








摘要
神经网络是一种强大而灵活的模型,能够很好地解决图像、语音和自然语言理解中的许多困难学习任务。尽管成功,神经网络仍然很难设计。在本文中,我们使用一个循环网络来生成神经网络的模型描述,并通过强化学习训练该RNN,以最大限度地提高生成的架构在验证集上的预期精度。在cifar-10数据集上,我们的方法从无到可以设计出一种新的网络体系结构,在测试集精度方面可以与人类发明的最佳体系结构相媲美。我们的cifar-10模型的测试错误率为3.65,比使用类似体系结构方案的最先进模型高0.09%,快1.05倍。在Penn Treebank数据集上,我们的模型可以组成一个新的循环单元,其性能优于广泛使用的LSTM单元和其他最先进的基线。我们的 cell 在Penn Treebank测试集复杂度达到62.4,比以前的最先进的模型复杂度高出3.6。该单元还可以转移到PTB上的字符语言建模任务中,实现了1.214的最先进的复杂度。
1.介绍
在过去的几年中,深层神经网络在许多具有挑战性的应用中取得了巨大成功,例如语音识别、图像识别和机器翻译。随着这一成功,从功能设计到架构设计的范式转变,即从SIFT和Hog到Alexnet、Vggnet、Googlenet和Resnet。虽然架构设计变得越来越简单,但仍然需要大量的专业知识和足够的时间。
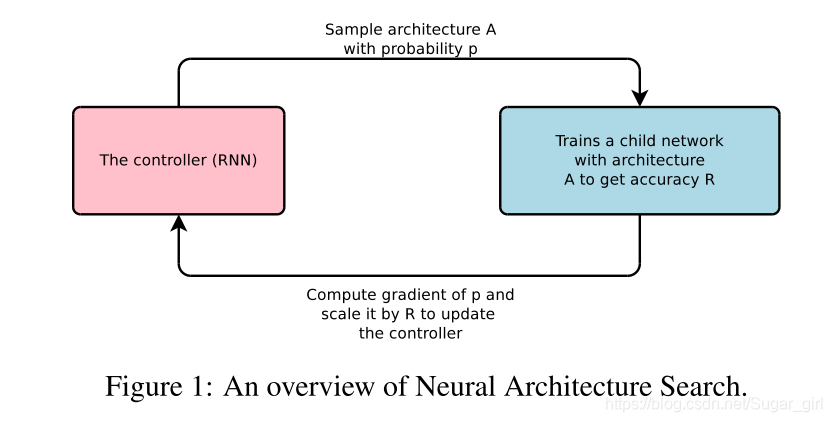
本文介绍了神经架构搜索,一种基于梯度的方法来寻找良好的架构(见图1)。我们的工作是基于观察,神经网络的结构和连通性通常可以由可变长度的字符串来代表。
因此,可以使用循环网络recurrent network(控制器)来生成这样的字符串。对字符串代表的网络(即“子网络”)进行实际数据的培训将导致验证集的准确性。利用该精度作为奖励信号,可以计算策略梯度来更新控制器。因此,在下一次迭代中,控制器将为获得高精度的架构提供更高的概率。换句话说,随着时间的推移,控制器将学习改进其搜索。
我们的实验表明,神经架构搜索可以从头开始设计好的模型,这是其他方法无法实现的。在使用cifar-10进行图像识别时,神经结构搜索可以找到一种新的ConvNet模型,该模型优于大多数人类发明的结构。我们的cifar-10模型实现了3.65测试集错误,同时比当前的最佳模型快1.05倍。在Penn-Treebank语言建模中,神经结构搜索可以设计出一种新的循环单元,该单元也优于以前的RNN和LSTM结构。我们的模型发现的单元在Penn Treebank数据集上达到了62.4的测试集复杂度,这比以前的最先进水平高出3.6的复杂度。
2.相关工作
超参数优化是机器学习中的一个重要研究课题,在实践中得到了广泛应用。尽管取得了成功,但这些方法仍然有限,因为它们只从固定长度的空间中搜索模型。换句话说,很难要求他们生成一个可变长度的配置来指定网络的结构和连接。在实践中,如果提供良好的初始模型,这些方法通常会更好地工作。有一些贝叶斯优化方法允许搜索非固定长度的架构,但与本文提出的方法相比,它们的通用性和灵活性较差。
现代神经进化算法,可以更灵活地创作新的模型。他们通常实用性较差。限制在于他们是搜索为基础的方法,都是缓慢的,因此,需要很多heuristics才能完成好。
神经架构搜索与程序合成和归纳编程(从示例中搜索程序的想法)有一些相似之处。在机器学习中,概率程序归纳法已成功地应用于许多环境中,例如学习解决简单的问答、排序数字列表、用很少的例子学习。
神经结构搜索中的控制器是自回归的,这意味着它在先前的预测的基础上,一次预测一个超参数。这一想法借鉴了端到端序列到序列学习中的解码器。与顺序到顺序学习不同,我们的方法优化了一个不可微分的度量,即子网的准确性。因此,它类似于神经机器翻译中的BLEU优化的工作。与这些方法不同,我们的方法直接从奖励信号学习,而不需要任何有监督的引导。
与我们的工作相关的还有自学习或元学习,这是一个使用在一个任务中学习的信息来改进未来任务的一般框架。更密切相关的是,使用神经网络学习另一个网络的梯度下降更新和使用强化学习查找另一个网络的更新策略的想法。
3.方法
在下面的部分中,我们将首先描述一种使用循环网络生成卷积体系结构的简单方法。我们将展示如何使用策略梯度方法训练循环网络,以最大限度地提高抽样架构的预期精度。我们将介绍一些核心方法的改进,例如形成跳过连接以增加模型复杂性,并使用参数服务器方法来加快培训。在本节的最后一部分,我们将着重于生成循环体系结构,这是本文的另一个重要贡献。
3.1 使用循环神经网络控制器生成模型描述
在神经结构搜索中,我们使用控制器来生成神经网络的结构超参数。为了灵活起见,控制器被实现为一个循环神经网络。假设我们要预测只包含卷积层的前馈神经网络,我们可以使用控制器生成它们的超参数作为标记序列:
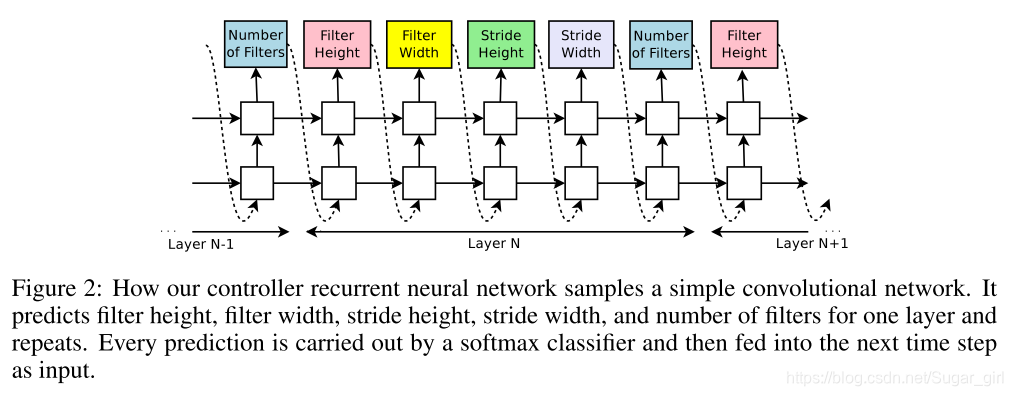
我们的循环神经网络控制器如何采样一个简单的卷积网络。它重复预测一个层的过滤器高度、过滤器宽度、跨距高度、跨距宽度和过滤器数量。每个预测都由一个SoftMax分类器执行,然后作为输入到下一个时间步骤。
在我们的实验中,如果层数超过某个值,那么生成体系结构的过程就会停止。这个值遵循一个时间表,我们会随着培训的进展而增加它。一旦控制器RNN完成一个体系结构的生成,一个具有该体系结构的神经网络就被建立和训练。在收敛时,记录了保留验证集上网络的精度。然后对控制器RNN的参数
θ
c
\theta _{c}
θc进行优化,以最大限度地提高所提出体系结构的预期验证精度。在下一节中,我们将描述一个策略梯度方法,我们使用它来更新参数
θ
c
\theta _{c}
θc,以便控制器RNN随着时间的推移生成更好的体系结构。
3.2 用REINFORCE训练
控制器预测的列表tokens可以看作是为子网络设计架构的actions列表
a
1
:
T
a_{1:T}
a1:T。在收敛时,该子网络将在held-out数据集上实现精确度R。我们可以利用这个精度R作为奖励reward,并利用强化学习来训练控制器。更具体地说,为了找到最佳架构,我们要求控制器最大化其预期回报,用
J
(
θ
c
)
J(\theta _{c})
J(θc)表示:
J
(
θ
c
)
=
E
P
(
a
1
:
T
;
θ
c
)
[
R
]
J(\theta _{c})=E_{P(a_{1:T};\theta _{c})}[R]
J(θc)=EP(a1:T;θc)[R]
由于奖励信号R是不可微的,我们需要使用策略梯度方法迭代更新
θ
c
\theta _{c}
θc。在这项工作中,我们使用了REINFORCE规则:
▽
θ
c
J
(
θ
c
)
=
∑
t
=
1
T
E
P
(
a
1
:
T
;
θ
c
)
[
▽
θ
c
log
P
(
a
t
∣
a
(
t
−
1
)
:
1
;
θ
c
)
R
]
\bigtriangledown _{\theta _{c}}J(\theta _{c})= \sum_{t=1}^{T}E_{P(a_{1:T};\theta _{c})}[\bigtriangledown _{\theta _{c}}\log P(a_{t}|a_{(t-1):1};\theta _{c})R]
▽θcJ(θc)=t=1∑TEP(a1:T;θc)[▽θclogP(at∣a(t−1):1;θc)R]
上述数量的经验近似值为:
1
m
∑
k
=
1
m
∑
t
=
1
T
▽
θ
c
log
P
(
a
t
∣
a
(
t
−
1
)
:
1
;
θ
c
)
R
k
\frac{1}{m}\sum_{k=1}^{m}\sum_{t=1}^{T}\bigtriangledown _{\theta _{c}}\log P(a_{t}|a_{(t-1):1};\theta _{c})R_{k}
m1k=1∑mt=1∑T▽θclogP(at∣a(t−1):1;θc)Rk
其中m是控制器在一批中采样的不同结构的数量,T是控制器设计神经网络结构时必须预测的超参数的数量。第k个神经网络结构在训练数据集上训练后所达到的验证精度为
R
k
R_{k}
Rk。
上面的更新是我们的梯度的一个无偏估计,但是有一个非常高的方差。为了减少这个估计的方差,我们使用了一个基线函数。
1
m
∑
k
=
1
m
∑
t
=
1
T
▽
θ
c
log
P
(
a
t
∣
a
(
t
−
1
)
:
1
;
θ
c
)
(
R
k
−
b
)
\frac{1}{m}\sum_{k=1}^{m}\sum_{t=1}^{T}\bigtriangledown _{\theta _{c}}\log P(a_{t}|a_{(t-1):1};\theta _{c})(R_{k}-b)
m1k=1∑mt=1∑T▽θclogP(at∣a(t−1):1;θc)(Rk−b)
只要基线函数b不依赖于当前动作,那么这仍然是一个无偏梯度估计。在这项工作中,我们的基线b是先前结构精度的指数移动平均值。
通过并行和异步更新加速培训: 在神经网络结构搜索,控制器参数
θ
c
\theta _{c}
θc的每次梯度更新都对应于训练一个子网络收敛。作为一个子网络培训可以采取小时,我们使用分布式训练和异步参数更新为了加速控制器的训练过程。我们使用一个参数服务器方案,我们有一个分片数为S的参数服务器,存储了K控制器副本的共享参数。每个控制器副本都会对并行训练的不同子体系结构进行采样。然后,控制器根据收敛时的小批量M体系结构的结果收集渐变,并将其发送到参数服务器,以便更新所有控制器副本的权重。在我们的实现中,当每个子网络的训练超过一定的时间段时,就达到了网络的收敛。图3总结了这种并行方案。
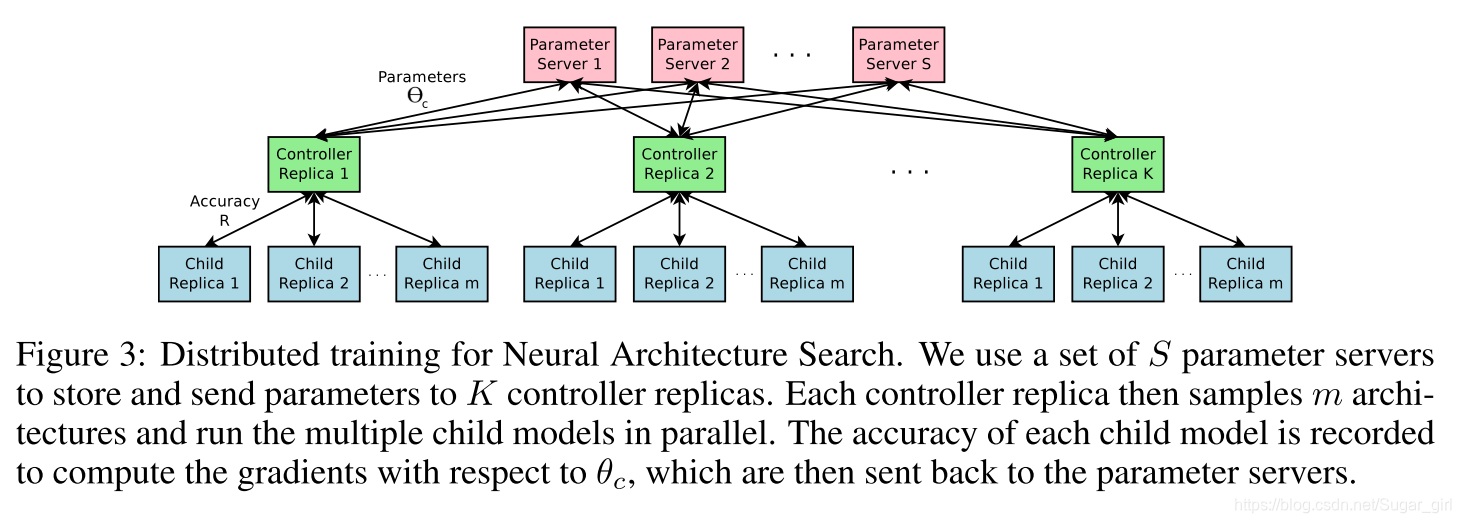
神经架构搜索的分布式训练。我们使用一组S个参数服务器来存储和发送参数到K个控制器副本。然后,每个控制器副本对M个架构进行采样,并行运行多个子模型。记录每个子模型的精度,以计算
θ
c
\theta _{c}
θc的梯度,然后将梯度发送回参数服务器。
3.3 使用跳过连接和其他层类型增加体系结构复杂性
在第3.1节中,搜索空间没有跳接或分支层用于现在结构中,如Googlenet和Remainial Net。在本节中,我们介绍了一种方法,它允许我们的控制器提出跳过连接或分支层,从而扩大搜索空间。
为了使控制器能够预测这种连接,我们使用一个基于注意机制的集合选择类型注意。在第n层,我们添加一个锚定点,该锚定点具有N-1基于内容的sigmoids,以指示需要连接的前一层。每个sigmoid是控制器当前隐藏状态和前n-1锚定点的前隐藏状态的函数:
P
(
L
a
y
e
r
j
i
s
a
n
i
n
p
u
t
t
o
l
a
y
e
r
i
)
=
s
i
g
m
o
d
(
v
T
t
a
n
h
(
W
p
r
e
v
∗
h
j
+
W
c
u
r
r
∗
h
i
)
)
P(Layer \ j \ is \ an \ input \ to \ layer \ i)=sigmod(v^{T}tanh(W_{prev}*h_{j}+W_{curr}*h_{i}))
P(Layer j is an input to layer i)=sigmod(vTtanh(Wprev∗hj+Wcurr∗hi))
h
j
h_{j}
hj表示在第j层anchor point的控制器隐藏状态,j的范围从0到N-1。
我们从这些sigmods中取样,决定哪些之前的层用作当前层的输入。
W
p
r
e
v
W_{prev}
Wprev、
W
c
u
r
r
W_{curr}
Wcurr和
v
v
v矩阵是可训练的参数。由于这些连接也由概率分布定义,因此REINFORCE方法仍然适用,无需进行任何重大修改。图4显示了控制器如何使用跳过连接来决定它希望哪些层作为当前层的输入。
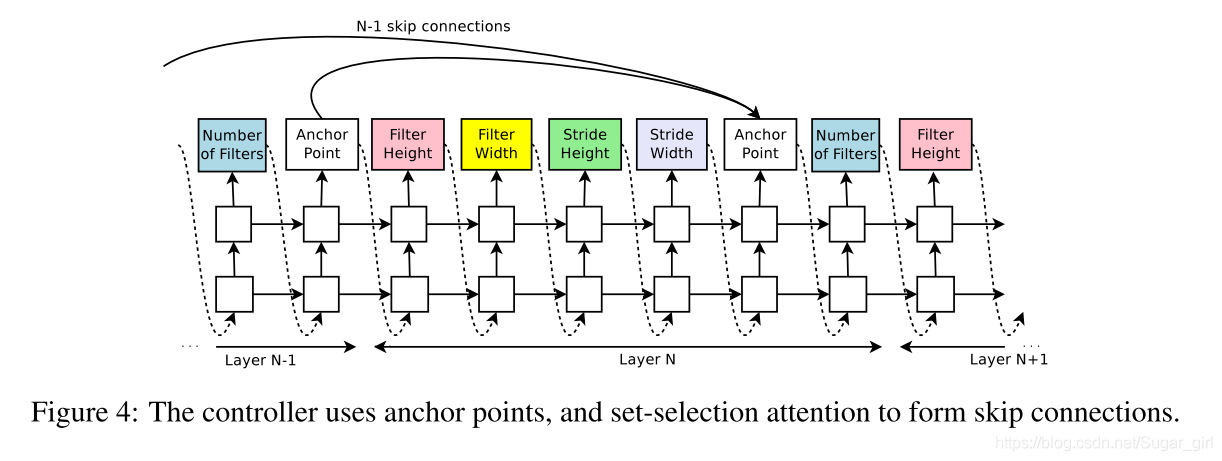
控制器使用定位点,并设置选择的注意机制以形成跳过连接。
在我们的框架中,如果一个层有多个输入层,那么所有输入层都在深度维度中连接起来。跳过连接可能会导致“编译失败”,其中一个层与另一个层不兼容,或者一个层可能没有任何输入或输出。为了避免这些问题,我们采用了三种简单的技术。首先,如果一个层没有连接到任何输入层,那么图像将用作输入层。第二,在最后一层,我们获取所有尚未连接的层输出,并在将这个最后的hiddenstate发送到分类器之前将它们连接起来。最后,如果要连接的输入层具有不同的大小,我们用零填充小层,以便连接的层具有相同的大小。
最后,在第3.1节中,我们不预测学习率,我们还假设架构只包含卷积层,这也是非常严格的。有可能将学习率作为预测之一。此外,还可以预测架构中的池化、局部对比标准化。为了能够添加更多类型的层,我们需要在控制器RNN中添加一个额外的步骤来预测层类型,然后再添加与之相关的其他超参数。
3.4 生成重复的单元体系结构
在本节中,我们将修改上述方法以生成循环单元。在每一个步骤t,控制器都需要找到一个以
x
t
x_{t}
xt和
h
t
−
1
h_{t-1}
ht−1作为输入的
h
t
h_{t}
ht函数形式。最简单的方法是让
h
t
=
tanh
(
W
1
∗
x
t
+
W
2
∗
h
t
−
1
)
h_{t}=\tanh(W_{1}* x_{t}+W_{2}*h_{t-1})
ht=tanh(W1∗xt+W2∗ht−1),这是一个基本的循环单元的公式。更复杂的公式是广泛使用的LSTM循环细胞。
基本RNN和LSTM单元的计算可概括为以
x
t
x_{t}
xt和
h
t
−
1
h_{t-1}
ht−1作为输入并产生
h
t
h_{t}
ht作为最终输出的步骤树。控制器RNN需要用组合方法(加法、元素乘法等)和激活函数(tanh、sigmoid等)标记树中的每个节点,以合并两个输入并生成一个输出。然后将两个输出作为输入馈送到树中的下一个节点。为了让控制器RNN选择这些方法和函数,我们按顺序索引树中的节点,以便控制器RNN可以逐个访问每个节点并标记所需的超参数。
根据LSTM细胞的构建,我们还需要单元变量
c
t
−
1
c_{t-1}
ct−1和
c
t
c_{t}
ct来代表记忆状态。为了将这些变量纳入其中,我们需要控制器RNN预测用树上的什么结点来连接树上的两个变量。这些预测可以在控制器RNN的最后两个区块中作出。
为了使这一过程更加清晰,我们在图5中展示了一个具有两个叶节点和一个内部节点的树结构的示例。叶节点由0和1索引,内部节点由2索引。控制器RNN首先需要预测3个块,每个块为每个树索引指定一个组合方法和一个激活函数。之后,它需要预测最后两个块,指定如何将
c
t
c_{t}
ct和
c
t
−
1
c_{t-1}
ct−1连接到树内的临时变量。

由具有两个叶节点(base 2)和一个内部节点的树构建的循环单元的示例。左:定义控制器要预测的计算步骤的树。中间:控制器为树中的每个计算步骤所做的一组预测示例。右:根据控制器的示例预测构建的循环单元的计算图。
根据本例中控制器RNN的预测,将发生以下计算步骤:

在上面的例子中,树有两个叶节点,因此它被称为“base 2”架构。在我们的实验中,我们使用基数8来确保单元cell的表达能力。
4.实验结果
5.结论
本文介绍了一种利用循环神经网络组成神经网络结构的思想,神经网络结构搜索。该方法以循环网络为控制器,具有灵活性,可以搜索变长的体系结构空间。我们的方法在非常具有挑战性的基准上具有很强的经验性能,为自动寻找良好的神经网络结构提供了一个新的研究方向。控制器在cifar-10和ptb上找到的运行模型的代码将在https://github.com/tensorflow/models上发布。此外,我们还将使用我们的方法在名称NASCell下找到的RNN cell添加到tensorflow中,这样其他人就可以很容易地使用它。














 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









