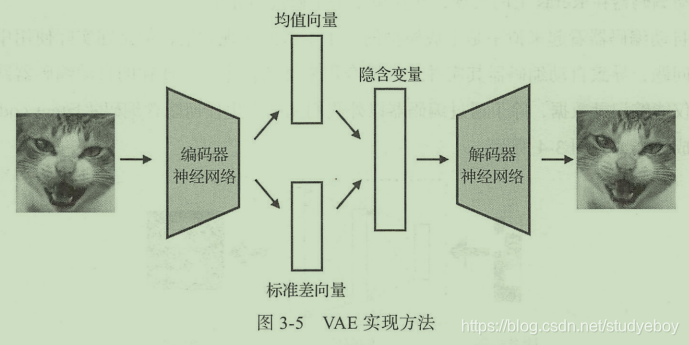
VAE在编码器阶段将编码器输出的结果从一个变成两个,两个向量分别对应均值向量和标准差向量。通过均值向量和标准差向量可以形成一个隐含变量模型,而隐含编码向量正是通过对于这个概率模型随机采样获得的。最终通过解码器将采样获得的隐含编码向量还原成原始图片。
在实际的训练过程中,需要衡量两个问题:
- 网络整体的准确度
- 隐含变量是否可以很好的吻合高斯分布
对应这两个问题也就形成了两个损失函数:
- 描述网络还原程度的损失函数,具体的方法是输出数据与输入数据之间的均方距离;
- 隐含变量与高斯分布相近的损失函数,采用KL散度来计算隐含变量与高斯分布的接近程度。
KL散度(Kullback-Leibler divergence),可以称作相对熵。KL散度的理论意义在于度量两个概率分布的差异程度,当KL散度越高的时候,说明两者的差异程度越大;当KL散度较低的时候,则说明两者的差异程度较小。如果两者相同的话,则该KL散度应该为0.

使用VAE,只需要从高斯分布中随机采样一个隐含编码向量,然后将其输入解码器后即可生成全新的数据。
当然VAE也存在缺陷,VAE的缺点在于训练过程中最终模型的目的是为了使得输出数据与输入数据的均方误差最小化,这使得VAE其实质上并非学会了如何生成数据,而是更倾向于生成与真实数据更为接近的数据,甚至于为了数据越接近越好,模型基本会复制真实数据。
为了解决VAE的缺点,出现了优秀生成模型生成对抗网络GAN。
GAN的数学原理
最大似然估计
在最大似然估计中,会对真实数据集定义一个概率分别函数 P d a t a ( x ) P_{data}(x) Pdata(x),其中 x x x相当于真实数据集中某个数据点。为了逼近真实数据的概率分布,为生成模型定义一个概率分布函数 P m o d e l ( x ; θ ) P_{model}(x; \theta) Pmodel(x;θ),这个分布函数也是通过参数变量 θ \theta θ定义的。在实际计算过程中,我们希望通过改变参数 θ \theta θ,从而使得生成模型概率分布 P m o d e l ( x ; θ ) P_{model}(x; \theta) Pmodel(x;θ)能够逼近真实数据概率分布 P d a t a ( x ) P_{data}(x) Pdata(x)。
当然在实际的运算中,我们是无法知道
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x)的形式的,我们唯一可以做的的是从真实的数据集中采样大量的数据,也就是说从
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x)中取出
{
x
1
,
x
2
,
.
.
.
x
m
}
\{x^1, x^2,...x^m\}
{x1,x2,...xm},通过这些真实的样本数据,我们计算对应生成模型的概率分布
P
m
o
d
e
l
(
x
;
θ
)
P_{model}(x; \theta)
Pmodel(x;θ)。现在根据训练数据集可以写出概率函数,通过将所有的真实样本计算出在生成模型中的概率并全部进行相乘。

现在最大似然估计的目标是通过上面这个概率的式子,寻找一个
θ
∗
\theta^*
θ∗,使得
L
L
L最大化。这样做的实际意义是,在给出真实训练集的前提下,希望生成模型能够在这些数据上具备最大的概率,这样才说明我们的生成模型在给出的训练集上能够逼近真实数据的概率分布。


KL散度是一种计算概率分布之间相似程度的计算方法。设定两个概率分别分别为
P
P
P和
Q
Q
Q,在假定Wie连续随机变量的前提下,对应的概率密度函数分别为
p
(
x
)
p(x)
p(x)和
q
(
x
)
q(x)
q(x),则:

从上述公式可以看出,当且仅当
P
=
Q
P=Q
P=Q时,
K
L
(
P
∣
∣
Q
)
=
0
KL(P||Q)=0
KL(P∣∣Q)=0。KL散度具备非负的特性,即
K
L
(
P
∣
∣
Q
)
≥
0
KL(P||Q) \geq 0
KL(P∣∣Q)≥0。KL散度不具备对称性,
P
P
P对于
Q
Q
Q的KL散度并不等于
Q
Q
Q对于
P
P
P的KL散度。
在特定情况下,通常是
P
P
P用以表示数据的真实分布,而
Q
Q
Q表示数据的模型分布或近似分布。将公司推导成KL散度的形式:
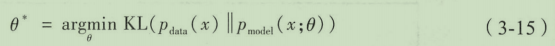
我们希望最小化真实数据分布与生成模型分布之间的KL散度,从而使得生成模型尽可能接近真实数据的分布。在实际实践中,我们是几乎不可能知道真实数据分布
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x)的,我们使用训练数据形成的经验分布在逼近
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x)。
在实践中我们会发现使用最大似然估计方法的生成模型通常会比较模糊,愿因是一般的简单模型无法使得 P m o d e l ( x ; θ ) P_{model}(x; \theta) Pmodel(x;θ)真正逼近真实数据分布,因为真实数据是否非常复杂的。为了模拟复杂分布,可以解决的方法是采用神经网络(例如GAN)实现 P m o d e l ( x ; θ ) P_{model}(x; \theta) Pmodel(x;θ),可以把简单分布映射成为几乎任何的复杂分布。
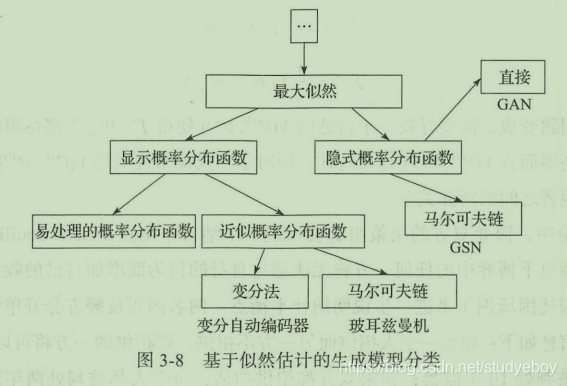
基于似然估计的生成模型分类:
- 显式模型
- 隐式模型
两者的核心差别在于生成模型是否需要计算出一个明确的概率分布密度函数。在大部分情况下,研究生成模型的目的在于生成数据,对于分布密度函数是什么样,可能并没有太大的兴趣。
生成对抗网络的数学推导
生成模型会从一个输入空间将数据映射到生成空间,即 x = G ( z ) x=G(z) x=G(z)。通常输入 z z z会满足一个简单形式的随机分布(高斯分布或者均匀分布),为了使生成空间的数据分布能够尽可能的逼近真实数据分布,生成函数 G G G会是一个神经网络的形式,通过神经网络可以模拟出各种不同的分布类型。
虽然可以清楚的指导前置输入数据
z
z
z的概率分别函数,但在经过一个神经网络的情况下难以计算最终的生成空间分布
P
m
o
d
e
l
(
x
)
P_{model}(x)
Pmodel(x),就无法计算概率函数
L
L
L。

在博弈论中,博弈双方的决策组合会形成一个纳什平衡点(Nash equilibrium),在这个博弈平衡点下博弈中的任何一方将无法通过自身的行为而增加自己的收益。
纳什平衡点经典囚徒困境案例:
两名囚犯被警方分开单独审讯,他们被告知的信息如下:如果一个人招供而另一方不招供,则招供的一方将可以立即释放,而另一方会被判处10年监禁;如果双方都招供的话,每个人都被判处两年监禁;如果双方都不招供,则每个人都仅判半年监禁。两名囚犯由于无法交流,必须做出对自己最有利的选择,从理性角度出发选择招供是个人的最优决策,对方做出任何决定对于招供方都会是一个相对较好的结果,我们称这样的平衡为纳什平衡点。
在生成对抗网络中,我们要计算的纳什平衡点是要寻找一个生成器
G
G
G与判别器
D
D
D使得各自的代价函数最小,从上面的推导中可以得出我们希望找到一个
V
(
θ
(
D
)
,
θ
(
G
)
)
V(\theta ^{(D)}, \theta ^{(G)})
V(θ(D),θ(G))对于生成器来说最小而对判别器来说最大。可以把它定义成一个寻找极大极小值的问题。

可以用图形化的方法理解这个极大极小值的概念,一个很好的例子是鞍点(saddle point),即在一个方向是函数的极大值点,而在另一个方向是一个函数的极小值点。

Jensen-Shannon散度,简称JS散度,在概率论统计中,JS散度与KL散度一样具备了测量两个概率分布相似程度的能力,它的计算方法基于KL散度,继承了KL散度的非负性等,不同点是,JS散度具备了对称性。


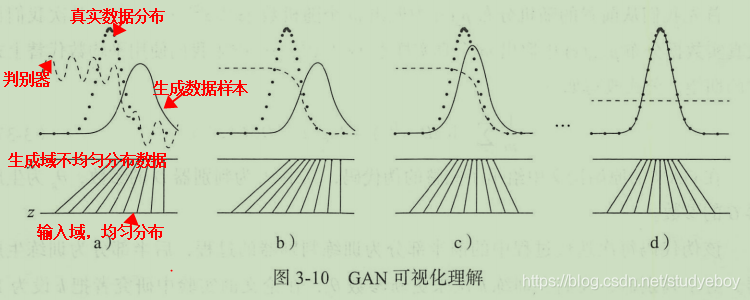
GAN的可视化理解
在下图中,点线为真实数集分布,曲线为生成数据样本,生成对抗玩了个在这个例子中的目标在于,让曲线(生成数据的分布)逐渐逼近点线(真实数据分布)。虚线为生成对抗网络中的的判别器,在实验中赋予它初步区分真实数据与生成数据的能力,并对它的划分性能加上一定的白噪声,使得模拟环境更为真实。输入域
z
z
z(图中下方的直线)在这个例子里默认为一个均匀分布的数据,生成域
x
x
x(图中上方的直线)为不均匀分布数据,通过生成函数
x
=
G
(
z
)
x=G(z)
x=G(z)形成一个映射关系,将均匀分布的数据映射成非均匀数据。

深度卷积生成对抗网络(DCGAN)
DCGAN的框架
DCGAN的设计规则
《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》(2015)在GAN的几层上提出了全新的DCGAN架构,该网络在训练过程中状态稳定,并可以有效实现高质量的图片生成及相关的生成模型应用。由于其具有非常强的实用性,在它之后的大量GAN模型都是基于DCGAN进行的改良版本。
为了使得GAN能够很好的适应于卷积神经网络架构,DCGAN提出了四点架构设计规则,分别是:
-
使用卷积层代替池化层
使用卷积层替代池化层的目的是为了能够让网络自身取学习空间上采样与下采样,使得判别器和生成器都能够有效具备相应的能力。对于判别器,使用步长卷积(strided convolution)来代替池化层;对于生成器,使用分数步长卷积(fractional-strided convolution)来代替卷积层。

-
去除全连接层
常规的卷积神经网络往往会在卷积层后添加全连接层用以输出最终向量,但全连接层参数过多,当神经网络层数深了以后运算速度变得非常慢,此外全连接层也会使网络容易过度拟合。使用全局平均池化(global average pooling)来替代全连接层,可以使得模型更稳定,但也影响了收敛速度。DCGAN将生成器的随机输入直接与卷积层特征输入进行连接,同样对于判别器的输出也是卷积层的输出特征连接。 -
使用批归一化(batch normalization)
由于深度学习的神经网络层数很多,每一层都会使得输出数据的分布发生变化,随着层数的增加网络的整体偏差会越来越大。通过对每一层的输入进行归一化处理,能够有效使得数据服从某个固定的数据分布。

-
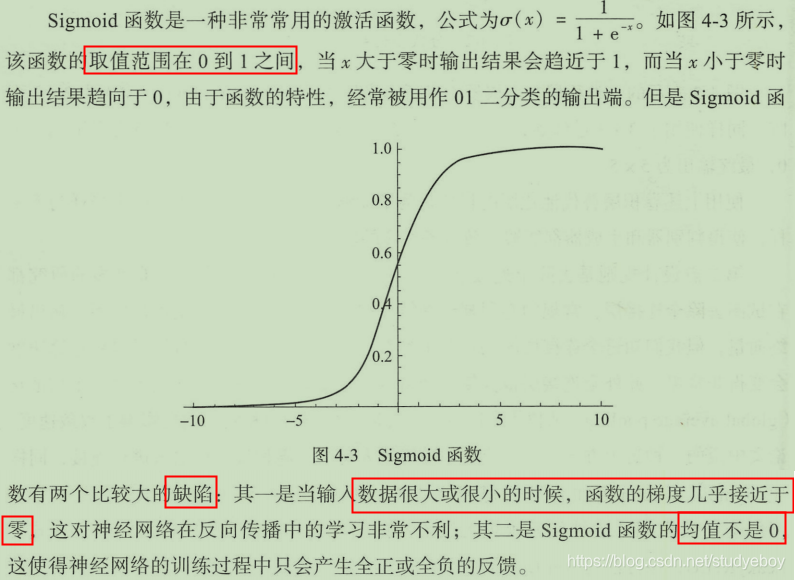
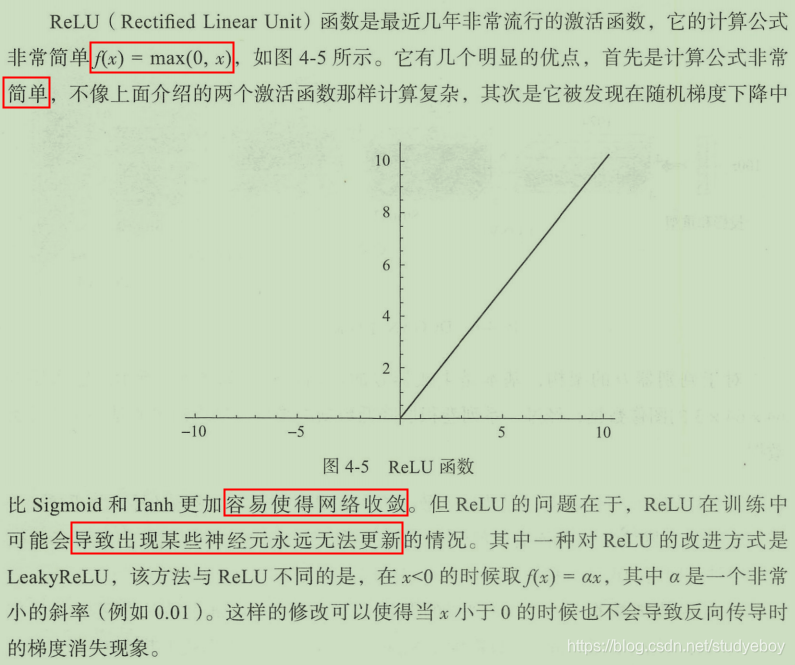
使用恰当的激活函数
激活函数的作用是为了在神经网络中进行非线性变换。在DCGAN网络中,生成器和判别器使用了不同的激活函数来设计。生成器中使用了ReLU函数,但对于输出层使用了Tanh激活函数,因为研究发现使用有边界的激活函数可以让模型更快的进行学习,并能快速覆盖色彩空间。在判别器中对所有层均使用了LeakyReLU,在实际使用中尤其适用于高分辨率的图像判别模型。
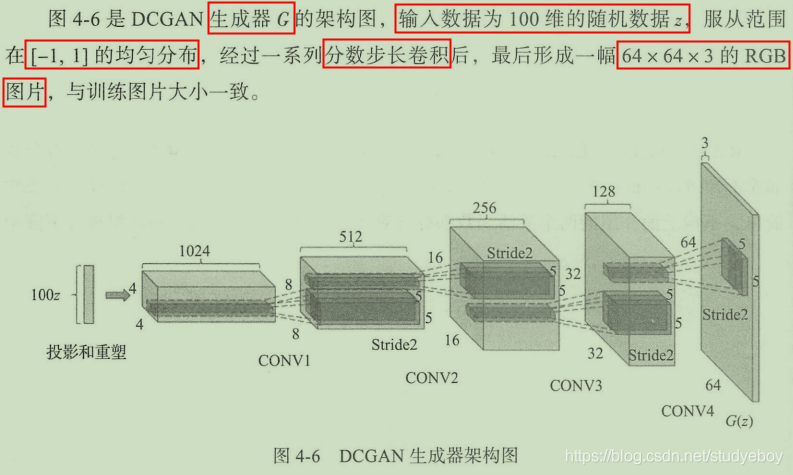
DCGAN框架结构
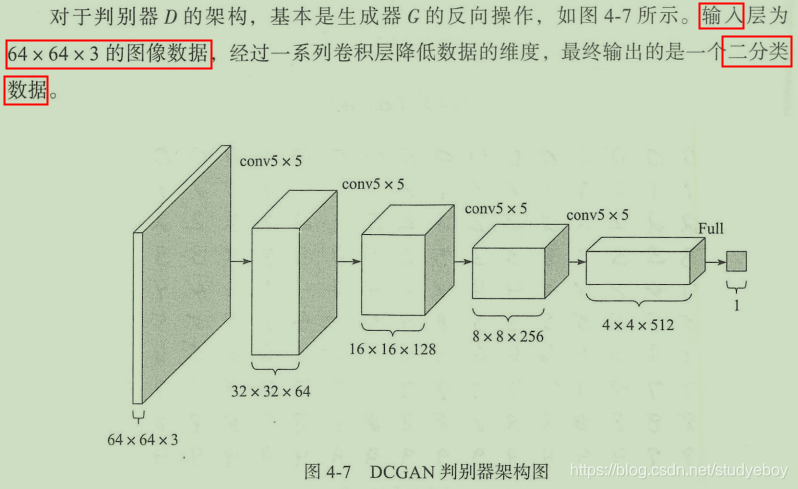

DCGAN的工程实践
- 搭建DCGAN的类,定义基础信息(以MNIST数据为例)
- 由于是黑白图像,通道数为1,输入图片的尺寸为(28,28,1)。
- 输入的隐含编码的维度是100维。
- 定义生成器函数
- 定义判别器函数
- 定义训练函数
- 根据DCGAN的设计搭建生成器
- 使用上采样加卷积层来代替池化层
- 中间不包含全连接层
- 加入批归一化
- 生成器中激活函数使用ReLU函数,输出层使用了Tanh
- 根据DCGAN的设计构建判别器
- 使用步长为2的卷积层来代替池化层
- 中间不不包含全连接层
- 添加批归一化
- 激活函数使用LeakyReLU,斜率为0.2
- 其他设置
- 优化器使用的是Adam,根据之前的说明学习率使用了0.0002,动量 β 1 \beta_1 β1取值0.5.
- 分别设置判别器与生成器的目标函数、优化与评估标准,其中要注意的是
训练生成器的时候需要将判别器与生成器相连,这个时候需要将判别器设置为不可训练模式,仅优化生成器参数。
- 训练部分代码
- 从MNIST中载入数据
- 将输入数据缩放到[-1, 1]的范围。
- 训练的过程与GAN一样,先用生成数据与真实数据训练判别器,而后用随机输入和训练好的判别器来训练生成器。
DCGAN的实验性应用
生成图像的变换
- 图像的隐含空间(latent space),随着输入 z z z的不断变换,输出的图像会平滑地转变成另一幅景象。
- 传统的有监督式的CNN网络通常在中间层中能够学习到某些事物的特征,而对于无监督额DCGAN在基于大量图片数据的训练后同样能够学习到很多有趣的特征。
生成图像的算术运算
词嵌入
所谓的词嵌入是指将单词映射到一个低维度连续向量空间中的技术,用词嵌入技术构成的词向量在空间中具备了一定的语义关系,含义比较接近的词在词向量空间中距离会比较近一些。
利用词向量计算一样的思路,直接使用像素作为向量进行计算,通过实验,最终的效果其实是不好的,最后的计算结果基本无法分辨。

在生成对抗网络的生成器中其实已经有了输入向量和输出图像的对应关系,我们可以把这个向量作为图像的向量表示,通过这样的图像算术计算,可以实现很多非常有意思的功能。

基于此方法,可以进行图像演变的制作,当我们把某个图像的向量线性转换成另一个图像的向量的时候,对应的图像也会逐渐转移。

残缺图像的补全

使用生成网络补全图像需要满足两个条件:
- 使用DCGAN在大量头像数据训练后能够生成“骗过”判别器的照片;
- 生成图像与原图像未丢失部分的差值要尽量最小。

Wasserstein GAN
GAN的优化问题
最大的问题来源与训练的不稳定性,在理论上,应该优先尽可能的把判别器训练好,但实际操作上会发现,当判别器训练的越好,生成器反而越难优化。
真实数据的分布通常是一个低维度流形。生成器要做的事情是把一个低维度的空间Z 映射到与真实数据相同的高维度空间上,而我们希望做的使其是能够把我们生成的这个低维度流形尽可能的逼近真实数据的流形。
所谓流形(manifold),其实是指数据虽然分布在高维度空间里,但实际上数据并不具备高维度特性,而是存在于一个嵌入在高维度的低维度空间里。例如,三维空间上的数据点,本质上存在于一个二维平面,只是以卷曲的形式存在于三维空间中。

在实际实践中,生成数据和真实数据在空间中完美重合的概率是非常低的,所以几乎大部分情况下我们都可以找到一个完美的判别器将生成数据和真实数据加以划分就是说这会导致在网络训练的反向传播中,梯度更新几乎等于零,也就是说网络很难在这个过程中学到任何东西。

所以,采用这些散度公式来计算两者的相似度似乎并不是一个非常好的方法,很难通过这些散度公式来优化网络。即当判别器训练的非常好,这也导致了生成器的梯度消失问题。当判别器在逼近完美判别器的时候,生成器优化的梯度会有一个非常小的上界,并且无限接近于0.
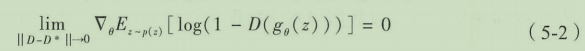
为了避免梯度消失问题,对生成器换一个不同的梯度函数。
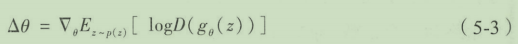
通过修改梯度函数可以有效避免梯度消失问题,但是这个梯度函数会导致网络更新不稳定。随着训练迭代次数的上升,梯度上升非常快,同时曲线的噪声也在变大,也就是说梯度的方差也在增加,这样会导致样本质量低的情况。
另一个方案是对判别器的输入人为的加入一个随机的噪声。当生成数据分布与真实数据分布很接近的时候,加入了随机噪声可以使得两者的低维度流形能够有更多的几率产生重合,使得JS散度的计算值下降,从而有效优化网络参数。但是,当生成数据与真实数据本身相似度劜较远的话,添加噪声的方案可能就无效了。
WGAN的理论研究


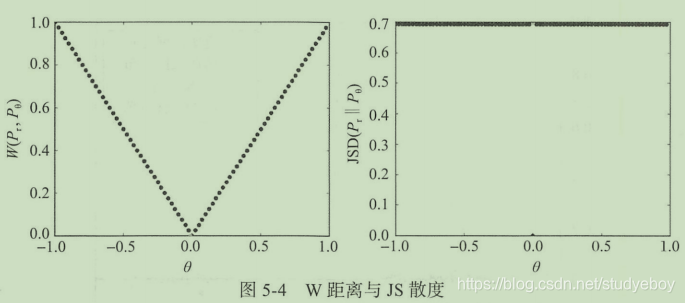

网络要做的事情是通过判别器的梯度来优化网络参数,让生成数据分布尽可能的靠近真实数据分布,而我们可以很明显的看到原始GAN在两个分布各自的区域所对应的梯度几乎是零,也就是所谓的梯度消失,非常那一对网络进行优化迭代,而WGAN对应的梯度则几乎是线性的,可以很好的达到真实数据分布与生成数据分布重合的目的。
WGAN的工程实践


WGAN与GAN相比较:
- 两者最大的差别在于WGAN经过推导得出的代价函数中并不存在log函数,但其他与原始GAN基本保持一致。
- 对于判别器D,由于WGAN的目标在于测量生成数据分布与真实数据分布之间的距离,而非原始GAN的是与否的二分类问题,所以除去了判别器D最后输出层的Sigmoid激活函数。
- 在更新权重的时候,需要加上权值剪裁使得网络参数能够保持在一定的范围内,从而满足之前推导所需的Lipschitz条件。
- 将Adam等梯度下降法改为使用RMSProp方法,这个是WGAN的作者经过大量实验得出的经验,使用Adam等方法会导致训练不稳定,而RMSProp可以有效避免不稳定问题的发生。
用Keras实现WGAN:
- 首先修改判别器,在WGAN的理论中判别器的本质已经是一个距离测量的评估者critic,而非二分类问题的判别者,故在DCGAN的判别器代码基础上去除最后的sigmoid激活函数。
- 在训练过程中使用权值剪裁的方法使得网络参数能够保持在一定的范围内。
- 设置Wasserstein距离作为WGAN的损失函数。
- 设置判别次数为5,权值剪裁的值为0.01.
- 需将Adam等梯度下降方法改为使用RMSProp方法。
WGAN的实验效果分析
代价函数与生成质量的相关性
W距离和生成图像之间的关系,如果能够保证距离越近,图像生成质量越高的话,可以说WGAN是有效的。
生成网络的稳定性
WGAN具有比原始GAN更稳定的生成能力,在最优架构的情况下也许还无法体现出优势,但一旦网络中存在问题的话,使用WGAN能够在一定程度上避免生成图像质量的极速下降。
模式崩溃
模式崩溃(mode collapse),是指生成器不具备多样性,不断重复同样的图像或者同类型的图像作为生成结果。在实际的研究中法向,虽然彻底的模式崩溃不多见,但是部分模式崩溃其实是很普遍的。所谓的部分模式崩溃是指,生成网络只产生真实数据分布中的一部分数据,或者说会漏掉一小部分类型的数据。这在研究人员的实验验证中也很难被发现。
WGAN的改进方案:WGAN-GP
WGAN理论中一个非常重要的条件是需要满足1-Lipschitz条件,而对应使用的方法是权值剪裁,希望吧整个网络的权值能够框定在一个大小范围内。但是权值剪裁会产生很多问题,WGAN-GP使用梯度惩罚(gradient penalty)的方法替代本来的权值剪裁,并且从实验结果来看确实比原来的方案更稳定,在图像生成方面成像质量也更高。
权值剪裁存在的问题:
- 权值剪裁限制了网络的表现能力,由于网络权值被限制在了固定的范围内,神经网络很难再模拟出那些复杂的函数。
- 梯度爆炸和梯度消失。WGAN的权值剪裁需要设计权值限制的大小,也许不恰当的设计就会导致梯度爆炸或梯度消失。
为了避免权值剪裁的问题,需要使用一种替代的方法实现Lipschitz条件。WGAN-GP给出的方案就是梯度惩罚。1-Lipschitz条件,满足该条件的函数在任意位置的梯度都小于1。可以完全考虑直接根据网络的输入来限制对应判别器的输出。更新目标函数,在原有WGAN的基础上添加梯度惩罚项
L
g
p
L_{gp}
Lgp。


不同结构的GAN
从另一个角度来对GAN进行改造,从而在优化生成效果的同时也让生成网络具备了更强的能力。
GAN与监督式学习
条件式生成:cGAN
传统机器学习中的监督式学习,指的是通过有标签数据集训练模型的一种机器学习方式,训练后的模型可以对未标签数据进行分类或回归分析。在机器学习的分类问题上,神经网络的监督式学习可以达到比较理想的效果。
把监督式学习的想法放在生成模型上,我们期待的结果是希望可以根据网络输入的标签生成对应的输出。传统的神经网络模型可以实现这样的功能,可以将带标签数据集的标签项作为模型训练的输入,内容项作为模型训练的输出,训练后的结果就可以根据对应的标签输出相应的内容。
这样的设计乍看没有问题,但是实际效果往往不理想。最核心的问题子阿姨标签数据集存在标签一对多的情况,以文本生成图像作为例子,一句文本对应的图像可能会有很多个,标签虽然相同但是在内容本身上相差甚远。在这样的情况下,传统的神经网络模型会尽量让该标签的输出结果和每一个训练结果都尽量接近,这导致生成图像会非常模糊,甚至无法分辨。其次,输出的内容是多样性的,现有的神经网络在面对大规模输出类型的情况下还存在很多挑战。
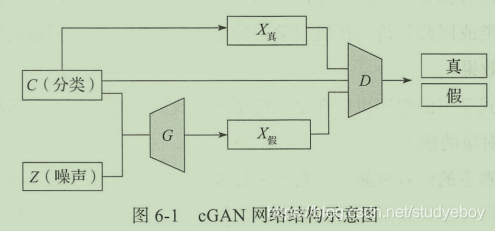
为了解决带标签数据集的生成问题,在GAN的基础上提出了条件生成对抗网络(cGAN),在传统的生成模型上,都无法很好的控制数据生成的模型,而cGAN可以通过参数的控制来指导数据的生成。
产痛GAN的目标函数,在生成器和判别器的训练过程中模型的目标是取得一个极小极大值。
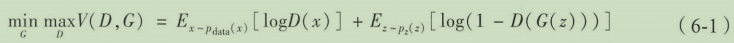
条件式cGAN是对传统GAN的一个扩充,在原有的网络结构情况下,对判别器和生成器的输入都加上一个额外的辅助信息
y
y
y,这个
y
y
y可以是该数据的分类标签等。
条件GAN的目标函数,整体上并没有任何变化,只是判别器的输入
x
x
x与生成器的随机输入
z
z
z都加上了条件
y
y
y。
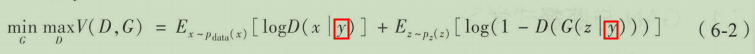
在生成器中,我们从前置随机分布
p
z
(
z
)
p_z(z)
pz(z)中取出随机输入
z
z
z,再与条件输入
y
y
y进行拼接组合,形成一个全新的隐含表示。而在判别器中,真实数据
x
x
x或生成数据
G
(
z
)
G(z)
G(z)都会和条件
y
y
y共同输入以进行判别。
cGAN在图像上的应用
基于cGAN的思想,很多新型的GAN模型试图解决一些应用层面的问题。拉普拉斯生成对抗网络(LAPGAN),它的核心目标是通过该网络能够在GAN基础上生成高质量的图片,解决目前传统GAN生成质量差的问题。
下采样:对原始图像的模糊和压缩。
上采样:对原始图像的放大和扩展。
高斯金字塔: G ( I ) = [ I 0 , I 1 , . . . , I k ] G(I)=[I_0, I_1, ..., I_k] G(I)=[I0,I1,...,Ik],其中 I 0 I_0 I0为原始图像,之后的每一个 I k I_k Ik都是 I k − 1 I_{k-1} Ik−1的下采样,整个数组呈现一个从大到小的金字塔形状。
拉普拉斯金字塔: L ( I ) L_(I) L(I),它是每一项是高斯金子塔中相邻两项的差,公式如下,其中函数 u ( . ) u(.) u(.)表示对图像的上采样。

LAPGAN基于通过模糊图像和拉普拉斯金字塔的参数和不断的上采样和差值补充,可最终重建原始的高清图像理论,应用了cGAN的思想,通过生成模型来产生拉普拉斯金字塔系数。
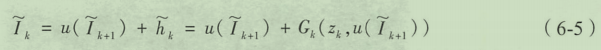
整个生成过程可以对应下图的网络结构,最初的输入为一个随机变量
z
K
z_K
zK,通过最初的生成器产生最初的图片数据
I
~
K
=
G
K
(
z
K
)
\widetilde{I}_K=G_K(z_K)
I
K=GK(zK),经过一系列基于条件的生成模型
{
G
0
,
.
.
.
,
G
K
}
\{G_0,...,G_K\}
{G0,...,GK},在每一层可以生成对应的拉普拉斯金字塔系数
h
~
k
=
G
k
(
z
k
,
u
(
I
k
+
1
)
)
\widetilde{h}_k=G_k(z_k, u(I_{k+1}))
h
k=Gk(zk,u(Ik+1)),而每一层的输出图像则由
h
k
h_k
hk与
I
K
I_K
IK相加而成。
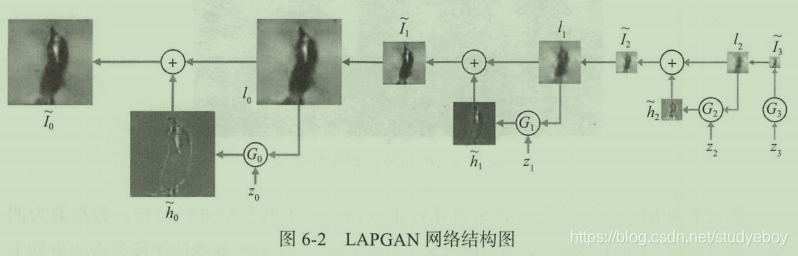
下图是网络的整体训练过程框架图,每一层其实可以看作单独训练的cGAN,其中每个网络的条件数据都是真实图片经过下采样和上采样后的模糊图片。这样独立训练带来的好处是网络很难产生“记忆”训练数据的情况,避免了重复输出训练集中图片的问题。
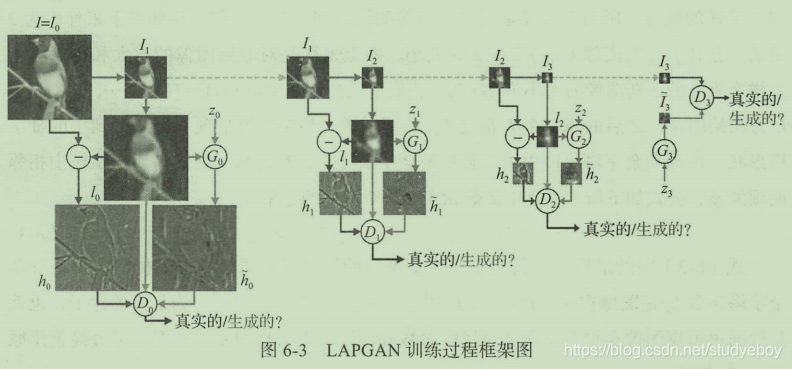
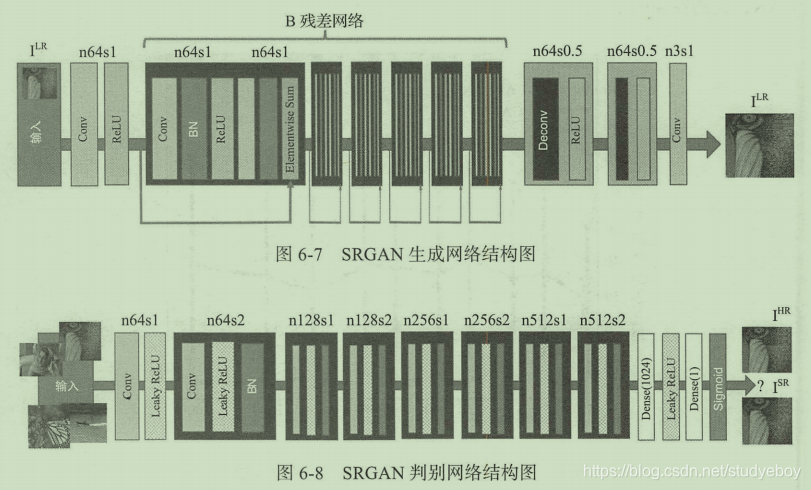
LAPGAN是从随机数据开始生成高清图片,类似的方案其实可以应用在图像的超分辨率上。超分辨率GAN(SRGAN)正是这样一种实现图片分辨率提升的生成对抗网络。所谓的超分辨率是指将原始图像的分辨率提高。
GAN与半监督式学习
半监督式生成:SGAN
半监督式学习是结合监督式和无监督式这两种方式,同时利用少量标签数据与大量无标签数据进行训练,从而实现对于未标签数据的分类问题。
生成网络训练中的真实数据集可以被看作有标签数据集,而由生成器随机产生的数据则可以被看作无标签数据集。
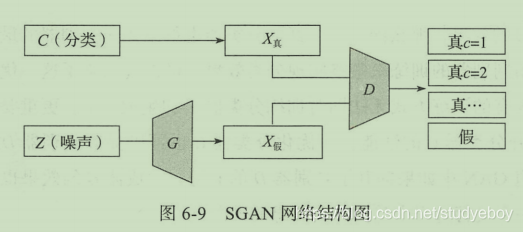
半监督式GAN(SGAN),同时训练生成器与半监督式分类器,实现一个更优的半监督式分类器,以及一个成像质量更高的生成模型。SGAN把二分类(比如sigmoid函数)转变成了多分类(softmax),类型数量为N+1,分别指代N个标签的数据和一个“假”数据,表示为
[
C
1
,
C
2
,
.
.
.
C
n
,
F
a
k
e
]
[C_1, C_2,...C_n, Fake]
[C1,C2,...Cn,Fake]。在实际计算过程中,判别器和分类器其实是融为一体的,记作D/C,他们共同与生成器G形成一个博弈关系,最小最大化目标函数为负向最大似然估计(NLL)。

与cGAN相比,对于生成器的输入端没有将标签信息进行输入,判别器产生的生成数据是随机分布的,并不受网络输入的控制。此外对于判别器的输出而言cGAN仅仅是‘真’和‘假’的二分类,SGAN是一个分类器与判别器的结合体。
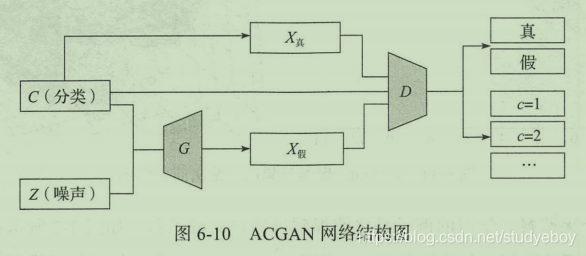
辅助分类生成:ACGAN
使用有标签的数据集应用于生成对抗网络可以有效增
强现有的生成模型,并且形成两种优化的思路:
- cGAN 中使用了辅助的标签信息来增强原始 GAN ,对生成器与判别器均使用标签数据对进行训练,从而实现生成模型具备产生特定条件数据的能力 此外, 另外一些研究也表明, cGAN 所产生的生成模型在生成图像的质量上也比传统的方式会更优一当辅助标签信息更丰富的时候,效果也会随之继续提升。
- SGAN 从另一个方 利用辅助标签信息, 利用 别器或分类器一端来重建标签信息 ,从而提升 GAN 的生成效果 从一些研究实验结果可以发现,当我们强制让模型处理额外信息时,反而会让模型本来的生成任务完成得更好,优化后的分类器可以有效提升图像的综合质量。
辅助分类 GAN (以下简称 ACGAN )把这两种方案结合起来建立起来的生成对抗网络 ,通过对结构的改造将上面的两个优势整合在一起,利用辅助标签信息产生更高质量的生成样本。
ACGAN 的生成器有两个输入,一个是标签分类信息 C ∼ P c C \sim P_c C∼Pc,另一个随机数据 z z z,得到生成数据为 X f a k e = G ( c , z ) X_{fake}=G(c, z) Xfake=G(c,z)。对于判别器分别要判断数据是否为真实数据的概率分布 P ( S ∣ X ) P(S|X) P(S∣X)以及数据源对于分类标签的概率分布 P ( C ∣ X ) P(C|X) P(C∣X)。
ACGAN的目标函数包含两部分,第一部分
L
s
L_s
Ls是面向数据真实与否的代价函数,第二部分
L
c
L_c
Lc则是面向数据分类准确性的代价函数。
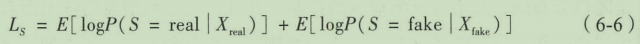
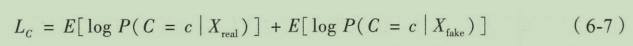
在ACGAN的训练中,优化的方向是训练判别器D能够使得
L
s
+
L
c
L_s+L_c
Ls+Lc最大,而生成器G使得
L
s
−
L
c
L_s-L_c
Ls−Lc最小。对应的物理意义是希望判别器能够尽可能的区分真实数据和生成数据并且能够有效的对数据进行分类,而对于生成器来说则是希望生成数据被尽可能的认为是真实数据且数据都能够被有效分类。
ACGAN的网络结构如下所示,它与之前的cGAN和SGAN都非常接近,是二者的结合体。这样的修改可以有效生成高质量的生成结果,并且使得训练更加稳定。
GAN与无监督式学习
无监督式学习与可解释型特征
无监督式学习是监督式学习的反面,它的训练数据集是大量的无标签数据。无监督最大的优势在于能够对无序的数据进行一个在机器层面的分组归类,对于数据分析而言是非常有价值的。一个优秀的无监督式学习算法可以在事先不了解任何分类任务的情况下,仍然可以正确的猜测到分类情况。
无监督式学习k-means聚类,在该算法中向量空间中距离较近的数据点会被自动归成同一类型。大致的算法思路是对于一组都是 d d d维的向量数据集,算法会产生 k k k个聚类集合,并把所有向量都分配到最近的聚类中,并且要求每个组内平方和是最小的。在对几何数据反复的迭代更新后,算法会收敛于某个局部最优解。
无监督式学习的自动编码器,通过神经网络对于高维度的数据进行编码与解码的训练,从而产生一个中间层的低维编码。对于各类复杂的数据集,可以通过自动编码器的方法有效提取低维编码,这些低维编码是对于原始数据中真实信息量的提取。
生成对抗网络(GAN)在大部分的情况下也属于无监督式学习的一类,通过隐含向量来生成对应的高维度数据。生成对抗网络的隐含向量是模拟了真实数据空间的低维度编码,当在隐含空间中移动的时候,生成的图像也会相应的平滑转变。该隐含向量也具备计算属性。
无监督式学习在上面几个算法中都能够实现不错的效果,但是在某些场景下不一定非常有效,因为经过特征训练后的数据表征并非可解释型特征,这可能对之后的分类任务帮助非常有限。例如对于GAN的大部分模型其隐含输入的每一个维度并不含有具体含义,如果改变传统的GAN输入端的单个参数,并不会使得最终生成结果发生太大的变化,只有多个维度组合才会产生有意义的改变。
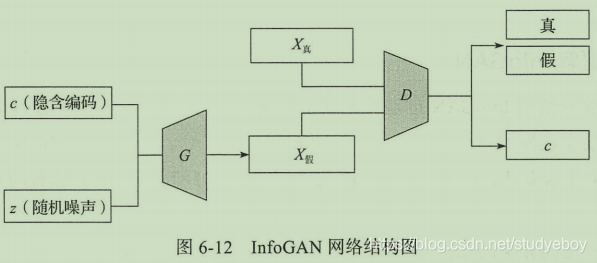
理解InfoGAN
InfoGAN采用的是无监督式学习的方式并尝试实现可解释特征。InfoGAN中最大的改进是使用了信息论的原理,通过最大化输入噪声和观察值之间的互信息(Mutual Information,MI)来对网络模型进行优化。研究人员表示,InfoGAN能够适用于各类复杂的数据集,可以同时实现离散特征与连续特征,较传统的GAN训练时间更短。
InfoGAN在输入端把随机输入分为两个部分:第一部分为 z z z,代表速记噪声,第二部分为 c c c,代表隐含编码,目标是希望在每个维度上都具备可解释型特征。我们把隐含编码的每个维度定义为 c 1 , c 2 , . . . , c L c_1, c_2, ..., c_L c1,c2,...,cL,这样就可以把隐含编码的分布写作 P ( c 1 , c 2 , . . . , c L ) = ∏ i = 1 L P ( c i ) P(c_1, c_2, ..., c_L)=\prod_{i=1}^LP(c_i) P(c1,c2,...,cL)=∏i=1LP(ci)。对于InfoGAN的生成器,我们将噪声 z z z和隐含编码 c c c同时输入得到 G ( z , c ) G(z, c) G(z,c),对于传统的GAN通常会忽略辅助的隐含编码信息 c c c,这样会使得生成概率 P G ( x ∣ c ) = P G ( c ) P_G(x|c)=P_G(c) PG(x∣c)=PG(c)。为了应对这种问题,在InfoGAN中需要对隐含编码 c c c和生成分布 G ( z , c ) G(z, c) G(z,c)求互信息 I ( c ; G ( z , c ) ) I(c;G(z, c)) I(c;G(z,c)),并使其最大化。
InfoGAN的网络结构如下图所示,真实训练数据并不带有标签信息,而输入数据为隐含编码和随机噪声的组合,最后通过判别器一端和最大化互信息的方式还原隐含编码的信息。判别器D最终需要同时具备还原隐含编码和辨别真伪的能力。为了生成图像能够很好的具备编码中的特性,即隐含编码可以对生成网络产生相对显著的效果;而其他GAN要求生成模型在还原信息的同时保证生成的数据与真实数据非常逼近。
互信息表示两个随机变量之间依赖程度的度量。对于随机变量
X
X
X和随机变量
Y
Y
Y,定义它们的互信息为
I
(
X
;
Y
)
I(X;Y)
I(X;Y),计算公式如下式所示,可表达为两种不同的熵计算公式,其中
H
(
X
)
H(X)
H(X)和
H
(
Y
)
H(Y)
H(Y)为边缘熵,而
H
(
X
∣
Y
)
H(X|Y)
H(X∣Y)和
H
(
Y
∣
X
)
H(Y|X)
H(Y∣X)为条件熵。
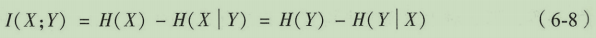
从互信息的定义和上面的公式可知,当
X
X
X和
Y
Y
Y相互独立的时候,互信息
I
(
X
;
Y
)
=
0
I(X;Y)=0
I(X;Y)=0。相反,如果说
X
X
X和
Y
Y
Y相关程度很高的话,互信息也就会非常大。也就是说对于任意给定的输入
x
∼
P
G
(
x
)
x \sim P_G(x)
x∼PG(x),希望生成器
P
G
(
c
∣
x
)
P_G(c|x)
PG(c∣x)有一个相对较小的熵,即希望隐含编码
c
c
c的信息在生成过程中不会流失。对于生成对抗网络的最大最小问题,我们需要把目标公式做修改并转换为下式:
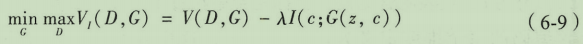


文本到图像的生成
2016年谷歌公司已经实现了比较高质量的机器图像理解,对于一张图像,计算机可以写出非常准确的文字描述。而通过文本描述产生图像却一直是行业中一个颇具有挑战的方向,也是一项非常令人期待的突破。
文本条件式生成对抗网络
实现文本到图像的生成可以分为两个步骤:第一步是从文本信息中学习提取文本特征,并确保这些文本特征能够具备重要的可视细节;第二步是将这些文本特征转化为人们可以直观看到的图像信息,与GAN的思想一致的是这些生成的图像需要“骗过”人眼,让人们以为是真实图像而非生成图像。
在生成图像过程中,文本描述与图像通常是一对多的关系,即一段文本描述其实可以对应多种不同的图片。使用传统的深度学习方法会导致生成质量非常模糊,因为传统的方法总是希望最终输出的结果能与训练集中所有对应的输出接近,而文本对应的图像在像素层面的差别还是非常大的,如果采用的是综合平均的方法,会导致效果较差。
GAN利用对抗网络的训练可以有效应对这种一对多的关系。使用cGAN的方法来实现文本条件下的图像生成。文本条件式DCGAN,文本的编辑信息同时应用于生成器与判别器并作为条件信息,通过卷积层的处理将文本条件信息转化为图像信息。
优化方法:
-
使用具备配对意识的判别器(简称GAN-CLS方案),相比标准的架构来说,判别器处理判断输出图像的真假之外,还需要分辨出失败的生成内容是属于生成图像不真实还是生成图像不匹配。

-
使用流形插值的方案(简称GAN-INT方案),深度神经网络能够寻找到高维度匹配数据的低维流形,这使得我们可以对训练集做一些插值的工作。文本数据是一种离散数据,两个文本对应的向量之间的数据不可能不代表任何含义,但可以把它们看作一种辅助的优化信息。
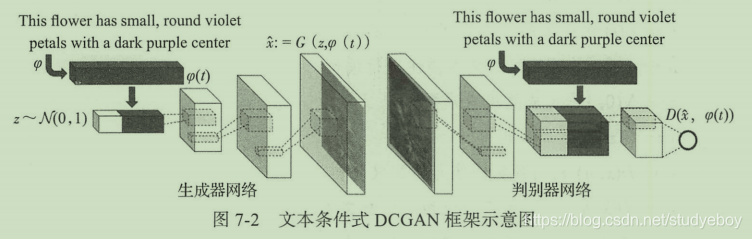
文本生成图像进阶:GAWWN
GAWWN是一种同时基于文本条件与位置或姿态条件的生成对抗网络,核心思想都是将额外的条件信息添加到生成器与判别器的训练中。
文本到高质量图像的生成
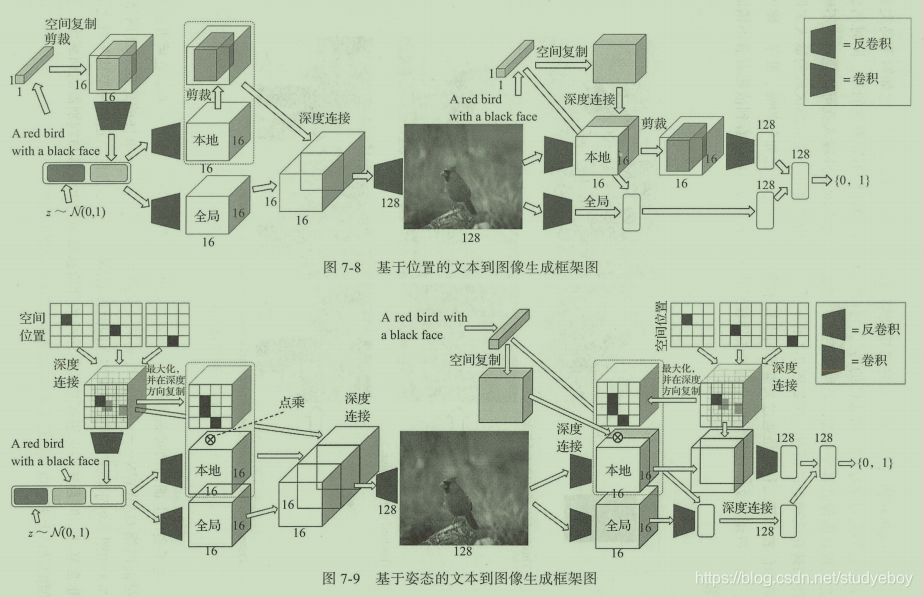
大部分文本生成图像都存在生成图像模糊不清的问题,因为文本具有多义性,一段文本描述的信息其实可以对应多种多样的图像,并且每一幅都是正确的。
层级式图像生成:StackGAN
StackGAN核心理念是把问题进行拆分,将文本生成高清图像的认为拆分为两个子任务:第一个任务是通过文本生成一个相对模糊的图像,第二个任务是从模糊的图像生成高清图像。
StackGAN网络分为两部分,Stage-I GAN与Stage-II GAN,分别对应各自的子任务。此外在最初的输入部分,StackGAN提出了一个条件增强(conditioning aug)的模块用以提升输入的向量信息。
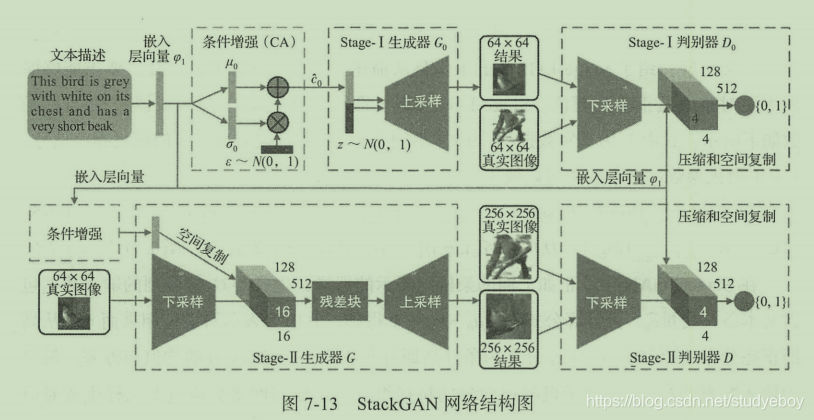
- Stage-I GAN:
根据给定的文本描述,生成描述对象的基本形状和颜色,并通过随机噪声输入来随机绘制背景,生成一张相对低分辨率图片。它的输入条件文字描述与随机噪声,输出为低分辨率图片。 - Stage-II GAN:主要负责修正低分辨率图像的不足,并通过再次读取文字描述来丰富图片中的细节,从而生成最终的高分辨率图片。
在网络的输入端通常需要通过文本嵌入技术把输入文本 t t t转换为向量形式 φ t \varphi_t φt。该向量形式的维度特别高,通常会大于100维,而训练数据又十分有限,会导致输入数据在隐含空间中是不连续额,这样的数据集对训练生成器非常不友好。
条件增强技术正是要解决这个问题,添加了一个附加的条件变量 c ^ \hat c c^。该变量 c ^ \hat c c^采样自独立的高斯分布 N ( μ ( φ t ) , ∑ ( φ t ) ) N(\mu(\varphi_t), \sum(\varphi_t)) N(μ(φt),∑(φt)),这样在少量文本图像配对的数据训练集情况下能够产生更多的数据,同时对于微小的扰动能够更好的提高系统的健壮性。
为了使这些条件数据在隐含输入空间中更为平滑且避免过度拟合的问题,条件增强技术要求网络在训练过程中优化下式。通过增大标准高斯分布和条件高斯分布之间的KL散度,能够让网络产生更多样性的输出,即对于类似的句子,能够产生更多不同的输出图像。
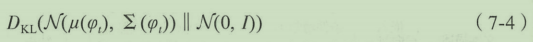


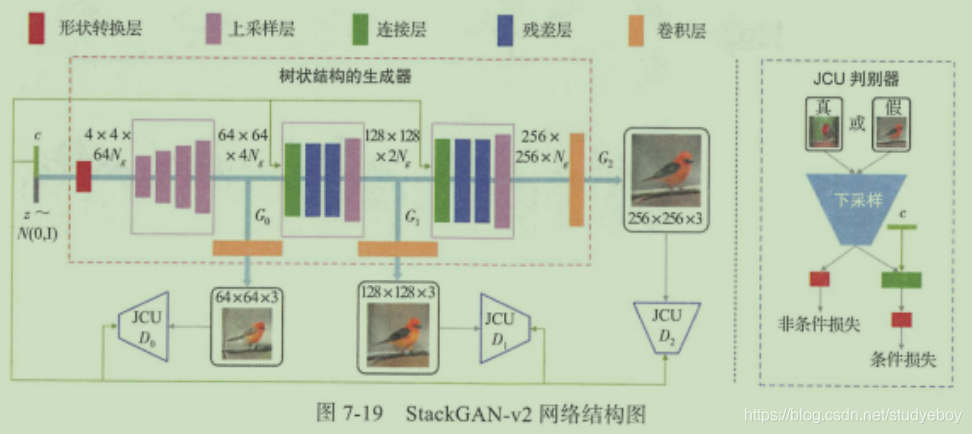
层级式图像生成的优化:StackGAN-v2
为了让StackGAN更加通用,适用于各种尺寸的输出图像,Stack-GAN的研究作者又提出了StackGAN-v2版本。

图像到图像的生成
把复杂的图像数据作为生成对抗网络的输入条件,实现图片到图片的生成。
可交互图像转换:iGAN
iGAN是发表于2016年的研究,开启了GAN在图像到图像生成中的应用,该论文的作者在发表了iGAN之后继续先后提出了非常著名的Pix2Pix与CycleGAN。
可交互图像转换的用途
iGAN提出一种图像到图像的生成模型,让用户可以通过简单的几笔勾画出自己脑海中的物体形象,虽然只是草图的形式,可能并不能完整或者甚至有些抽象,但是模型可以自动进行图像转换,生成对应图像的真实样子。

首先需要将原始图像投射到低维度的自然图像流形中,在这个低维度流形中的每一个图像都可以对应到真实的自然图像。
iGAN的实现方法
自然图像流形(natural image manifold),假设我们把图像数据的全集看作一个高维度空间,其中包含了各式各样的图像,它的维度只与像素有关而与内容无关。自然图像是指真实世界的图像,即人类可以理解的图像,我们把自然图像数据集看作图像数据集全集的一个低维度流形,在这个流形上的所有数据都能够对应一张人们可以理解的自然图像,且数据间具有连续性,随着点在流形上移动,输出的图像数据也会发生连续的变化。
iGAN使用生成对抗网络来近似产生自然图像流形。对于以下三点,GAN都很好的满足了自然图像流形所具有的特性:
- 虽然GAN在细节上可能还是不能满足需求,但是从随机输出来看,GAN基本能输出一个合理且可理解的样子。
- 自然图像流形的相邻图像数据应该在图像感知上具备相似性,这与GAN的设计非常接近。当GAN隐含空间输入数据很接近的时候,输出的图像也是非常类似的。
- 自然图像流形中两点之间的图像连续性,即指从一个点到另一个点应该可以实现平滑的切换。
iGAN的核心流程:
- 将目标图片降维到自然图像流形上,GAN可以用一个隐含特征向量还原原始图片。
- 通过改变这个输入的隐含特征向量,保证更新后的图像能够既满足用户的编辑,也保证能够接近自然图像的流形。这样可以实现交互式图像修改。
- 在图像转换的过程中生成模型会丢失原始图像中的细节部分,iGAN中使用了一些插值技术来尽可能还原图像细节。
iGAN软件简介与使用方法
匹配数据图像转换:Pix2Pix
理解匹配数据的图像转换
实际生活中许多问题都希望能通过输入的图像生成我们希望的对应图像。例如:将黑白输入的图像转变成彩色图像,对于过去一个时代中大量的黑白复原会有很大的帮助;将航拍的街道图像转换为地图图像输出,可以有效减少地图绘制的时间;将手绘的草图转化为真实事物的照片。虽然这些应用的应用点都有所不同,但是在技术层面其实都是从图像到图像的转换,完全可以采用同样的结构和模型并应用到各自的数据集中。
所谓匹配数据集是指在训练集中两个相互转换的领域之间有明确的一一对应数据。例如训练集里黑白照片会对应一张彩色照片,航拍照片会对应已有的地图图片,草图手绘稿会对应真实事物的照片。
同时收集两个不同领域的匹配数据是麻烦的,通常采用的方案是从更完整的数据中还原简单数据。可以直接将彩色图片通过图像处理的方法转为黑白图片;也可以用边缘提取技术,将真实图片提取边缘以模拟手绘草图的样子;航拍图和地图需要到谷歌地图上直接寻找匹配对;黑夜和白天的图像转换,需要事先收集同一场景的白天和黑夜的照片。
使用卷积神经网络来解决这类“图像翻译”问题,最宠的图像转换会非常模糊,因为卷积神经网络会试图让最终的输出接近所有相类似的结果。而生成对抗网络可以很好的避免这一问题的产生,Pix2Pix是基于生成对抗网络的匹配数据图像转换的解决方案。
Pix2Pix的理论基础
Pix2Pix是iGAN的作者在2017年发表的论文研究成果,同样采用了cGAN的思想,将输入的图像作为生成对抗网络的条件。在网络结构的设计上,pix2pix基本参考了DCGAN的结构,使用了卷积层、批归一化以及ReLU激活函数。
Pix2Pix使用cGAN训练生成对抗网络的思路。

cGAN的目标函数,其中
D
(
x
,
y
)
D(x,y)
D(x,y)表示真实配对数据输入图像
x
x
x与输出图像
y
y
y对于判别器
D
D
D的结果,而
D
(
x
,
G
(
x
,
z
)
)
D(x,G(x,z))
D(x,G(x,z))则是
x
x
x经过生成器产生的图像
G
(
x
,
z
)
G(x,z)
G(x,z)对于判别器判断的结果。
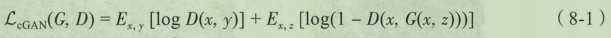
除了cGAN优化函数外,Pix2Pix还加入了L1 Loss作为传统的损失函数对网络加以优化。
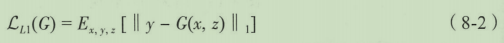
最终的生成器目标函数如下所示,其中
λ
\lambda
λ为超参量,可以根据情况调节,当
λ
=
0
\lambda = 0
λ=0时表示不采用L1 Loss 的损失函数。
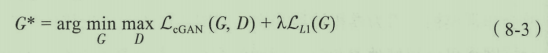
虽然cGAN中没有随机参量
z
z
z,其实整个网络也是可以运行的,但这导致的结果是生成器的每一个输入都会对应一个确定的输出结果。

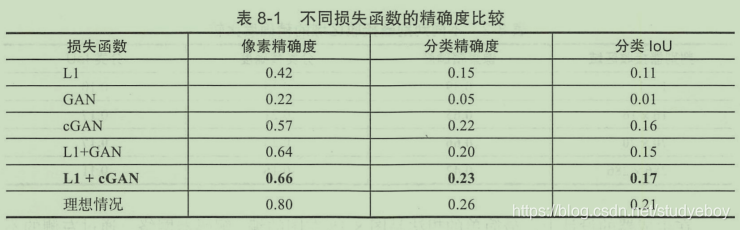
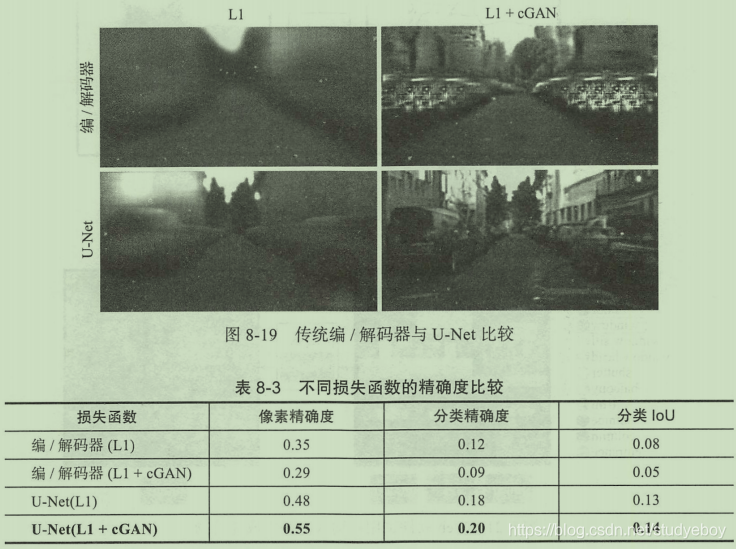
L1 Loss的输出结果是大致接近原始图像额,但是由于之前提到传统深度学习的问题即导致生成图像非常模糊,而使用cGAN所生成的图像则具备了细节清晰的效果,但是它的问题在于额外添加了很多不必要的细节,有时离原本的真实图像在细节上差距较大。最后一组L1 + cGAN的输出结果是比较令人满意的,总和了两者的特性,既完善了细节也保证了一致性。
L1 Loss用于生成图像的大致结构、轮廓等,也可以说是图像的低频部分。而cGAN则主要用于生成细节,是图像的高频部分。Pix2Pix在这一点上进行了优化,研究者认为既然GAN仅用于高频部分的生成,那么在训练过程中也没有必要把整个图像都拿来做训练,仅需把图像的一部分作为判别器的接收区域即可,即PatchGAN思想。由于参数更少了,PatchGAN可以使得训练过程变得更加高效,同时也可以针对更大的图像数据集进行训练。
在Patch的大小上Pix2Pix进行了测试,针对原始图像为286x286的情况,分布采用了1x1像素(称为PixelGAN)、16x16像素、70x70像素以及全图286x286像素(称作ImageGAN),结果如下图所示。相比于模糊的L1生成图像,PixelGAN虽然未能在图像细节上改进,但是在彩色上面已经优于原始L1的方案。16x16和70x70的PatchGAN均取得了比较不错的效果,相比之下70x70在色彩还原和图像细节上都更胜一筹,而最后ImageGAN和70x70的PatchGAN在色彩还原和图像细节上都更胜一筹,而最后ImageGAN和70x70的PatchGAN相差不大。在最终的数据结果中,70x70的PatchGAN取得了更好的成绩。
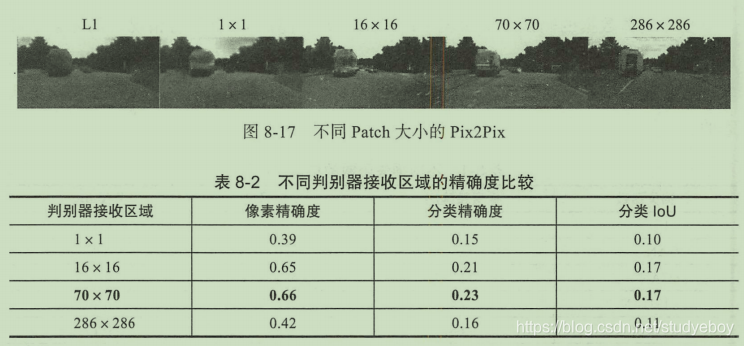
在生成器的设计上,最简单的想法是通过编/解码器网络,通过左侧的不断下采样到达中间的隐含编码层,然后再通过右侧的上采样来还原图像。在Pix2Pix的应用中,这种方案是可行的,但是似乎少利用了一些匹配图像数据中已有的信息。
虽然匹配数据的风格或样式不同,但是整体的架构和结构是类似的,可以利用U-Net结构,它将与自动编码器网络不同的是,左侧和右侧的网络之间添加了很多跳跃连接,可以将部分有用的重复信息直接共享到生成器中。
Pix2Pix的应用实践
非匹配数据图像转换:CycleGAN
理解非匹配数据的图像转换
在2017年同时有两篇非常相似的论文CycleGAN和DiscoGAN提出了一种解决非匹配数据集的图像转换方案。其中CycleGAN的作者团队是iGAN和Pix2Pix的研究团队,他们在图像到图像生成领域,做出了非常大的贡献。
图像风格的转换,比较流行的方法是通过卷积神经网络将某个画作中的风格叠加到原始图片上,它是将两张特定的图片之间进行转换。但是CycleGAN实现的风格转换是存在于两个图像领域中的。
白天和黑夜的衰减跨度不够大,但是要实现风景图片夏天与冬天的相互转换,这个对于Pix2Pix这样的匹配数据训练来说几乎是难以实现的。
CycleGAN给出的最著名的就是斑马和马的相互转换,这是大自然中天然的一对同一物种但是外观风格完全不同的经典例子。由于马是动态的,我们没有办法分别捕获同一场景同一姿势的斑马与马的照片,只有采用非匹配数据集的方法才可以实现他们之间的转换。

CycleGAN的理论基础
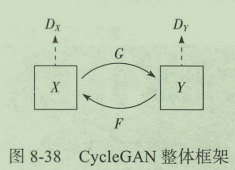
CycleGAN的核心是由两个生成对抗网络的合作组成的。
X
X
X与
Y
Y
Y分别代表两组不同领域的图像数据,第一组生成对抗网络是生成器
G
G
G(从
X
X
X到
Y
Y
Y的生成)与判别器
D
Y
D_Y
DY,用于判断图像是否属于领域
Y
Y
Y;第二组生成对抗网络是反向的生成器
F
F
F(从
Y
Y
Y到
X
X
X的生成)与判别器
D
X
D_X
DX,用于判断图像是否属于领域
X
X
X。两个生成器
G
G
G和
F
F
F的目标是尽可能生成对方领域中的图像以“骗过”各自对应的判别器
D
Y
D_Y
DY和
D
X
D_X
DX。
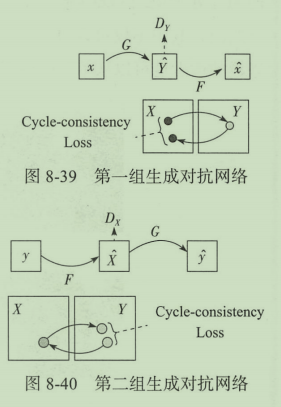
需要将两组生成对抗网络有机地结合起来。首先,在生成器
G
G
G通过一条件数据
x
x
x生成
Y
Y
Y领域中的数据
Y
^
\hat Y
Y^后,需要将它通过对面的生成器
F
F
F重新还原一个原来领域中的
x
^
\hat x
x^,为了保证一致性,希望让
x
x
x和
x
^
\hat x
x^尽可能接近,而
x
x
x和
x
^
\hat x
x^中间的距离我们称为Cycle-consistency Loss。
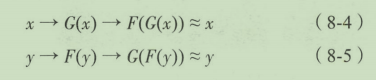
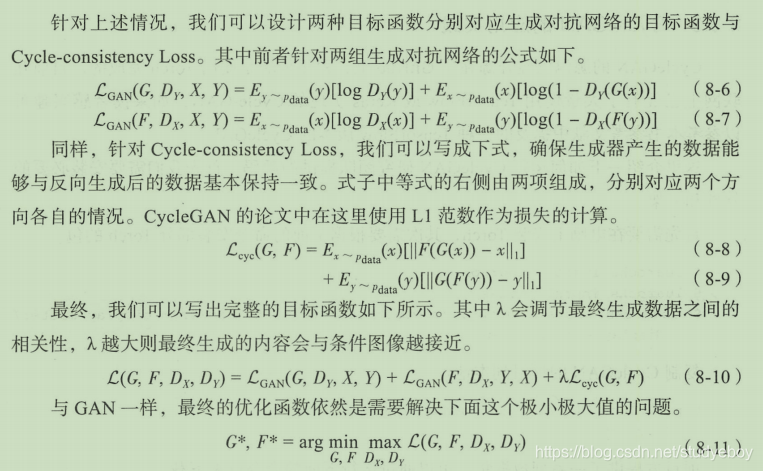
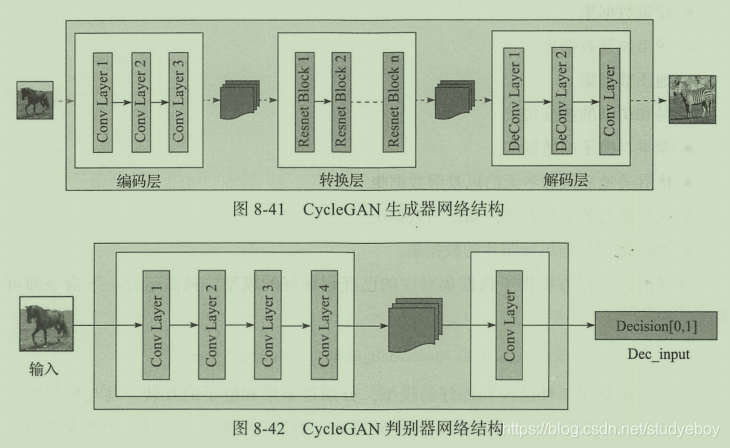
在网络结构设计上,CycleGAN参考了李飞飞团队在风格迁移网络方面的研究。生成器网络结构由编码层、转换层和解码层三部分组成。判别器的网络结构是一个简单的卷积神经网络,用来判断输入图像是否属于某一分类。
CycleGAN的应用实践
-
成功的例子:


-
失败的例子
当测试数据与训练数据差距过大的时候,如源数据为人骑马的照片,然而训练集中只有马并没有人,这导致模型最终生成的图片里把人也打上了斑马条纹 。


将 Pix2Pix CycleGAN应用到了中文的不同字体,对于不同的字体我们可以收集到匹配数据或者是非匹配数据 i2zi 的论文是使用了 Pix2Pix 的技术在匹配数据上进行训练,但问题在于工程量浩大,而且生成的字体仅限于一些具备完整字库的字体 CycleGAN 可以有效
解决非匹配字体情况下的生成,理论上对于每个个人来讲,可以通过 CycleGAN 的技术生成任何自己风格的文字,通过 CycleGAN成的不同字迹,虽然并非与真实情况完全一样,但是在字里行间已经有了原来字体的神韵。


多领域图像转换:StarGAN
多领域的图像转换问题
Pix2Pix与CycleGAN分别解决了两个领域之间基于匹配数据和非匹配数据的转换。但是在实际的应用中我们会发现需要大量的多领域转换。例如:智能修图的场景,用户输入一张人物照片,通过选项来调节照片中人物的外貌,比如发色、性别、年龄、肤色等;对于同一个人物照片希望能够将他转换成各种不一样的表情,从普通的表情转换为愤怒、喜悦和恐惧等。
Pix2Pix和CycleGAN可以非常好的解决领域间转换问题,他们同样可以应用于多领域的转换,但是存在的问题是必须在每两个邻域之间进行单独的训练。假设场景为表情转换,一共有四个领域,分别为中性、生气、喜悦与恐惧,我们将它们从1到4标号。如果使用CycleGAN,在每个邻域都需要训练两个生成器,比如领域1和邻域3之间,就需要有生成器G31和G13,分别作为从3到1和从1到3的生成。在四个领域的情况下已经需要12个不同的生成器了,随着领域数量的增加,该数量会越来越大,要训练这么多生成模型是非常消耗资源的。
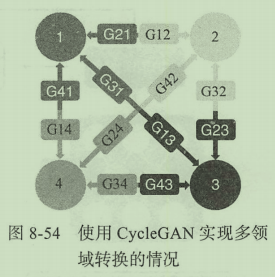
除了训练过程中的资源消耗以外,CycleGAN的方法在每两个邻域之间进行生成器的训练,那么各自的训练过程都是独立的,独立的训练会浪费大量可用辅助优化生成器的数据,这是不合理的。
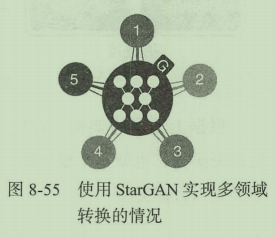
StarGAN的论文在2017年年底发布在arxiv上,并随后发表在了计算机视觉领域会议CPR2018。StarGAN提供了一种针对多领域的解决方案,在多领域转换的情况下仅需训练一个通用的生成器即可。对于五个领域的情况仅需中间的一个生成器G即可,整个网络形成一个星形的拓扑结构,这也是StarGAN的命名由来。
StarGAN的理论基础
StarGAN的网络设计借鉴了CycleGAN和cGAN的思想。StarGAN的判别器的输入为任意分类的真伪图片,输出部分需要将所有数据都进行真伪判断,对真数据还需要进行所述领域的分类,这一判别器类似于ACGAN。
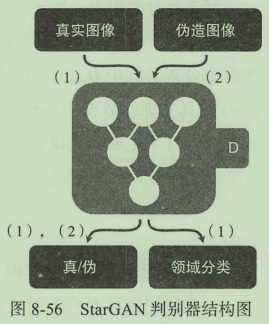
StarGAN的网络结构,对于生成器的输入不仅需要原始图片,同时还需要像cGAN一样设定一个目标领域。由生成器产生的图像会进入判别器中进行判定,目标是让判别器将其判定为真实图像且属于目标领域。与此同时该生成图像还需要再次输入本身的生成器中,且将输入条件设置为源领域,用于重建原始图像,确保重建的图像能够与原始图像越接近越好。
StarGAN的目标函数,首先是生成器能否让判别器认为该生成图像为真实图像,其中
c
c
c为条件参数,表示目标类型。
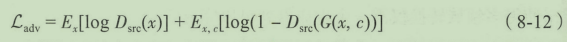
其次是分类损失函数,同样也要同时对生成器和判别器进行优化,可以写成两种分类损失:第一种是对于真实数据的分类损失
L
c
l
s
t
L_{cls}^t
Lclst,第二种是假数据的分类损失
L
c
l
s
f
L_{cls}^f
Lclsf。
D
c
l
s
(
c
′
∣
x
)
D_{cls}(c'|x)
Dcls(c′∣x)代表判别器将真实输入
x
x
x归为原始分类
c
′
c'
c′的判别概率分布,
(
x
,
c
′
)
(x, c')
(x,c′)是真实训练数据中的分类匹配数据,判别器
D
D
D的目标是最小化这个损失函数。对于生成器来说希望基于
x
x
x的生成数据能够被判别器判断为目标分类
c
c
c,需要
G
G
G能够最小化损失函数
L
c
l
s
f
L_{cls}^f
Lclsf。
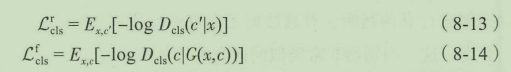
构建重建损失,确保生成的数据能够很好的还原到本来的领域分类中。使用原始数据和经过两次生成(先转换到分类
c
c
c,再转换为源分类
c
′
c'
c′)的图像L1损失作为重建损失,公式如下:
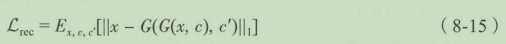
最终的目标函数如下,分为判别器与生成器。其中
λ
c
l
s
\lambda_{cls}
λcls和
λ
r
e
c
\lambda_{rec}
λrec为超参数,用来控制分类损失、重建损失相对于对抗损失的重要性,在StarGAN原文的实验中取
λ
c
l
s
=
1
\lambda_{cls}=1
λcls=1和
λ
r
e
c
=
10
\lambda_{rec}=10
λrec=10。

StarGAN的另外一个创新点在于能够同时协调多个包含不同领域的数据集,不同数据集之间是不知道对方的分类标签是什么。在StarGAN中,加入一个Mask向量
m
m
m的概念,用来忽略那些未知的分类,仅关注于自身了解的分类。最终的分类标签向量如下所示,其中
c
i
c_i
ci用来表示第
i
i
i个数据库的分类信息。

在训练的过程中,会将上式中的
c
~
\widetilde c
c
直接输入生成器作为条件信息,由于Mask向量的存在,那些无关的分类标签向量会变成零向量,生成器会自动忽略。另一方面在多任务的训练中,判别器也仅会对自己了解的分类进行判别。


StarGAN的应用实践


总结
四周年图像到图像的生成对抗网络:
- iGAN是第一个交互式的图像到图像的生成模型,可以通过用户的图形输入来产生合理的图像输出。
- Pix2Pix是基于匹配数据的图像到图像转换模型,根据匹配数据的训练可以在新图像上做相同的转换。
- CycleGAN的功能与Pix2Pix类似,但它的训练数据是无匹配的两个不同领域数据集,通过CycleGAN的训练方式可以让图像在两个领域之间进行转换。
- StarGAN是一种多领域的图像转换模型,在不增加网络复杂的前提下实现了各种类型图像的互转。图像到图像的生成可以应用于各种领域。
GAN的应用:从多媒体到艺术设计
GAN在多媒体领域的应用
生成对抗网络技术源于Ian在图像生成邻域的探索,所以GAN的大部分研究最先都是基于多媒体领域。
图像去模糊
DCGAN可以用来补全图像,对于部分镂空和随机镂空的情况都可以做到比较完美的补全。SRGAN可以将模图片通过生成对抗网络还原成高清图片,即所谓的超像素。由于硬件成本都比较高,通过次项技术可以在不升级原有硬件的情况下提高成像效果。
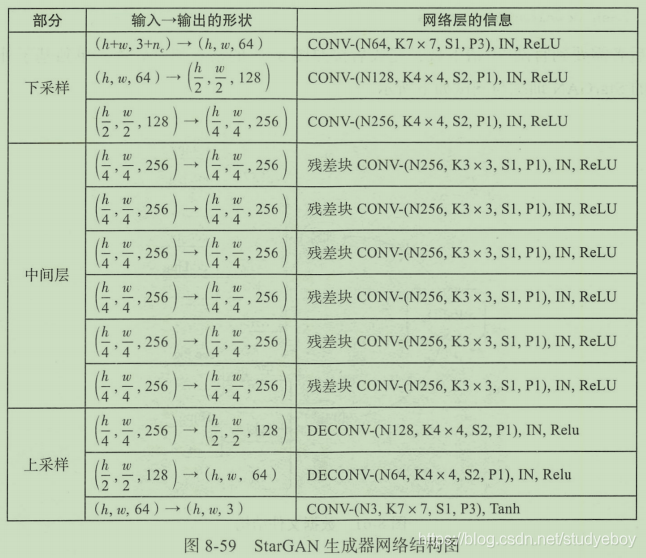
一个与补全图像和超像素非常类似的应用实例是图片去模糊(DeblurGAN)。DeblurGAN生成器网络结构如下图所示,包含2个步长为0.5的卷积模块、9个残差模块和2个转置卷积模块。其中每个残差模块包含一个卷积层、一个实例归一化层和ReLU激活函数。这里的9个残差模块是DeblurGAN用来对模糊照片进行上采样的核心模块。
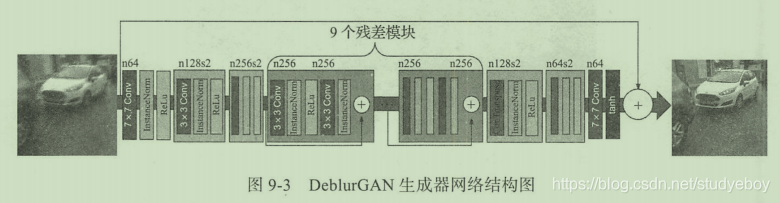
下图展示DeblurGAN训练过程的框架图,目标函数中包含两种损失函数,第一种是感知损失(perceptual loss)。 第二种是对抗损失(使用的是WGAN loss)。感知损失用于判断该生成对抗网络是否是在还原原始图像,而对抗损则失判断能否生成真实图像。从成像方面加以区分的话,前者专注在图像内容上,而后者则专注于还原图像的细节部分。
经过多次测试验证,DeblurGAN在模糊图像还原的任务中可以非常高效的完成修复任务,并且比传统的深度学习方法加速好几倍。
DeblurGAN
人脸生成
GAN目前有非常多在人脸生成方向上的应用。2018年的DeepFake,核心功能非常简单,就是将视频或图片中的人脸进行互换。最初版本的DeepFake使用的是自动编码的技术,后来网络上有了基于GAN的改进版本faceswap-GAN。下图为faceswap-GAN的训练阶段与测试阶段的示意图,在训练过程中需要大量的人脸A数据,通过算法将其进行扭曲处理变得与人脸A不同,再通过自动编码器生成遮罩于重建的人脸,最终通过遮罩信息与之前输入的信息还原人脸A的数据。在测试过程中,网络会将人脸B的信息认为是训练集中扭曲过的训练集人脸,经过同样的步骤将其还原为人脸A的状态。
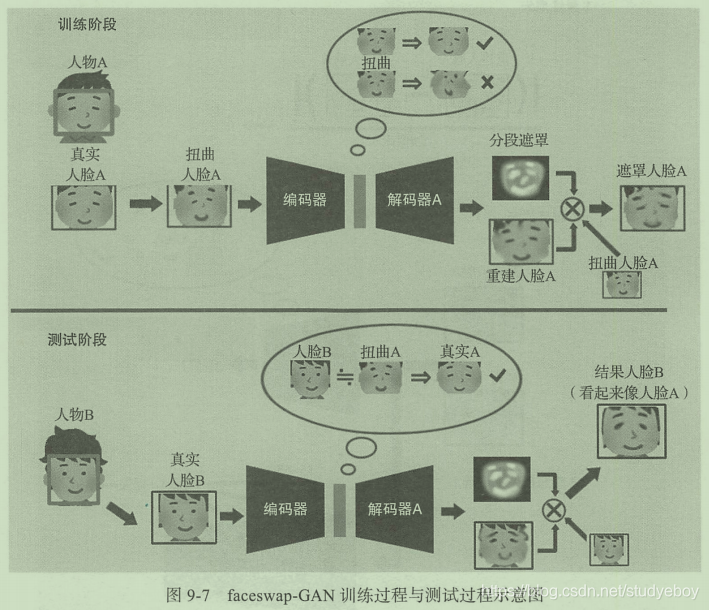
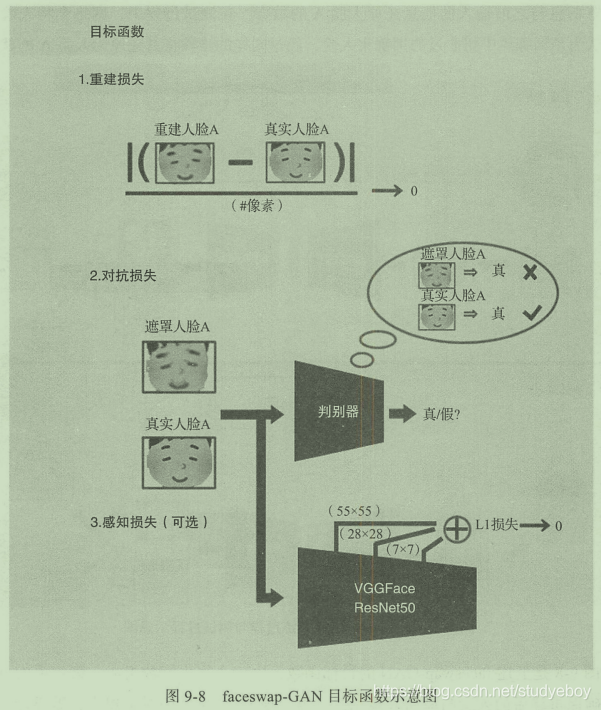
faceswap-GAN的目标函数由三个损失函数组成。第一项为重建损失,确保重建后的人脸与原始人脸相似。第二项WieGAN中的对抗损失,需要计算机判断输出的人脸是真实的还是生成的。最后一项为可选项,是人脸数据的感知损失,用于判断原图像与生成图像的整体相似度。
音频合成
WaveGAN和SpecGAN是将GAN应用在音频合成上的尝试。
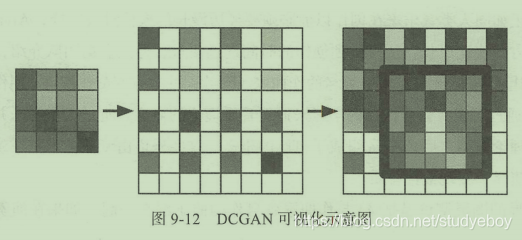
为了将GAN应用到音频领域,一个最直观的做法就是把音频信息也当作图像进行处理。下图是将图像数据和音频数据的可视化比较,左图Wie从图像数据中随机取出的5x5像素,可以发现图像数据的特点是边缘比较显著,右图为截取的长度为25的音频可视化数据,它的特点在于具备很强的周期性。

WaveGAN与SpecGAN的差别在于,WaveGAN对音频采用时间的处理方法,SpecGAN使用的是频域处理。
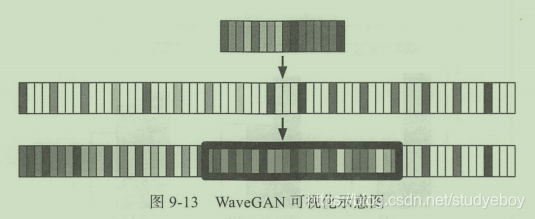
WaveGAN的整体架构是基于DCGAN进行的改进。根据音频数据的特性,将DCGAN中5x5的二维过滤器替换为长为25的一维过滤器,上采样也从2变成了4。同样对于判别器也需要做出相应的修改。下图是图像数据使用DCGAN和音频数据使用WaveGAN的可视化比较。
GAN与AI艺术
AI能否创造艺术
AI技术可以为艺术行业带来全新的面貌。首先,它y一定会创造全新的艺术形态,给艺术家提供更多的机会。其次,AI技术会对传统的艺术形态进行加强,让原来的艺术形式焕发出全新的活力。
AI与计算机艺术的发展
- 程序化生成艺术
- DeepDream:AI的艺术梦境
- 艺术风格转换
艺术生成网络:从艺术模仿到创意生成
-
GAN的艺术模仿
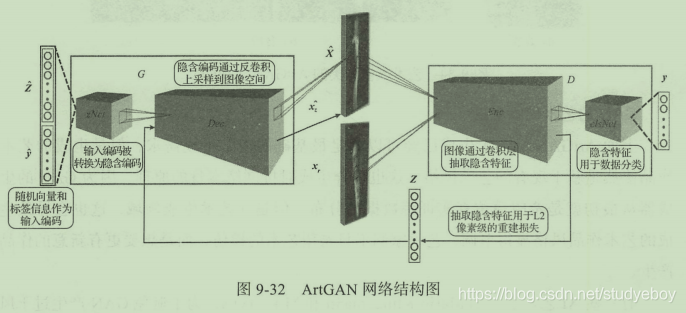
ArtGAN是一种基于DCGAN在艺术生成上进行改进的生成对抗网络,它借鉴了cGAN的思想,将各种艺术类型、艺术风格、艺术创作者作为训练集的标签,通过这些艺术标签可以更好的控制艺术生成的风格。ArtGAN的框架基本与cGAN类似,将分类信息分别提供给生成器与判别器,此外在生成器中的解码器与判别器中的编码器器之间会建立一个重建损失,确保真实艺术作品集在训练中能够很好的被生成器还原。
-
GAN的艺术创意生成
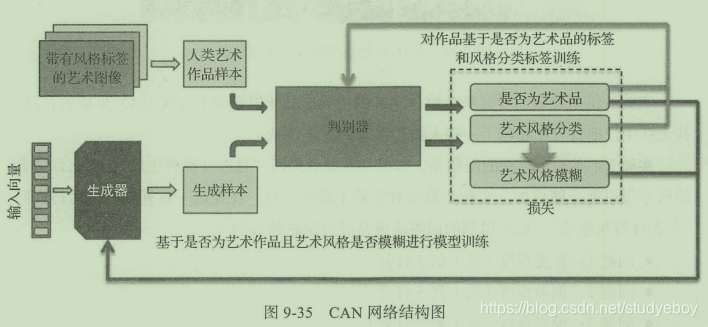
2017年Facebook提出了一种创造性对抗网络(Creative Adversarial Network,CAN),目标是能够自主的生成能够被大众接受的艺术作品,但是希望生成的艺术作品能够与现有的作品具备一定的区分度,而不是简单的复刻现有的风格。
CAN希望生成的艺术作品可以符合以下三点: -
能够生成具有创新性的艺术作品。
-
但不能过于创新以至于无法被大众接受。
-
艺术风格要有新意,尽量能与现有的风格有所区分。
CAN中包含了一个艺术判别器,用于判断作品是否属于艺术范畴,同时还有一个使用艺术风格作为分类信息的分类器,但是与ArtGAN截然不同的是,CAN的目标是要让生成的作品在被判断为艺术作品的前提下,艺术风格越模糊越好,即CAN在生成的作品被判断为艺术品的同时,能够然艺术风格的分类器对它无从下手。
CAN的网络结构如下图所示,真实的人类艺术作品和生成器作品同时输入到判别器中进行对抗训练,判断是否属于艺术范畴的判别器会像普通的GAN一样进行训练,而艺术风格分类器则作为创意生成的核心,判断作品是不是会很好的被分类到一个固定的艺术风格中。最终我们需要训练的创意生成器需要具备能够“骗过”艺术品判别器,但是难以被艺术风格分类器很好的归于某一类的能力。
GAN与AI设计
AI时代的设计
AI艺术在一定程度上是利用了随机性来完成艺术创作,AI设计则是要在随机性中实现特定的目标。设计的过程是发现问题并解决问题,在一定程度上对AI的能力要求更高了。
建筑邻域已经在使用计算机进行参数化设计了,所谓参数化设计是指将设计要素全部数值化,通过 算法的修改和数值的变化来生成不同的设计方案。目前大部分计算机辅助设计通常都是基于设计师的强规则,可以将其称为自动化设计,而AI时代的设计则是数据驱动型的,往往需要基于大量的设计素材以及用户数据来生成最恰当的设计。
作为AI设计的一个标志性产品,‘鹿班’把自己的目标定位在广告横幅上,这也是设计领域需求量最大但是时效性最低的内容,需要设计师进行大量创造性较低的重复性工作。2017年,‘鹿班’进一步升级,在内部增加了配色设计、风格设计、构图设计等,使得AI生成的广告设计更像是人类设计师的作品,AI射进的广告设计更像是融合了“美学”和“商业”两种属性。
在Logo和品牌制作方向上,Logojoy的logo和品牌设计系统,用户只需要输入品牌名称标语以及一些个人偏好的属性,系统就会自动输出专属于该用户的logo和品牌设计。虽然AI自动生成的logo可能还不够精美,但是对于射进是前期的灵感获取已经非常有帮助了,此外当设计师面对客户 时候可以使用该工具以确定客户企业的喜好,进行更精细化的作品设计。
在设计配色方面,Khroma的AI配色平台,会根据设计师的偏好提供最适合的配色方案选项,随着设计师的使用,它也会智能的学习出专属于每一个设计师的配色风格。
事实上目前的AI设计依然是作为设计师的辅助工具,帮助设计师提高获取灵感的效率、降低重复性设计工作的时间。
设计需要创造力和感情,恰好应该在智能时代扮演更重要的链接人工智能和人性的角色。因此,设计与人工智能的关系远远要比工作取代关系深入和复杂。——《设计和人工智能报告》
AI辅助式设计的研究
- 草图生成
SketchRNN是谷歌公司提出的一种草图生成工具,它可以在用户画了简单几笔之后,自动为用户补全他的想法。
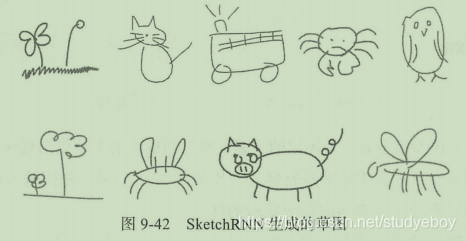
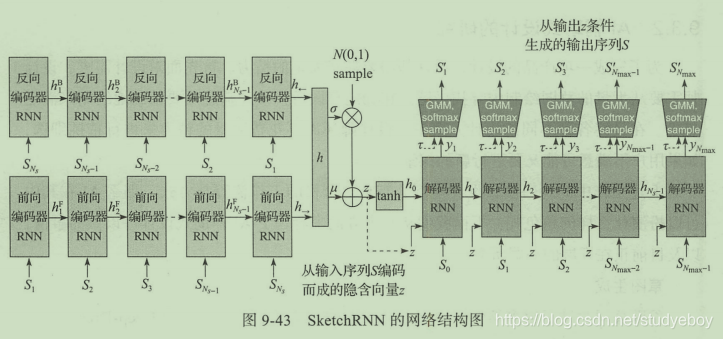
SketchRNN不仅收集了大量手绘图的终稿,而且将用户手绘过程中的一笔一划全部记录下来用作训练。它不仅是让计算机学会如何输出草图风格的图片,而且让计算机真正取学习如何作画。SketchRNN的网络结构是一个序列到序列的差分自动编码器架构,其中,编码器时一个双向的RNN,解码器是一个自回归RNN。
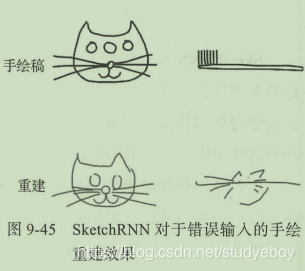
假设我们设置的模型是猫,那么对于用户输入的草图手绘,SketchRNN并不是直接还原用户手绘的原样,而是将用户输入的内容作为条件信息并利用模型自身学习到的内容对猫进行重绘,重建后的草图与原图十分神似但也并非一模一样。


- 交互式图像生成
TextureGAN是Adobe公司联合美国乔治亚理工学院的一项关于不同材质服饰的生成模型研究,该模型可以实现在现有服饰手绘草图稿的基础上添加相应的材质贴片,自动生成基于该材质的最终设计效果图。

- 探索生成模型的隐含空间
生成模型中的隐含空间提供了某种可能,隐含空间实际上是对生成空间的降维,通过对低维度隐含空间的探索,我们可以发现更多的设计可能性。- DCGAN卧室设计图生成,通过在隐含空间中插值的方式来查看不同我是设计风格之间的过渡,普通用户也可以在没有室内设计师的帮助下探索自己心仪的效果。
- SketchRNN可以使用插值来进行手绘草图的探索。用户输入一个猫脸和一个猫的的全身草图,通过内部插值可以生成中间一系列过渡的草图,最中间一幅是一个完整的猫的图画。
- TopoSketch提出了静态图片生成动态视频的方案。通过在隐含空间中插值的方式我们可以得到这些图片中间的过渡图像。由于在隐含空间中距离较近的点在生成空间中也应该保持较近的距离,所以相邻点之间表情变化不会非常大, 这也使得最终输出的图像序列是连贯的。
GAN研究热点
评估与优化
在GAN的优化方向上,对于生成模型的评估指标一直是行业的重要研究领域,对于生成效果的评估最直观的方法就是人眼检测,因为人具备天生的判断能力,可以很好的判断一张图片是不是计算机生成的,而对于生成艺术这类抽象的判断方法,似乎用人的判断才是最合适的选择。
依靠人来判断存在的问题:
- 人力资源是有限的,而生成图像却是源源不断,如果所有的生成内容都需要人来做评价,则成本过高。
- 对于图像类的数据,人每看一张可能就需要花费几秒钟,对于海量数据来说这是不现实的。
- 人为的操作不免会导致失误。
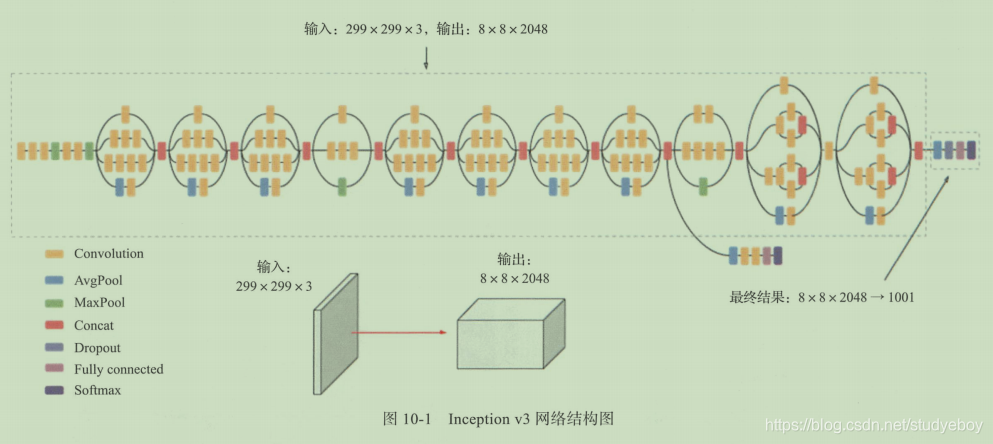
Ian Goodfellow在对GAN进行优化的时候提出评估方法是Inception Score。它是基于Inception v3神经网络模型对于生成图像质量的评估指标,他从以下两个指标来进行评价:
- 生成的图像是否包含清晰的内容,从分类角度来讲就是该图像是否能够被高概率的判断为某一个类别。
- 生成模型需要保证多样性,所以希望模型生成的图像能够尽量多的覆盖所有的分类。
基于上述两种特性可以通过下面的式子来计算出Inception Score的得分,其中
D
K
L
D_KL
DKL为KL散度,
p
(
y
∣
x
)
p(y|x)
p(y∣x)为特定输入分类的概率,
p
(
y
)
p(y)
p(y)为整体分类的概率。
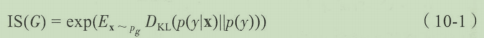
FID(Frechet Inception Distance) Score,该方法将生成的图像嵌入Inception Net的一个特定层给出的特征空间中,将该空间视为连续的多元高斯分布,对生成数据和实际数据的均值和协方差进行计算。
GAN优化的另一个方向是针对GAN经常出现的泛化性问题和模式崩溃问题的优化,其本质是对生成多样性的一种优化方向。
泛化性问题的本质是生成模型并没有从有限的训练集中学会如何生成数据,而是“死记硬背”的记住了一部分训练数据,在生成的时候只是单纯的重复输出训练集中已有的数据。
模式崩溃问题:
- 彻底的模式崩溃,当训练到一定程度后,生成器开始不停的重复类似的数据,进入模式崩溃状态。
- 模式消失(missing mode ),该情况是比较棘手也难以发现,在这种情况下生成模型看似具备多样性,但其实只会生成一部分类型的数据,很容易“骗过”人的判断。
对抗攻击
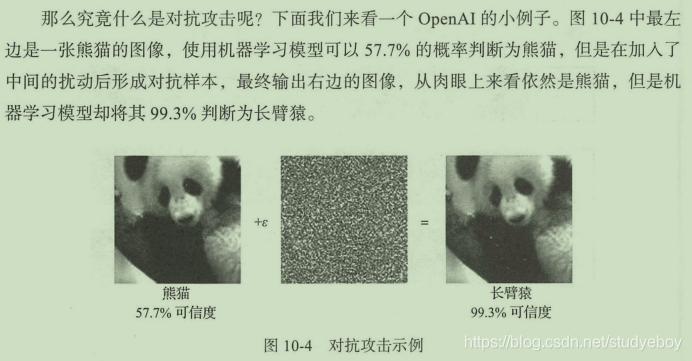

事实上深度神经网络非常容易受“欺骗”,对抗示例中毫无意义的图片会被卷积神经网络以很高额概率分类到某个类型。想要做到这样的一种“欺骗”效果其实并不难,在神经网络训练过程中不断更新大量的神经元参数来满足训练结果,而对于对抗攻击者来说只需要在网络参数不变的情况下不断更新输入图像的像素,就可以逐渐逼近对抗样本所期望的效果。
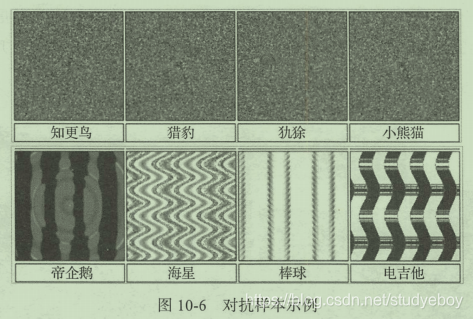
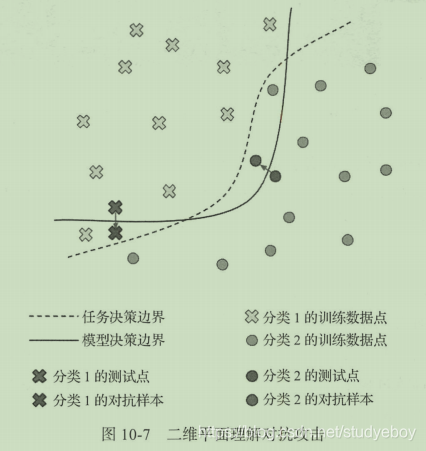
通过二维平面示意图中的二分类任务理解这种对抗攻击的方式。其中虚线是该二分类任务的实际边界,而实线是基于训练数据得到的模型分界线,对抗攻击者通过逐步将训练集中的数据移动到虚线与实线之间的错判区域中就可王城一次对抗攻击。
在生成对抗网络中,生成器其实就扮演了一个对抗攻击者的角色,而判别器则需要有很强的鲁棒性,这样才能应对生成器的假数据。对抗式训练是目前应对对抗攻击的一种方法,与传统生成对抗网络训练生成模型目的不同,对抗模式训练是为了获得一个高强度的判别器,以确保未来的对抗样本不会对其造成干扰。
目前业界将对抗攻击的防御方法大致分为三种类型:
- 修改训练的方式和输入数据,比如对数据加入一些随机性或是使用对抗式训练的方法。
- 修改网络,如防御式提炼,证明可以抵抗小幅度的扰动。
- 使用附加网络来联合抵抗对抗攻击。

















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









