







最近开始详细研究scheduler中的RT调度器,其中有看到一个cpupri,作为选核的一部分,有必要先研究一下这个。
Summary:
为了方便描述:做如下的概念约定:
把一个cpu中正在排队以及正在running的所有rt task最高的优先级叫做此cpu的优先级。
根据这个优先级可以对CPU进行排序。
对于RT调度器来讲,其重要任务是保证优先级高的task优先执行,优先级高的task的响应时间也要最快。
假定一个task上面已经有比较高优先级的Task在排队或者run的话,这时候再摆上去一个优先级比较低的task,那么这个task 就会排队,造成runnable,即便是其他cpu上面所有task的优先级都比这个task还低。这样显然不合理。
而cpupri则负责跟踪记录各个cpu中所有task的最高优先级情况。方便后面寻找优先级最低的cpu出来,供RT调度器进行选择。
代码分析
其位于:
kernel/sched/cpupri.h,内容如下所示。
/* SPDX-License-Identifier: GPL-2.0 */
#define CPUPRI_NR_PRIORITIES (MAX_RT_PRIO + 2)
#define CPUPRI_INVALID -1
#define CPUPRI_IDLE 0
#define CPUPRI_NORMAL 1
/* values 2-101 are RT priorities 0-99 */
struct cpupri_vec {
atomic_t count;
cpumask_var_t mask;
};
struct cpupri {
struct cpupri_vec pri_to_cpu[CPUPRI_NR_PRIORITIES];//有多少个RT优先级就有多少个元素。每个元素记录吧这个优先级分别是哪些个cpu的最高优先级。所以理论上讲最多只有8个元素是有值的,假定有8个cpu的话。
int *cpu_to_pri;//一个有多少个cpu就有多少个元素的数组。每个元素代表对应cpu中当前最高优先级的值。
};
#ifdef CONFIG_SMP
int cpupri_find(struct cpupri *cp, struct task_struct *p, struct cpumask *lowest_mask);
void cpupri_set(struct cpupri *cp, int cpu, int pri);
int cpupri_init(struct cpupri *cp);
void cpupri_cleanup(struct cpupri *cp);
#endif
- 使用cpupri的地方
如下所示在root_domain中定义了一个结构体对象。所以看上去属于全局变量。
/*
* We add the notion of a root-domain which will be used to define per-domain
* variables. Each exclusive cpuset essentially defines an island domain by
* fully partitioning the member CPUs from any other cpuset. Whenever a new
* exclusive cpuset is created, we also create and attach a new root-domain
* object.
*
*/
struct root_domain {
………………………………
/*
* The "RT overload" flag: it gets set if a CPU has more than
* one runnable RT task.
*/
cpumask_var_t rto_mask;
struct cpupri cpupri;
unsigned long max_cpu_capacity;
……………………
};
在init_rootdomain函数中对其进行了初始化。
static int init_rootdomain(struct root_domain *rd)
{
if (!zalloc_cpumask_var(&rd->span, GFP_KERNEL))
goto out;
if (!zalloc_cpumask_var(&rd->online, GFP_KERNEL))
goto free_span;
if (!zalloc_cpumask_var(&rd->dlo_mask, GFP_KERNEL))
goto free_online;
if (!zalloc_cpumask_var(&rd->rto_mask, GFP_KERNEL))
goto free_dlo_mask;
#ifdef HAVE_RT_PUSH_IPI
rd->rto_cpu = -1;
raw_spin_lock_init(&rd->rto_lock);
init_irq_work(&rd->rto_push_work, rto_push_irq_work_func);
#endif
init_dl_bw(&rd->dl_bw);
if (cpudl_init(&rd->cpudl) != 0)
goto free_rto_mask;
if (cpupri_init(&rd->cpupri) != 0)
goto free_cpudl;
return 0;
free_cpudl:
cpudl_cleanup(&rd->cpudl);
free_rto_mask:
free_cpumask_var(rd->rto_mask);
free_dlo_mask:
free_cpumask_var(rd->dlo_mask);
free_online:
free_cpumask_var(rd->online);
free_span:
free_cpumask_var(rd->span);
out:
return -ENOMEM;
}
/**
* cpupri_init - initialize the cpupri structure
* @cp: The cpupri context
*
* Return: -ENOMEM on memory allocation failure.
*/
int cpupri_init(struct cpupri *cp)
{
int i;
for (i = 0; i < CPUPRI_NR_PRIORITIES; i++) {
struct cpupri_vec *vec = &cp->pri_to_cpu[i];//如前面pri_to_cpu定义所示,每一个优先级都对应一个cpupri_vec.
atomic_set(&vec->count, 0);//设置计数器为0
if (!zalloc_cpumask_var(&vec->mask, GFP_KERNEL))
goto cleanup;
}
cp->cpu_to_pri = kcalloc(nr_cpu_ids, sizeof(int), GFP_KERNEL);//cpu_to_pri数组,其元素数量为cpu的数量。
if (!cp->cpu_to_pri)
goto cleanup;
for_each_possible_cpu(i)
cp->cpu_to_pri[i] = CPUPRI_INVALID;
return 0;
cleanup:
for (i--; i >= 0; i--)
free_cpumask_var(cp->pri_to_cpu[i].mask);
return -ENOMEM;
}
rq,rd,cpupri关系如下图所示:
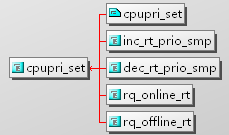
对cpupri对象的修改主要通过cpupri_set完成,调用的地方如下所示:
/**
* cpupri_set - update the CPU priority setting
* @cp: The cpupri context
* @cpu: The target CPU
* @newpri: The priority (INVALID-RT99) to assign to this CPU
*
* Note: Assumes cpu_rq(cpu)->lock is locked
*
* Returns: (void)
*/
void cpupri_set(struct cpupri *cp, int cpu, int newpri)
{
int *currpri = &cp->cpu_to_pri[cpu];
int oldpri = *currpri;
int do_mb = 0;
newpri = convert_prio(newpri);
BUG_ON(newpri >= CPUPRI_NR_PRIORITIES);
if (newpri == oldpri)
return;
/*
* If the CPU was currently mapped to a different value, we
* need to map it to the new value then remove the old value.
* Note, we must add the new value first, otherwise we risk the
* cpu being missed by the priority loop in cpupri_find.
*/
/*
*如上面的注释所示,先设定新priority的cpupri_vec
*/
if (likely(newpri != CPUPRI_INVALID)) {
struct cpupri_vec *vec = &cp->pri_to_cpu[newpri];
cpumask_set_cpu(cpu, vec->mask);//设定其mask,表明对应的cpu上面有Priority的task。
/*
* When adding a new vector, we update the mask first,
* do a write memory barrier, and then update the count, to
* make sure the vector is visible when count is set.
*/
smp_mb__before_atomic();
atomic_inc(&(vec)->count);
do_mb = 1;
}
if (likely(oldpri != CPUPRI_INVALID)) {
struct cpupri_vec *vec = &cp->pri_to_cpu[oldpri];
/*
* Because the order of modification of the vec->count
* is important, we must make sure that the update
* of the new prio is seen before we decrement the
* old prio. This makes sure that the loop sees
* one or the other when we raise the priority of
* the run queue. We don't care about when we lower the
* priority, as that will trigger an rt pull anyway.
*
* We only need to do a memory barrier if we updated
* the new priority vec.
*/
if (do_mb)
smp_mb__after_atomic();
/*
* When removing from the vector, we decrement the counter first
* do a memory barrier and then clear the mask.
*/
atomic_dec(&(vec)->count);
smp_mb__after_atomic();
cpumask_clear_cpu(cpu, vec->mask);
}
*currpri = newpri;
}其完整的调用关系如下图所示:

所以可以看到基本上是在enqueu/dequeu entity的时候更新cpupri的值。主要沿着enqueue_entiry这条路径看以下:
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, unsigned int flags)
{
struct rt_rq *rt_rq = rt_rq_of_se(rt_se);
struct rt_prio_array *array = &rt_rq->active;
struct rt_rq *group_rq = group_rt_rq(rt_se);
struct list_head *queue = array->queue + rt_se_prio(rt_se);
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running)) {
if (rt_se->on_list)
__delist_rt_entity(rt_se, array);
return;
}
if (move_entity(flags)) {
WARN_ON_ONCE(rt_se->on_list);
if (flags & ENQUEUE_HEAD)
list_add(&rt_se->run_list, queue);
else
list_add_tail(&rt_se->run_list, queue);
__set_bit(rt_se_prio(rt_se), array->bitmap);
rt_se->on_list = 1;
}
rt_se->on_rq = 1;
/*前面完成task的入队动作之后,开始更新队列的最高优先级。*/
inc_rt_tasks(rt_se, rt_rq);
}
static inline
void inc_rt_tasks(struct sched_rt_entity *rt_se, struct rt_rq *rt_rq)
{
int prio = rt_se_prio(rt_se);
WARN_ON(!rt_prio(prio));
//记录了rt entity的数量
rt_rq->rt_nr_running += rt_se_nr_running(rt_se);
rt_rq->rr_nr_running += rt_se_rr_nr_running(rt_se);
//如下更新rt queue中最高优先级
inc_rt_prio(rt_rq, prio);
inc_rt_migration(rt_se, rt_rq);
inc_rt_group(rt_se, rt_rq);
}
static void
inc_rt_prio(struct rt_rq *rt_rq, int prio)
{
int prev_prio = rt_rq->highest_prio.curr;
if (prio < prev_prio)
rt_rq->highest_prio.curr = prio; //所以higest_pri.curr记录了当前队列中优先级最高的priority.由于rt qeueue当中,task是按优先级放人,相同优先级的task在同一个qeueue当中。所以可以认为,rt的queue是一个二维数组,横向的表示相同的优先级的task,纵向的表示按照优先级排序。
//上面的代码并只判断prio 小于prev_prio的情况,并没有考虑大于等于的情况,难道是说,无论如何都回去更新么?那这就不是记录最高优先级了,而是记录最近入队的优先级了。其实在inc_rt_prio_smp函数中有去判断的。
inc_rt_prio_smp(rt_rq, prio, prev_prio);
}
static void
inc_rt_prio_smp(struct rt_rq *rt_rq, int prio, int prev_prio)
{
struct rq *rq = rq_of_rt_rq(rt_rq);
#ifdef CONFIG_RT_GROUP_SCHED
/*
* Change rq's cpupri only if rt_rq is the top queue.
*/
if (&rq->rt != rt_rq)
return;
#endif
if (rq->online && prio < prev_prio) //这个条件保证了,只有最高优先级更新的时候才去改变cpupri的值。从而也就保证了cpupri中记录的是各cpu中优先级最高的优先级。
cpupri_set(&rq->rd->cpupri, rq->cpu, prio);
}
/* Convert between a 140 based task->prio, and our 102 based cpupri */
static int convert_prio(int prio)
{
int cpupri;
if (prio == CPUPRI_INVALID)
cpupri = CPUPRI_INVALID;
else if (prio == MAX_PRIO)
cpupri = CPUPRI_IDLE;
else if (prio >= MAX_RT_PRIO)
cpupri = CPUPRI_NORMAL;
else
cpupri = MAX_RT_PRIO - prio + 1;
return cpupri;
}
#define CPUPRI_INVALID -1
#define CPUPRI_IDLE 0
#define CPUPRI_NORMAL 1
/**
* cpupri_find - find the best (lowest-pri) CPU in the system
* @cp: The cpupri context
* @p: The task
* @lowest_mask: A mask to fill in with selected CPUs (or NULL)
*
* Note: This function returns the recommended CPUs as calculated during the
* current invocation. By the time the call returns, the CPUs may have in
* fact changed priorities any number of times. While not ideal, it is not
* an issue of correctness since the normal rebalancer logic will correct
* any discrepancies created by racing against the uncertainty of the current
* priority configuration.
*
* Return: (int)bool - CPUs were found
*/
//根据上面的英文注释,这个函数应该是找目前的cpu优先级比当前task优先级还低的cpu
int cpupri_find(struct cpupri *cp, struct task_struct *p,
struct cpumask *lowest_mask)
{
int idx = 0;
int task_pri = convert_prio(p->prio);//这个函数对于理解下面的内容是关键。这个函数将原本rt task 优先级数值越低优先级越高的顺序给反过来了,优先级越低,值越小。
BUG_ON(task_pri >= CPUPRI_NR_PRIORITIES);
for (idx = 0; idx < task_pri; idx++) {//按优先级从低到高的遍历。
struct cpupri_vec *vec = &cp->pri_to_cpu[idx];
int skip = 0;
if (!atomic_read(&(vec)->count)) //如果count等于0表示还没有一个cpu的最高优先级是这个值。
skip = 1;
/*
* When looking at the vector, we need to read the counter,
* do a memory barrier, then read the mask.
*
* Note: This is still all racey, but we can deal with it.
* Ideally, we only want to look at masks that are set.
*
* If a mask is not set, then the only thing wrong is that we
* did a little more work than necessary.
*
* If we read a zero count but the mask is set, because of the
* memory barriers, that can only happen when the highest prio
* task for a run queue has left the run queue, in which case,
* it will be followed by a pull. If the task we are processing
* fails to find a proper place to go, that pull request will
* pull this task if the run queue is running at a lower
* priority.
*/
smp_rmb();
/* Need to do the rmb for every iteration */
if (skip)
continue;
if (cpumask_any_and(p->cpus_ptr, vec->mask) >= nr_cpu_ids)
continue;
if (lowest_mask) {
cpumask_and(lowest_mask, p->cpus_ptr, vec->mask);
/*
* We have to ensure that we have at least one bit
* still set in the array, since the map could have
* been concurrently emptied between the first and
* second reads of vec->mask. If we hit this
* condition, simply act as though we never hit this
* priority level and continue on.
*/
if (cpumask_any(lowest_mask) >= nr_cpu_ids)
continue;
}
return 1; //所以只要找到一个最低优先级且满足counter不为0,就返回。
}
return 0;
}
如上面的代码所示,idle位于0元素,而normal task位于1元素,而后才是按照rt优先级排序的元素。
实际上由于只有rt调度器当中才会调用cpupri_set。所以,对于idle与normal来讲都是位于1元素位置,如下所示:
void init_rt_rq(struct rt_rq *rt_rq)
{
struct rt_prio_array *array;
int i;
array = &rt_rq->active;
for (i = 0; i < MAX_RT_PRIO; i++) {
INIT_LIST_HEAD(array->queue + i);
__clear_bit(i, array->bitmap);
}
/* delimiter for bitsearch: */
__set_bit(MAX_RT_PRIO, array->bitmap);
#if defined CONFIG_SMP
rt_rq->highest_prio.curr = MAX_RT_PRIO;
rt_rq->highest_prio.next = MAX_RT_PRIO;由于rt_rq->highest_pri.curr的初始值为MAX_RT_PRIO.所以,在rq online的时候:
此时没有rt task,因此highest_prio.curr的值为100
/* Assumes rq->lock is held */
static void rq_online_rt(struct rq *rq)
{
if (rq->rt.overloaded)
rt_set_overload(rq);
__enable_runtime(rq);
cpupri_set(&rq->rd->cpupri, rq->cpu, rq->rt.highest_prio.curr);
}
根据前面的convert_prio函数的实现,对应的是Normal值。















 3675
3675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









