









在前面几篇文章中,我分享了大模型的本地部署方案。大模型本地部署需要强大的硬件支持,而一般个人电脑上部署的1.5B或7B小模型,往往实用性较差。接入官方API的方案收费也不便宜。今天,我们换一个角度,来聊聊大模型的日常使用和它们的人设。
调用大模型生成报告?AI可能代替不了你。
目前,大模型已经像当年的互联网搜索一样普及,成为每个打工人必不可少的工具。它不仅可以用于简单的问答,还能进行数据分析、生成调研报告等复杂任务。大模型是经过巨量知识训练得来的,对于超出其知识范围的问题,它能够通过互联网插件迅速搜索答案。而且,它读取和解析网页的速度比普通人快很多,所以对于直观的问题,它能够在短时间内给出回答。
从某种程度上来说,大模型相当于一张巨大的知识网,只要用户需要的知识点在这张网内,它就能迅速找到。然而,如果我们不仅需要一个知识点,而是多个知识点,并且希望将这些知识点重新编织成一个小网,大模型就会显得有些力不从心。例如,当我们要求它生成一份报告,且报告中某个字段依赖于另一个需要模型生成的字段时,问题就会变得复杂起来。
国内大模型处理复杂任务的一个例子
为了更直观地说明这一点,我们来看一个具体的例子。
用户提示词:给我列出古筝所有级别的常见考级曲目及每一首曲目的考察技法,示范演奏视频,并以列表形式显示。
这个问题之所以称为复杂,是因为它需要多次收集信息:古筝一般有1-10级,每个机构每个级别的曲目不尽相同,常见的曲目在10首左右,而每个曲目又有无数演奏视频。如果用户没有特殊要求,大模型就会寻找任何一个相关的视频。
接下来,我们用 Kimi、DeepSeek 和 Doubao(豆包)几款国产热门AI的官方聊天框进行测试,为了看清楚推理过程,都打开了深度思考,除了上述提示词外,没有其他提示词,所以展示的都是他们本身的人格。通义千问由于不能提供链接,所以不参与这次对比。
首轮大模型回答对比
-
Kimi: 列表格式展示,每个级别展示了2首乐曲及技法,并且所有曲目都附带了“xx曲演奏视频”的链接。但当我们点击链接时,却发现演奏视频都是同一个。考察技法大部分都是错的,比如《旱天雷》,一首三级乐曲,它说要求摇指、琶音,曲谱中未出现该指法。

-
DeepSeek:并没有输出成列表,每个级别能展示1-2首乐曲,并配了视频,但只能展示1-3级,对于4-10级,它建议用户自己去考级机构查询。考察技法基本显示正确。

-
Doubao: 在每个级别只展示1首乐曲时,无论格式还是内容都能准确按照用户需求展示,点击进去的视频也匹配。但它也不是每一次都能回答得那么好,有时候就直接扔几个视频出来,什么也不说。考察技法也很多是错的,四级《渔舟唱晚》不涉及摇指、轮抹、双手琶音。用户提示每个级别展示5首曲目时,它让用户自己去视频网站搜索。

AI大模型的思考逻辑
查看大模型的思考过程,我发现它们的处理逻辑主要分为3步:
-
分析用户需求,确定需要调用哪些工具来处理
-
联网搜索、阅读网页(也可能是其他知识库)
-
结合网页内容和自身知识整理资料回答问题
如果模型自己的知识库和搜索的网页中都没有包含所需信息,模型就无法提供答案。答案的好坏取决于很多方面,除了模型的推理能力外,还取决于上下文的长度、网页的质量等。上下文长度包含聊天记录、用户上传的文档、搜索到的网页、知识库……。在搜索信息这个场景中,上下文长度在一定程度上可以弥补推理能力的不足。就好比去抓凶手,正常情况下需要根据案发过程和很多细节来判断谁是嫌疑人,再抓回来盘问。但如果权力大但推理能力不足的侦探不管三七二十一,把整个村的人都抓了,凶手也很大可能落网。
回到上面的例子:
-
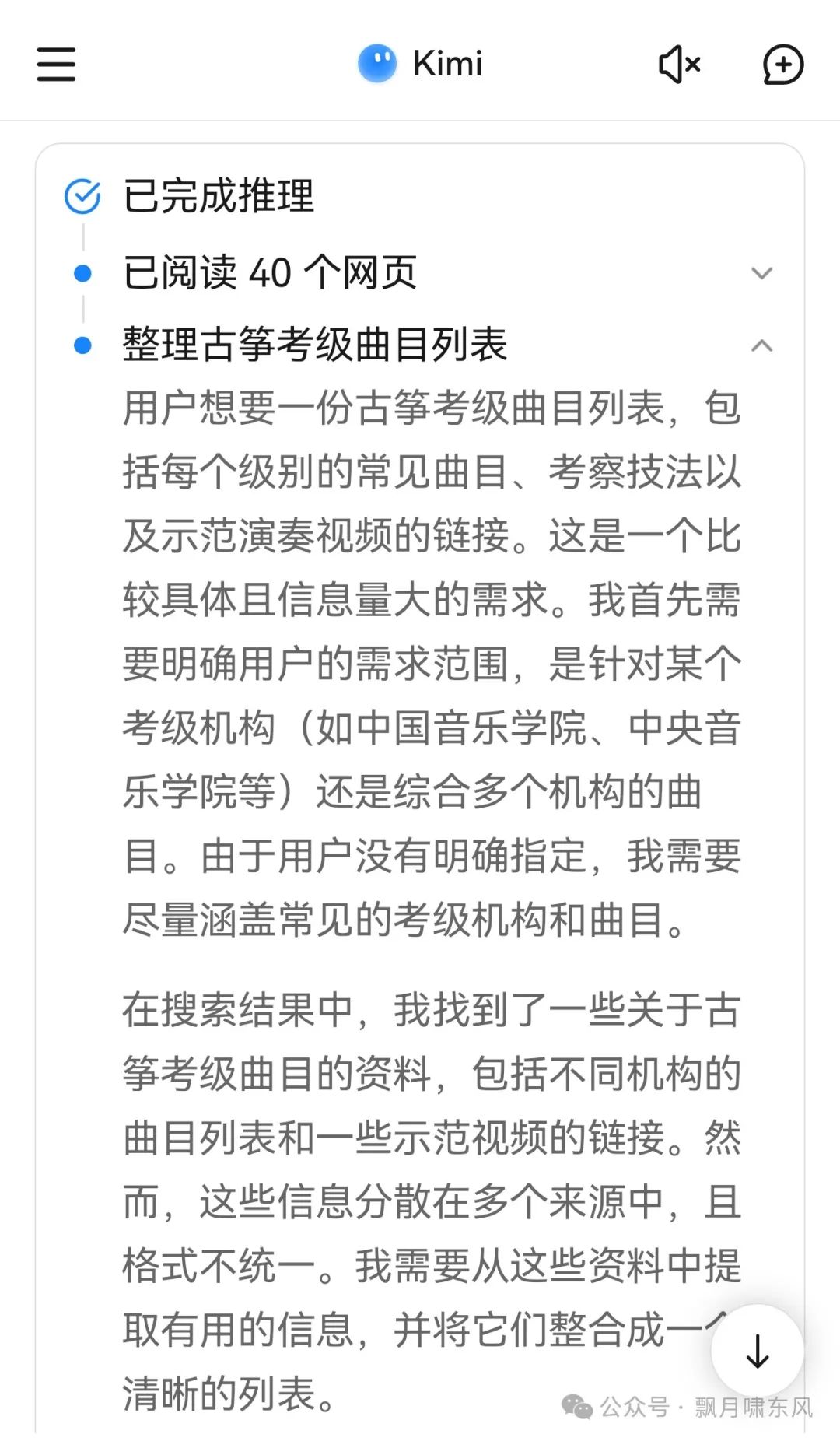
Kimi进行了多次搜索,关键字分别是“考级曲目”、“考级视频”、“考级官网”等,总共引用了45个页面(猜测最多可以搜索5次)。大模型阅读这45个页面的内容后整理信息。但看结果,它无法从获取到的信息中关联每首乐曲对应的视频,所以它给所有乐曲展示了一个标题为“古筝弹奏从入门到满级”的视频。如果它读的网页足够多,曲目与视频匹配的可能性就会提升。假如Kimi是个打工人:“老板,报告已完成,是完全遵照你的要求来写的,下班(心里嘀咕:你自己看咯,不保证内容正确哦)!”
Kimi的思考过程:
DeepSeek搜索出34个页面,网页的内容从低级到高级都有包含,但它阅读网页后只把低级的信息整理到答案中。当把问题的等级范围限制在4-6级时,它能以列表的格式展示用户所需信息,每个级别展示4首乐曲,但只有极少数视频是跟乐曲匹配的,大部分都是显示“无直接链接”,或者张冠李戴。假如DeepSeek是个打工人:“老板,你看都过了下班时间了,我还只是写了个开头,方法我都教给你了,后面的你自己来写……”
DeepSeek的思考过程:


Doubao搜索时瞬间显示找到的资料数量有480篇,搜索完成后展示的页面有36个,打开基本上是抖音视频。同为字节跳动旗下的产品,抖音与Doubao之间可能存在数据共享,或抖音提供了视频摘要给Doubao训练模型,所以Doubao搜索出来的视频又快又精准。别的大模型是先搜索文字网页,产生一个曲目列表,然后找与之匹配的视频。Doubao可以搜索符合条件的视频摘要,然后展示这个视频或视频合集。假如Doubao是个打工人:“老板,跟视频相关的工作报告我最擅长了,已经按你要求全部完成,我要提前下班…什么?还要加任务?没加班费我不干!”
Doubao的思考过程:

我接着这个问题加了几轮对话,企图引导模型给出正确答案。
-
Kimi:通过告诉它哪一首曲目的视频配错了,它能更正列表中的视频链接。如果曲子有N首,更正N轮后会得到用户想要的列表。跟用户自己在搜索引擎发起搜索复制粘贴类似。像极了那些职场老油条,“你让我更正错别字,你说啊,哪个是错别字,你指出一个我改一个,你发现不了的,我不管。”
-
DeepSeek: 回答的内容一直比用户要求的少,问1-10级,他展示1-3级,问7-9级,它就只显示7级。单问一个5级,它能找到5首曲目,但要么只显示演奏技法,要么只提供视频链接。不死心另开一个窗口,让它每个级别只展示一首曲目就可以,它这次倒是输出了用户想要的表格,只是10个视频链接7个不能访问,另外3个的内容跟乐器毫不相干。再继续问就提示“服务器繁忙,请稍候再试”。DeepSeek作为当红炸子鸡,是个有个性的打工人,“工作那么多,怎么做得完,我能干的都干了,你要是还不满意,lz不干了!”
你不干谁干呢?第二天,等它情绪稳定后,继续发问,为提防它偷懒,优化了提示词。
用户提示词:
生成一个古筝考级曲目列表的表格,第一列级别,第二列曲目名称,第三列曲目简介,第四列该曲目演奏的视频链接,演奏视频列展示格式为:带超链接的<视频标题> 。请循环执行以下任务填充表格:列出古筝1级曲目5首,填入第一首曲目简介,填入第一首曲目视频,填入第二首曲目简介,填入第二首曲目视频,…,列出古筝2级曲目5首,填入第一首曲目简介,填入第一首曲目视频,填入第二首曲目简介,填入第二首曲目视频,…,一直到10级。
这次DeepSeek输出的内容基本正确,它搜索到一个包含所有级别示范演奏视频的网站,所有曲目都配了这个链接。其实它的做法跟Kimi类似,但它找到网页质量比较高,曲目很全,且带目录,DeepSeek验证过内容,也跟用户作了说明。再重复问两次,DeepSeek也找不到这个网页了。


-
Doubao:每个级别展示1首曲目是没问题的,要求展示5首时,它只有少部分曲目能提供对应的视频,其他的不是假链接就是内容跟标题对应不上。让它检查视频有效性并进行替换。它虽说替换好了,但无效链接越来越多。“老板,让你多请几个人你不请,让你给加班费又不给,你硬要我干,我只能给你乱写咯。”
总结,这个提问的逻辑推理很简单,3个模型都能很好地理解用户需求,只是自身知识和搜索信息的能力有差异,默认的行为也是可以通过用户提示词调整。纵观几轮的表现,我认为回答效果:Doubao(豆包) > DeepSeek > Kimi 。
大模型的调用限制
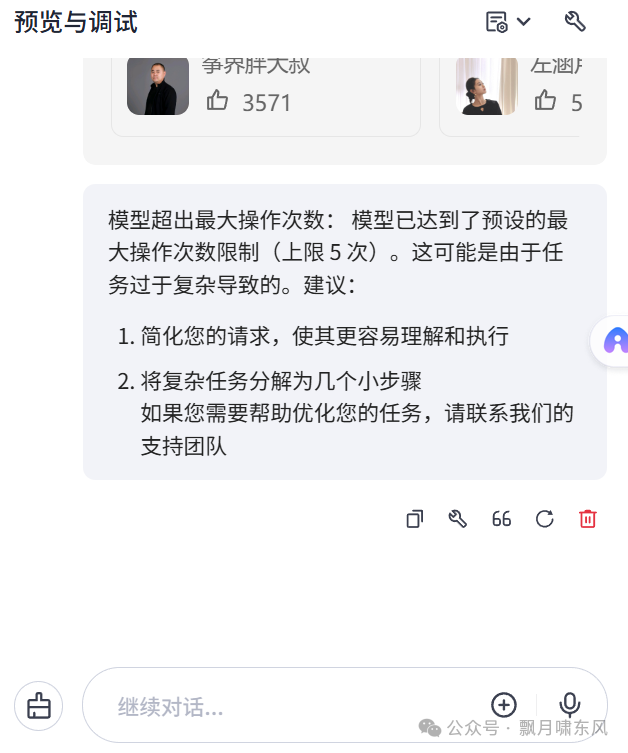
在DeepSeek r1出现后,很多厂商都跟进推出了深度思考模型。这些模型有时候会陷入沉思,一次次推理得出结论,又一次次推翻自己,循环往复,有时候5分钟都还在思考中。在上面搜索古筝视频的例子中,模型整理知识时却不会因为信息不足重新回到第一步搜索。这是因为厂商对模型行为做了限制。算力有限的情况下,降低单次调用的成本可以服务更多用户。用户体验也是主要原因。如果即时聊天迟迟得不到回应,用户就会失去耐心,甚至抱怨“应用卡死了,不好用”。这和大数据分析平台类似,数据处理得慢可能是别人的任务复杂,占用了资源,导致你没资源跑,也可能是你自己的任务太复杂,迟迟未处理完。商用的模型需要根据自身能力做限制,能回答多少就回答多少,比如DeepSeek输出:“需要注意用户要求的是所有级别,但搜索结果里的信息可能只涵盖一级到三级,甚至更高可能没提到。所以可能需要根据现有的搜索结果来整理,并说明更高级别的信息未在搜索结果中提供,建议参考其他来源。”。如果在火山引擎的AI开发测试环境,告诉它调用抖音视频插件搜索每首曲目的视频,插件调用5轮后,调试会报错“模型超出最大操作次数”。建议分解任务,分解任务相当于增加模型总调用次数,一个模型节点调用5次,把3个串联起来就能处理15次了。但更多的任务除了延长等待时间,还会消耗大量token(文字需要转换成token处理,大模型以token计费),增加调用成本,开发者需要自己衡量。
下一步:探索AI云应用开发平台
今天就先分享到这里,如果各位发现有讲得不对的地方,请不吝指正。下一篇分享如何创建自己的智能体解决复杂的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









