









问题的提出
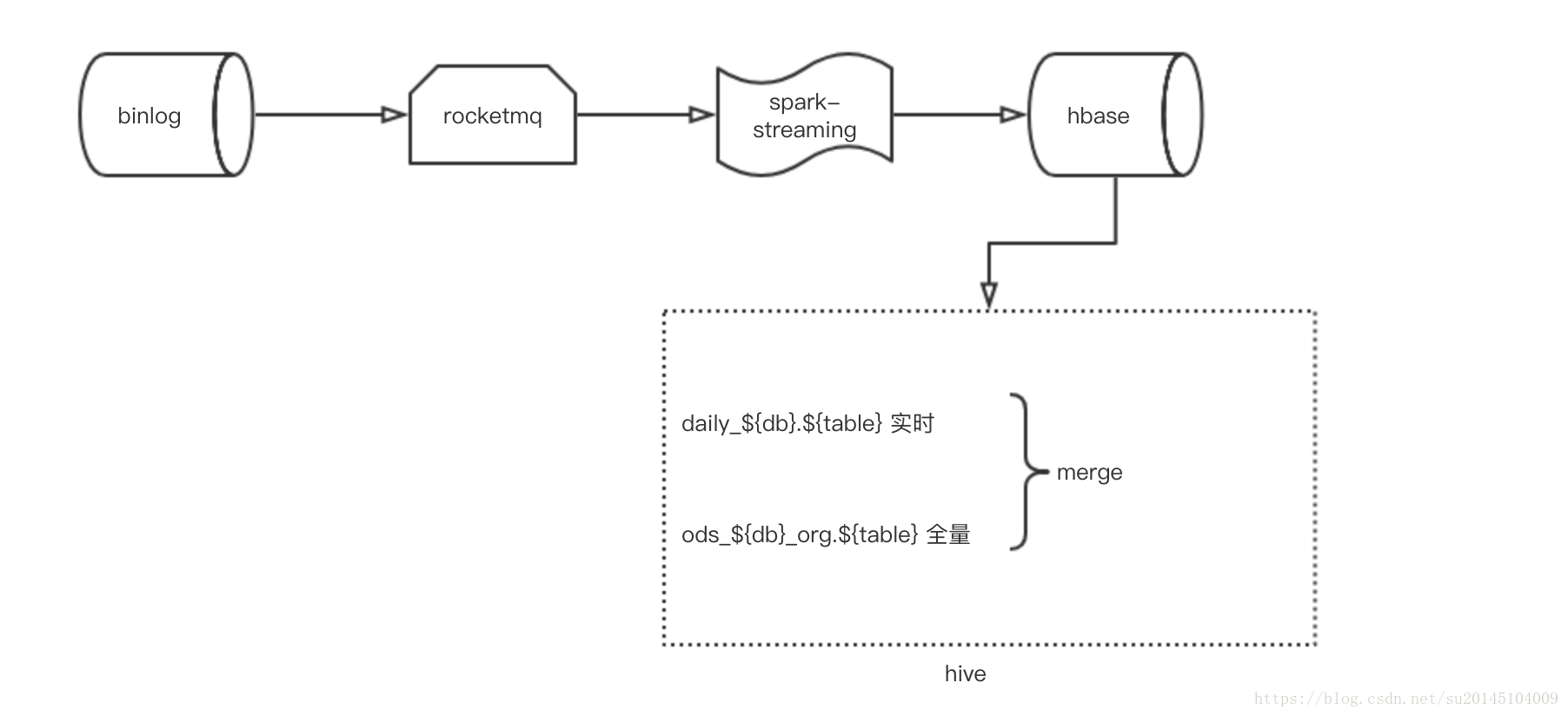
基于hbase的实时架构图如上图所示(也有其它基于TiDB的毫秒级别的实时,这里属于伪实时H+1)。
目前报表的H+1任务的数据都是通过读取binlog消息存入导hbase的。在对这些数据做计算需要在hive上,此时也就需要把数据从hbase导入hive中。最后通过一系列计算把结果export到指定数据库.
在hbase->hive的过程中使用的方法为:现在的实现方法为:在hive上建立hbase的映射表A,然后在zeus中创建一个每小时一次的定时任务,使用map-reduce读取表A数据到实时库表B供分析师使用。
现在的问题是:由于在hive中创建的hbase的映射表,底层使用的hbase的scan,数据的读取速度很慢 例如:instancedetail每次都会耗时近20分钟,这时候尝试使用一种新的工具来实现数据hbase->hive。
探索
发现了阿里巴巴开源的ETL工具dataX离线数据同步工具/平台,现在对此进行测试。
测试1
为了方便测试,我在hbase中新建了一个表“scmdb:storage_detail”,生成的数据量为1984714
方式1:hive建立hbase的映射表
三次运行平均时间为:2分35S
方式2:使用DataX:直接从hbase到hive
三次运行平均时间为:2分02S
分析
方式1时间较长的原因是:启动时间较长,但是一旦启动后就很快,对百万级别的数据量不明显
方式2时间较长的原因是:单机多线程 ,带宽限制 线下机器最大只能达到9m/s
测试2
为了解开上面的疑惑,使用生产环境的机器,较大数据量进行测试
instance_bill 表数据量:18588501
方式1:

耗时:204s
考虑到这是在晚上集群资源紧张时执行的时间,所以又在集群空闲时手动执行

耗时:84S
方式2
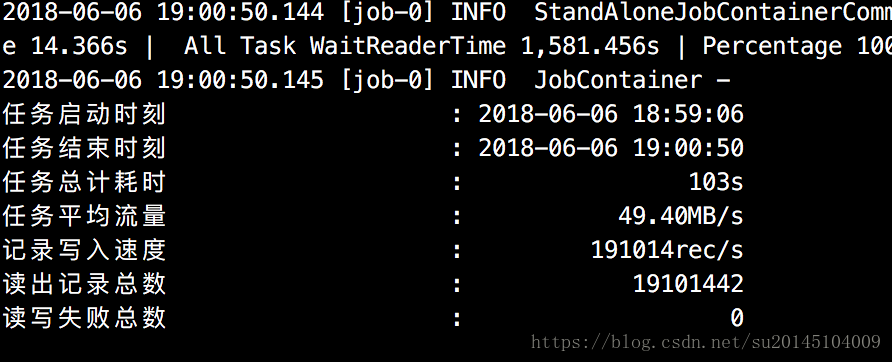
耗时:103S
经测试,对于方式2此时再增加并发数和带宽效率已无提升。
结论
在资源忙碌和空闲时,dataX的时间变化很少。带宽成为dataX的提升瓶颈。开源的部分只是阿里巴巴的单机模式,分布式并未开源。map-reduce耗时在资源充足时耗时少。但是实时的数据通常为三天的数据,数据量都是上千万,dataX单机版耗时仍会超出map-reduce的时间。还需要继续探索
其它方式
表优化
所以现在的优化还是要从union ods全量表入手,只要把union的这部分砍掉,相信时间会提升一倍甚至以上。
至于为何需要union ods全量表,原因在于:某些binlog消息消费失败,某些binlog消息未解析成功。经过日志查看,binlog消息消费失败几乎已经不存在,所以可以去掉。
目前优化的思路:
先把H+1使用的ods昨天数据在导表结束后提取出来,供白天的H+1使用。然后再慢慢的去掉这部分。
hbase性能优化
消息写入hbase时会出现偶尔的低峰。
垃圾回收优化
“-Xmx 8g -Xms8g -Xmn128m -XX:+UseParNewGC -XX:UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+printGCDetails -XX:+printGCTimeStamps Xloggc:HBASE_HOME/logs/gc-home-hbase.log”使用memstore缓存
hbase.hregion.memstore.mslab.enabled
hbase.hregion.memstore.mslab.chunksize
hbase.hregion.memstore.mslab.max.allocation使用压缩
目前生产环境hbase中仍存在一些大表没有启用压缩,强烈建议使用压缩。因为cpu压缩和解压消耗的时间比从磁盘中读取和写入更多数据消耗的时间更短。管理拆分
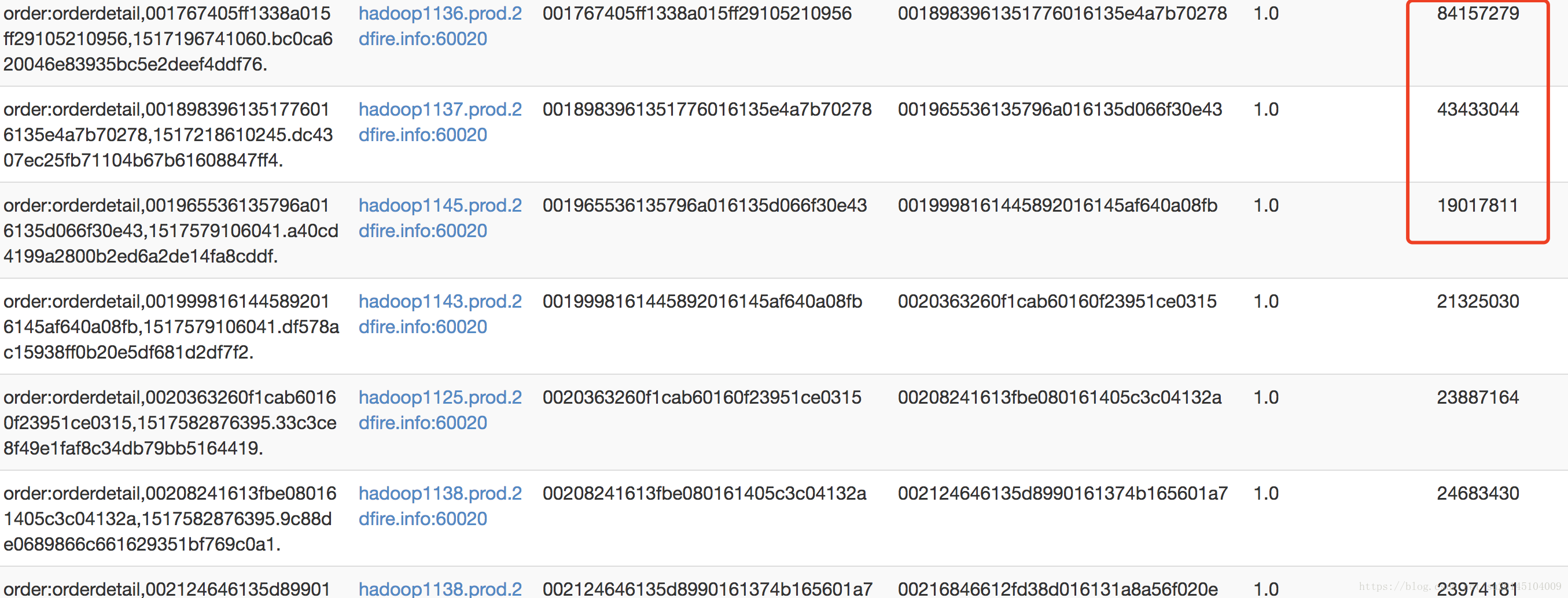
region热点
可以明显的看到region自动拆分造成了严重的region热点问题,一个region又8千万的请求,另外一个region只有2千万的请求。所以,尽量预拆分或者手动拆分。
api优化
禁止自动刷写
使用扫描缓存
hbase.scan.cache 默认值为1,意味着map任务会在处理每条记录都请求region服务器。调大可以减少RPC次数,但是会消耗更多内存缓存数据,适当调整。- 限定扫描范围
配置优化
减少zookeeper超时的发生:zookeeper.session.timeout
这个时间动态设定,默认时间三分钟,如果设置的较短,虽然master能够及时发现崩溃现象,但是如果你的jvm堆内存设置的较大,那么fullgc的时间就会很长,此时可能会被zookeeper误认为崩溃。增加处理线程:hbase.regionserver.handler.count
默认值为10。如果单次请求访问的数据量达到MB级别,那么建议设置较小。如果单次请求开销较小,那么建议设置的稍微大一点,增加并发量。增加堆大小
hbase默认的配置适合大部分机器,如果机器性能较好,默认的master配置只有1G,可以适当增大。并且regionserver也可以设置增大。增加region大小
region数量较少,易于master的管理,大的region也意味着高负载情况下合并停顿时间更长,适当调整。- 调整块缓存大小
块缓存(默认20%)和memstore(默认40%)两个加在一起最好低于60%。如果读请求较多块缓存适当设置大一点,如果写请求多memstore适当设置大一点。 - 调整memstore限制














 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









