







Matplotlib 绘制相关性分析结果
(一) Matplotlib 绘制柱状图
(二) Matplotlib 绘制箱线图
(三)Matplotlib 绘制相关性分析结果
Matplotlib 绘制相关性分析结果
一、 几种相关系数
1. 三种相关系数
参考文献:
1.https://mp.weixin.qq.com/s/evGkvHrdAaF6UFjySUv3Ag
相关性分析是指研究两种或者两种以上的变量之间相关关系的统计分析方法,一般分析步骤为:
1)判断变量间是否存在关联;
2)分析关联关系(线性/非线性)、关联方向(正相关/负相关)、关联数量(单相关/复相关/偏相关)和关联强度(显著相关/高度相关/中度相关/弱相关)等关联特征。
常用于度量两个或多个变量之间相关程度的指标有:

2. concordance correlation coefficient(一致性相关系数)
参考文献:
1.https://www.alexejgossmann.com/ccc/
…待续
二、 相关系数的python计算
1. Scipy计算pearson相关系数
参考文献:
1.https://blog.csdn.net/weixin_42414714/article/details/109023125
r,pvalue = scipy.stats.pearsonr(x, y)
Pearson相关系数测量两个数据集之间的线性关系。 Pearson相关系数取值在-1和+1之间,为0时表示没有相关性。 -1或+1表示存在明确的线性关系。 正相关表示,随着x的增加,y也随之增加。 负相关性表示随着x增加,y减小。
p值表示对x和y不相关(即真实总体相关系数为零)的零假设的检验。因此,样本相关系数接近零(即弱相关)将趋向于为您提供较大的p值,而系数接近1或-1(即强正/负相关性)将为您提供较小的p值。
参数:
- x:(N,) array_like,输入数组。
- y:(N,) array_like,输入数组。
返回值:
-
r:float,皮尔逊的相关系数,[-1,1]之间。
-
p-value:float,Two-tailed p-value。
注: p值越小,表示相关系数越显著,一般p值在500个样本以上时有较高的可靠性。
警告:
- PearsonRConstantInputWarning,如果输入是常量数组则引发。在这种情况下,相关系数未定义,因此返回
np.nan - PearsonRNearConstantInputWarning,如果输入为“nearly”常数则引发。数组
x被认为几乎恒定,如果norm(x-mean(x))<1e-13*abs(mean(x))。计算中的数值误差x-mean(x)在这种情况下,可能会导致r的计算不正确。
2. Scipy计算spearman相关系数
参考文献:
1.https://byteofbio.com/archives/16.html
1.https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.spearmanr.html
Pearson相关系数很简单,是用来衡量两个数据集的线性相关程度。而Spearman相关系数不关心两个数据集是否线性相关,而是单调相关,Spearman相关系数也称为等级相关或者秩相关(即rank)。两者的前提假设就不同,Pearson相关假设数据集在同一条直线上,而Spearman只要求单调递增或者递减,所以Pearson的统计效力比Spearman要高。
#简化版:
rho,pvalue = scipy.stats.spearmanr(x, y)
#原版
rho,pvalue = scipy.stats.spearmanr(a, b=None, axis=0, nan_policy='propagate', alternative='two-sided')
参数:
- a , b:array_like,b是可选的。
一个或两个包含多个变量和观测值的一维或二维数组。当这些参数是一维时,每个都代表单个变量的观测向量。有关二维的情况,请参见axis下面的描述。两个数组在axis中需要具有相同的长度。 - axis:int or None, 可选。
若 axis=0 (默认)则每列表示一个变量,观察值在行中;如果轴为=1,则关系被转置:每一行代表一个变量,而列包含观察结果。如果轴为=None,则两个数组都将被破坏。 - nan_policy:{‘propagate’, ‘raise’, ‘omit’}, 可选。
定义了当输入包含nan时如何处理,默认为‘propagate’ - alternative:{‘two-sided’, ‘less’, ‘greater’}, 可选
定义了备择假设,默认是‘two-sided’
返回值:
-
相关系数:float 或 ndarray(2D-正方形)
Spearman相关矩阵或相关系数(如果只给出2个变量作为参数。相关矩阵为平方,长度等于a和b组合中变量(列或行)的总数。 -
p-value:float,Two-tailed p-value。
注: p值越小,表示相关系数越显著,一般p值在500个样本以上时有较高的可靠性。
警告:
- ConstantInputWarning,如果输入是常量数组则引发。在这种情况下,相关系数未定义,因此返回
np.nan
例如:
rho,pvalue = stats.spearmanr([1,2,3,4,5], [5,6,7,8,7])
三、 相关性分析结果可视化
参考文献:
1.https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.savefig.html
2.宁海涛 微信公众号:DataCharm,Python-matplotlib 学术型散点图绘制
3.宁海涛 微信公众号:DataCharm,Python-matplotlib 学术散点图完善
1. 简单散点图
一般情况下我们可以通过散点图来检测和了解变量间的关系。如果变量之间存在某种关联,那么数据点就会在图上呈现某种趋势。在某些情况下(如样本点较少),可能会出现聚集趋势不明显的问题,这时我们可以借助线性拟合而成的“趋势线”来辅助分析。
如下图a中,利用散点图展现了SSP126、SSP245、SSP370和SSP585排放情景下未来降水增长率与未来气温增长率之间的约束关系。由于单个情景下的散点数量较少,且多个情景的散点放置于同一张图中进行比较,散点的聚集趋势难以肉眼捕捉,因此该图对各个场景下的散点进行线性拟合,展现出散点的分布趋势线,便于读者更为直观地解读。

#....准备数据代码略.....
#绘制散点图
fig,ax = plt.subplots(figsize=(7,5),dpi=200)
dian = plt.scatter(GndSos['海北站'], TiReSos['CsifHaibeiAG'], edgecolors='None', c='k', s=16, marker='s', zorder=2)
# print(type(GndSos['海北站']))
#绘制拟合线
# 绘制上下误差线,学术性相关性散点图还需添加拟合最佳上线(upper line)和下线(bottom line),
# 而两者的绘制依据为1:1 最佳线和误差 Δτ= ± (0.05+0.15 True data ,分别对应y=1.15×+0.05 (upper line) and y=0.85×−0.05 (bottom line)。
# 基于此,我们绘制误差线的关键代码如下:
# 用于绘制最佳拟合线
x2 = np.linspace(0,2500,7)#默认是50个点,现为7个点
y2 = x2
# 绘制upper line
up_y2 = 1.15 * x2 + 0.05
# 绘制bottom line
down_y2 = 0.85 * x2 - 0.05
# 添加上线和下线
ax.plot(x2, up_y2, color='k', lw=1.5, ls='--', zorder=2)
ax.plot(x2, down_y2, color='k', lw=1.5, ls='--', zorder=2)
def f_1(x,A,B):
return A*x+B
A1,B1 = optimize.curve_fit(f_1,GndSos['海北站'],TiReSos['CsifHaibeiAG'])[0]
y3 = A1*np.asarray(GndSos['海北站']) + B1
ax.plot(x2,y2,color = 'k',linewidth = 1.5,linestyle = '--',zorder=1)
ax.plot(x2,y3,color = 'r',linewidth = 2,linestyle = '-')
fontdict1 = {"size":17,"color":'k',"family":"Times New Roman"}
ax.set_xlabel("True Values",fontdict=fontdict1)
ax.set_ylabel("Estimated Values",fontdict=fontdict1)
ax.grid(False)
ax.set_xlim((0,2500))
ax.set_ylim((0,2500))
ax.set_xticks(np.arange(0,2500,step=200))
ax.set_yticks(np.arange(0,2500,step=200))
#设置刻度字体
labels = ax.get_xticklabels()+ax.get_yticklabels()
[label.set_fontname('Times New Roman')for label in labels]
for spine in ['top','bottom','left','right']:
ax.spines[spine].set_color('k')
ax.tick_params(left=True,bottom=True,direction='in',labelsize=14)
#添加题目
titlefontdict={"size":20,"color":"k",'family':"Times New Roman"}
ax.set_title('Scatter plot of True data and Model Estimated',titlefontdict,pad=20)
fontdict={"size":16,"color":"k",'family':"Times New Roman"}
ax.text(100,2300,r'$R^2=$'+str( RMSE[0][0][0][0]),fontdict=fontdict)
ax.text(100,2100,'RMSE='+str(RMSE[0][0][0][1]),fontdict=fontdict)
ax.text(100,1900,r'$N=$'+str(SpearR[0][0][0][0]),fontdict=fontdict)
ax.text(100, 1700, r'$y=$' + str(RMSE[1][0][0][0])+'$x$'+'+'+str(RMSE[1][1][0][0]), fontdict=fontdict)
text_font = {"size": 22, "color": "k", 'family': "Times New Roman","weight":"bold"}
ax.text(.9,.9,'(a)',transform=ax.transAxes,fontdict=text_font,zorder=4)
ax.text(.8, .056, '\nVisualization by DataCharm', transform=ax.transAxes, ha='center',va='center',fontsize=10, color='black')
# papertypes可以设置为“a0到a10”, “executive,” “b0 to b10”, “letter,” “legal,” “ledger.”
# plt.savefig(pic_path+'test.png',papertype='b5',dpi=900,bbox_inches='tight')
plt.show()
运行结果:

2. 带颜色的散点密度图
如果散点更多,则需要用颜色映射进行散点密度映射,使读者更容易理解图表。(以下代码未验证)
# Estimate the 2D histogram
nbins = 150
H, xedges, yedges = np.histogram2d(X, Y, bins=nbins)
# H needs to be rotated and flipped
H = np.rot90(H)
H = np.flipud(H)
# Mask zeros
Hmasked = np.ma.masked_where(H==0,H) # Mask pixels with a value of zero
#开始绘图
plt.pcolormesh(xedges, yedges, Hmasked, cmap=cm.get_cmap('jet'), vmin=0, vmax=40)
同时需要对colorbar进行定制化设置,详细代码如下:
cbar = plt.colorbar(ax=ax,ticks=[0,10,20,30,40],drawedges=False)
#cbar.ax.set_ylabel('Frequency',fontdict=colorbarfontdict)
cbar.ax.set_title('Counts',fontdict=colorbarfontdict,pad=8)
cbar.ax.tick_params(labelsize=12,direction='in')
cbar.ax.set_yticklabels(['0','10','20','30','>40'],family='Times New Roman')
运行结果如下:
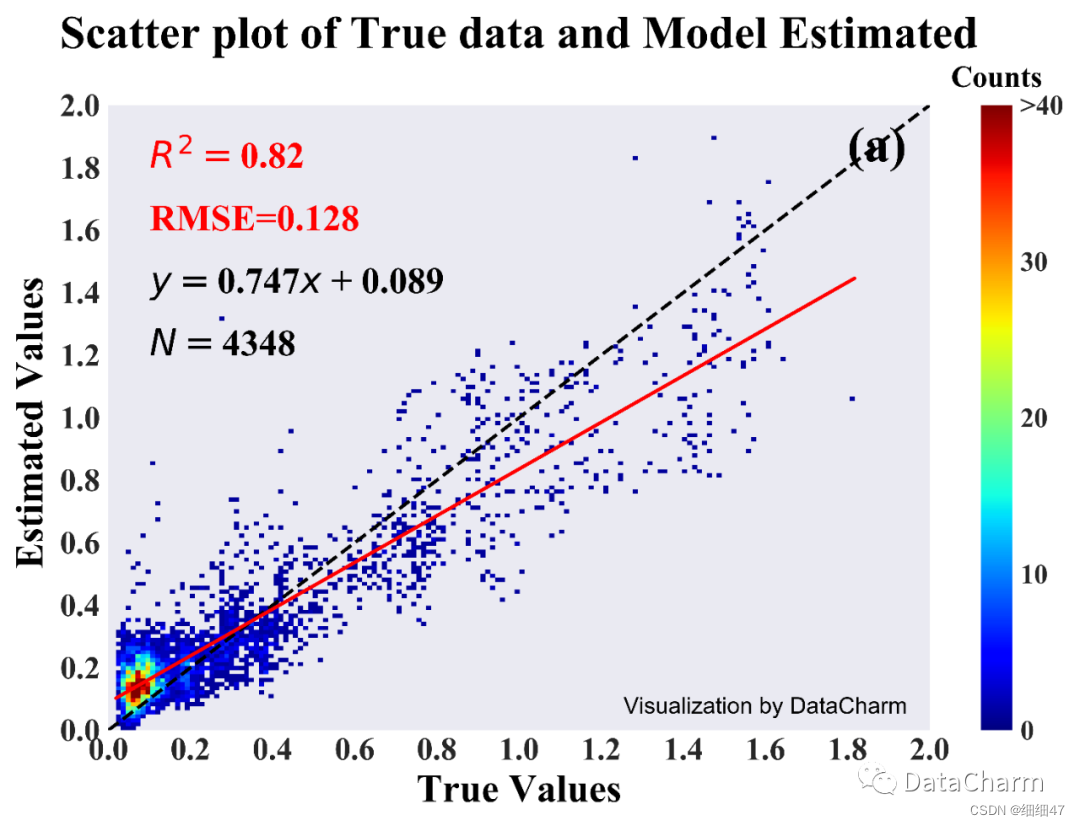
上述结果是更改了matplotlib绘图风格,即在绘图之前添加如下代码:
plt.style.use('seaborn-darkgrid')
3. 修改字体
对于学术图表的字体设置,一般的期刊都是要求 数字和字母为 Times New Roman 字体,当然这也不完全统一,具体还是和所投的期刊要求有关。若需更改为Arial,统一修改字体关键代码如下:
#统一修改字体
plt.rcParams['font.family'] = ['Arial']
使用上述代码后,对应局部修改字体的代码就该删除。
4. 合并多图
#.....前代码见1.简单散点图...
fig,ax = plt.subplots(1,2,figsize(9,3),dpi=200,sharey=True,facecolor="white")
ax[0].scatter(x,y,edgecolor=None,c='k',s=5,marker='s')
ax[0].plot(x2,y2,color='k',lw=1.5,ls='-',zorder=2)
#...略...
先甩到这,以后再验证

结果如下:
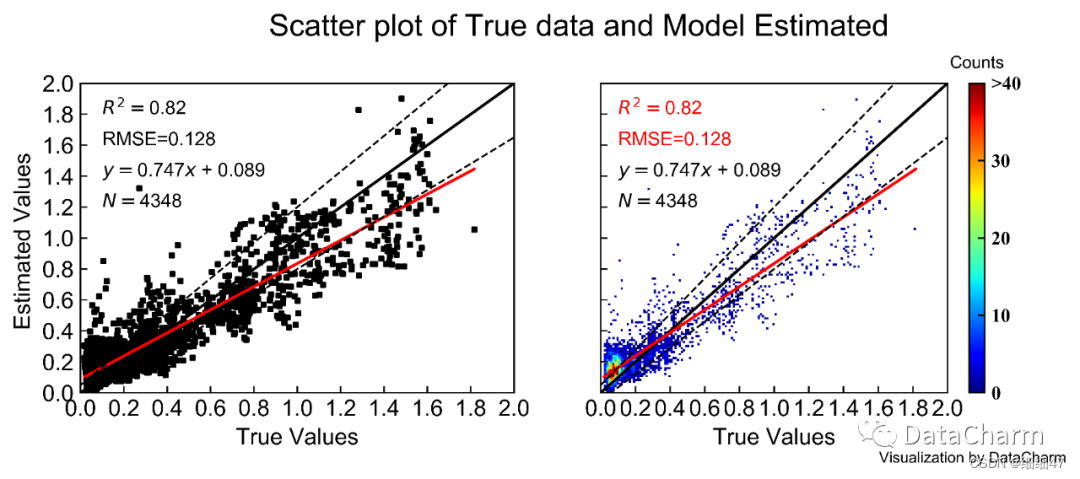
5. 相关性散点类型
在其他论文中看到如下类型的散点图,如下:
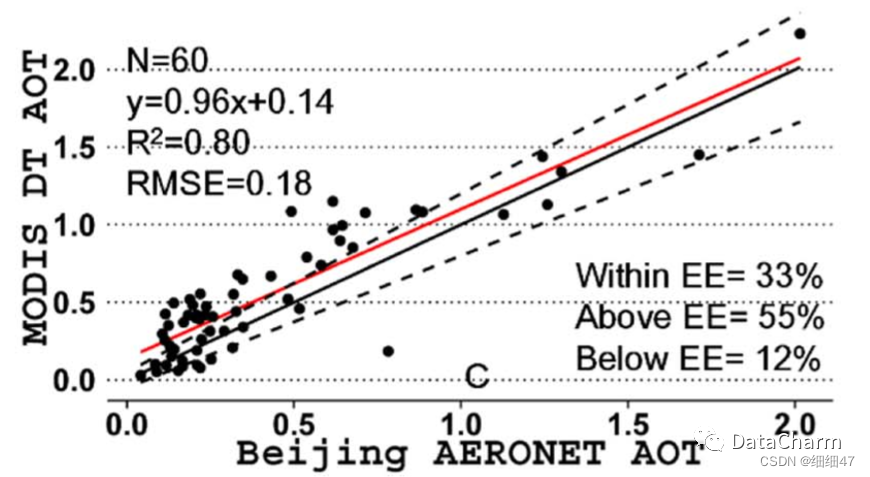
(该图片来源于网络,如侵权,望告知删除)
python-matplotlib 绘制这类相关性散点图也比较简单,核心代码如下:
#网格设置
ax.grid(which='major',axis='y',ls='--',c='k',alpha=.7)
ax.set_axisbelow(True)
#轴脊设置
for spine in ['top','left','right']:
ax.spines[spine].set_visible(None) #隐去轴脊
ax.spines['bottom'].set_color('k') #设置bottom颜色
#刻度设置,只显示bottom的刻度,且方向向外,长、宽也进行设置
ax.tick_params(bottom=True,direction='out',labelsize=14,width=1.5,length=4,left=False)
刻度间隔设置也都是可以自定义的,如下:
#设置刻度间隔
from matplotlib.pyplot import MultipleLocator
x_major_locator=MultipleLocator(.5)
y_major_locator=MultipleLocator(.5)
ax.xaxis.set_major_locator(x_major_locator)
ax.yaxis.set_major_locator(y_major_locator)















 4572
4572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









