







python爬取《完美世界》小说
文章目录
下载requests,beautifulsoup4和html5lib包
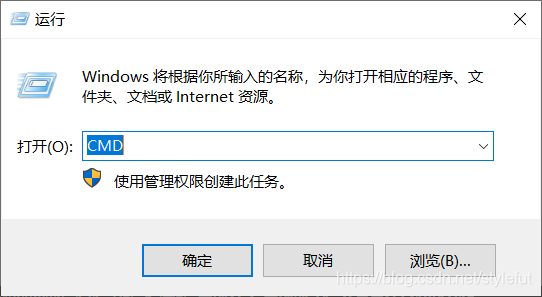
win+R 打开cmd 输入pip install requests, pip install beautifulsoup4,pip install html5lib

运行python
导入库
import requests
from bs4 import BeautifulSoup
用谷歌浏览器搜索小说网,搜索《完美世界》,复制链接该https://www.xbiquge.la/8/8345/
url地址
url="https://www.xbiquge.la/8/8345/"
发送请求
respon=requests.get(url)
使用requests.get()给url 地址发送请求
使用bs4和html5lib解析网页
bs=BeautifulSoup(respon.content,"html5lib")
respon.content获取响应的源内容(二进制内容)
先右键,然后点击检查可获取源内容
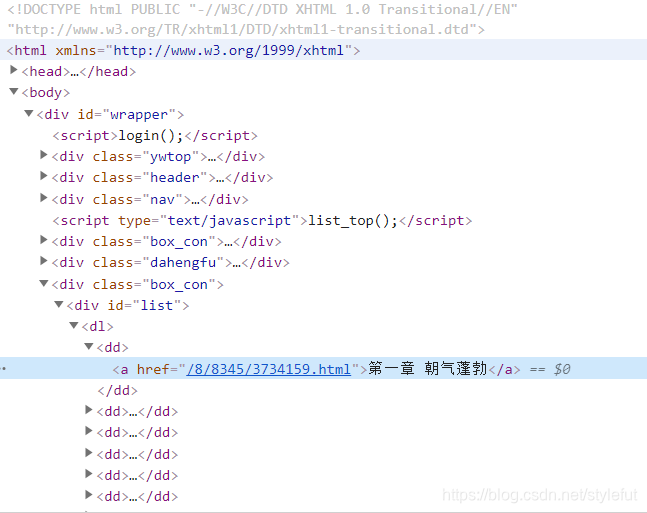
获取id=list的内容
divs=bs.find("div",attrs={"id":"list"})
所有的章数的超链接都在<div id=“list”>里面,所以通过find查找,找到<div id=“list”>里面的了内容
获取超链接
aList=divs.find_all("a")
在aList(列表)的基础上,在<div id=“list”>里面获得<a href=“超链接”></a>
使用循环给每个超链接发送请求,并进行正文下载
for i in aList:
a = True
while a:
title = i.text# 获取a标签的内容
href = i.get("href")#获取a标签href的值
urlChild = "https://www.xbiquge.la" + href#建立新的超链接
responses = requests.get(urlChild) #发送请求
if (responses.status_code)==200:#检验网站的状态码,为200则响应成功
a=False
bs1 = BeautifulSoup(responses.content, "html5lib")#bs4和html5lib解析网页
divs1 = bs1.find("div", attrs={"id": "content"})#获取id=content的内容
text=divs1.text# 获取a标签的内容
text=text.replace("\n\n","\n")#去掉空行
with open("{}/{}.txt".format(deco,title),"w",encoding="utf-8") as files:
files.write(title+"\n"+text)#用utf-8的格式写入txt
print(title+"下载成功")
else:#如果网页响应失败,则重新进行响应
print(title+"下载失败,重新下载")














 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









