







什么是深度学习
人工智能已经出现很多年了,以往的AI产品还是需要点专业知识的。专家系统需要设置规则,机器学习依赖特征工程,但深度学习出现后,专家在AI模型的训练中作用大幅下降。这个有点像家长做小学思维题,把题目中的条件都用上,列方程就能求解,对辛苦思考各个条件关系、列式一步步计算的低年级小朋友来说,就是降维打击。之前深度学习没有那么普及,主要还是因为复杂的模型需要大量数据做训练,对机器硬件要求也高,后来互联网产生了大量数据,GPU芯片迭代升级,Google设计出Transformer算法,Open AI通过无监督预训练减少了对标签数据的依赖,深度学习就如鱼得水,在AI界呼风唤雨。
简单来说,深度学习就是设计一组方程式,计算未知数(参数),使得输入与输出两边的数据相等。这些方程式一般是简单方程的层层叠加。方程式越复杂,它就越能针对不同的输入和任务生成预期的输出。随着参数量增加,训练的成本也上升。DeepSeek之所以那么火,不是因为它效果比其他大模型好太多,而是因为它跟同参数量的模型比需要的硬件要求低,大大降低了本地化部署的成本,越来越多玩家入局搅动了市场。
本篇讲讲如何在PyTorch中如何使用深度学习模型解决实际问题。PyTorch是目前最常用的深度学习框架。
PyTorch官网:https://pytorch.org/
因为本文中不会涉及代码跟API介绍,仅分享过程和思路,用其他深度学习框架,如Tensorflow,也是可以的。
任务介绍- 医学影像报告异常检测
1. 赛题解读
赛题链接:https://tianchi.aliyun.com/competition/entrance/532328/information
这个任务是根据一组字符串description,比如“45 2 7 170…253”,进行17个类别的多标签分类,输出样例“1 15 16”。由于字符经过脱敏处理,即使是精通看CT影像的医生也无法利用专业知识看出什么毛病。可以理解成一个只会中文的医生看一份英文报告,跟什么都不懂的人比没有优势。任务提供了一个带标签(类别)的训练数据,和一个不带标签的测试数据。
这是一个序列转多标签分类的任务,跟之前介绍的机器学习任务不同,这次的数据只有1列人类看不懂的description,以往说特征工程决定上限的说法就不适用了,重点还是设计深度学习模型。
train和output的数据描述:

train的csv:

testA的csv:

csv的分隔符采用|,|,excel打开或pandas读入后会看到有多余的|,需要处理掉再进行模型训练。
2. 数据探索
简单探索train和testA两个数据集
-
查看训练集与测试集中
description的字符是否一致:一致 -
查看训练集与测试集中
description的最大长度:104 -
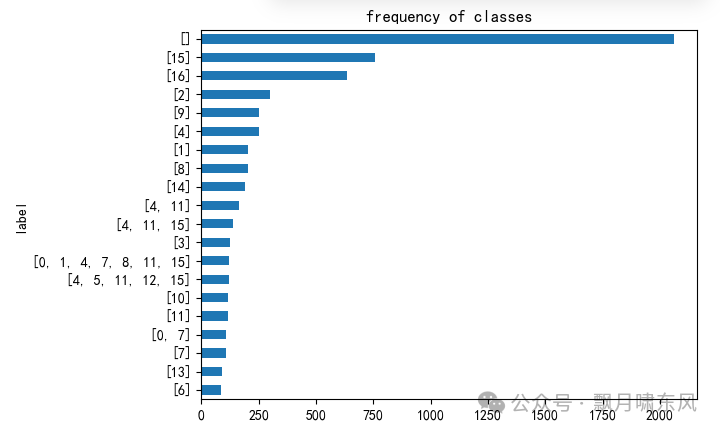
查看训练集中
label的分布:[]占比最高,类别不平衡
样本分布:

应用深度学习解决问题
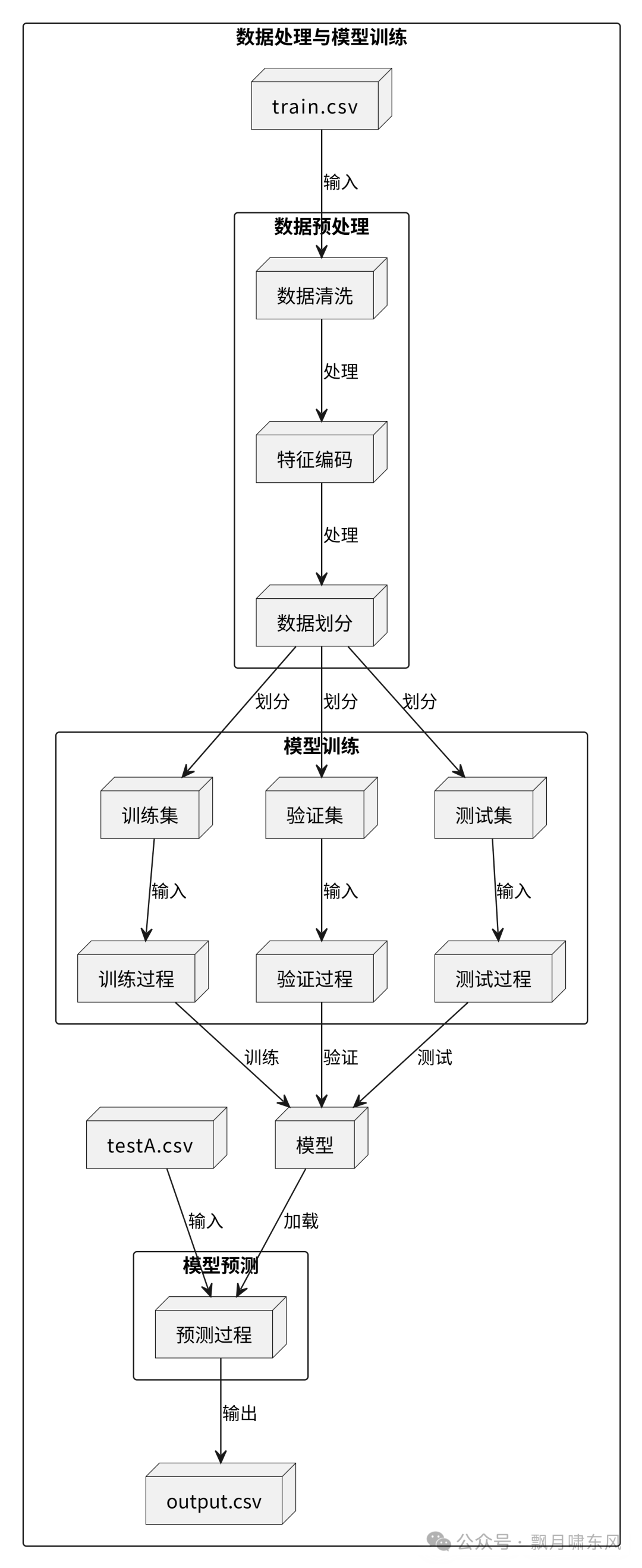
数据处理过程如下(下图由AI根据文章内容生成):
3. 数据预处理
-
对lable列应用多标签的独热编码(One-Hot Encoding)
把
label转换成17维度类型编码,比如[15]转换成[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1],[1,15]转换成[1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1],题目要求结果的prediction是17维向量,表示17个类别的预测概率,label要转换成同样的格式。 -
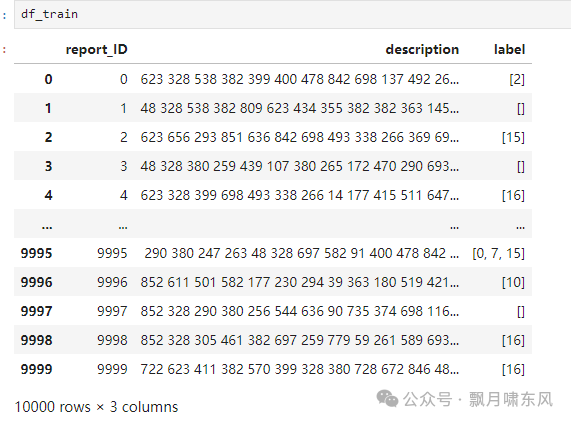
把
train的description列填充成长度为104(训练集和测试集中description的最大长度),让每个样本都有一样的序列长度。
转换前的train:
转换后的train(description的padding部分是0,没显示):
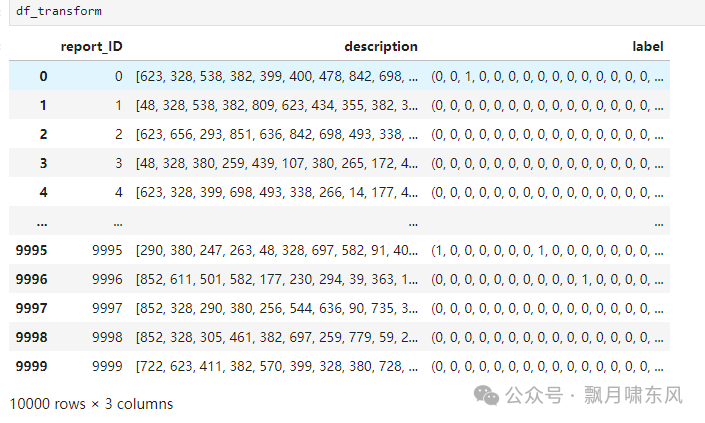
4. 设计深度学习模型
设计模型即设计包含未知数的方程式,我们把它看成俄罗斯方块的堆叠就好了,线性回归、CNN、RNN、Transformer等算法都是方块。“深度学习”中的“学习”,表示求解方程式的未知数,不包含学习设计方程式。
-
把原来的训练集按8:1:1划分为训练集、验证集、测试集
-
设计深度学习的隐藏层:
-
把每个字符编码成向量(embedding),词义相近的词转换后的向量相似,这也是特征提取的重要步骤。由于这个是脱敏后的数据,无法使用基于自然语言训练的embedding预训练模型。
-
使用LSTM、Transformer等模型提取输入序列的特征,这是一个字符串到分类向量的输出,不需要再输出字符串,所以只使用Transformer的encoder部分。
-
加入
torch.nn.Linear线性层进行分类,把上一步的输出数据映射到17维向量(因为损失函数BCEWithLogitsLoss会调用sigmoid把结果映射到0-1的概率,这里就不再用sigmoid了)。
-
-
按题目要求把损失函数设置为
BCEWithLogitsLoss,优化器选用Adam。题目要求的损失计算公式mlogloss:
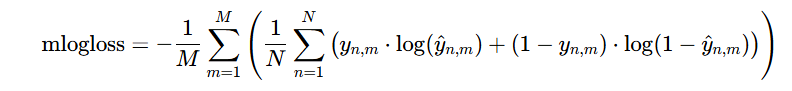
-
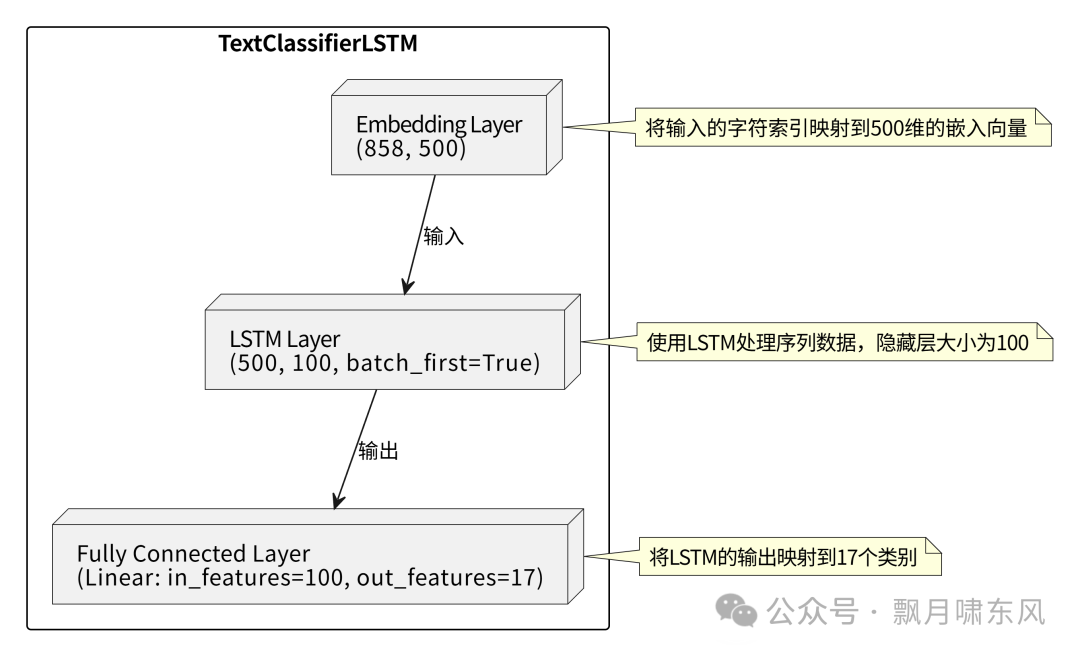
训练模型:相当于把输入和实际输出放上述设计的方程式,求解未知数(参数)。未知数初始化,代入方程式,计算输入和输出的差异
loss(损失函数),调整未知数的值(反向求导),重复以上步骤,让差异逐渐缩小,当验证集上的loss没有明显改善时,保存loss最小的模型的参数,提前停止训练。模型设计例子(下图由AI生成):
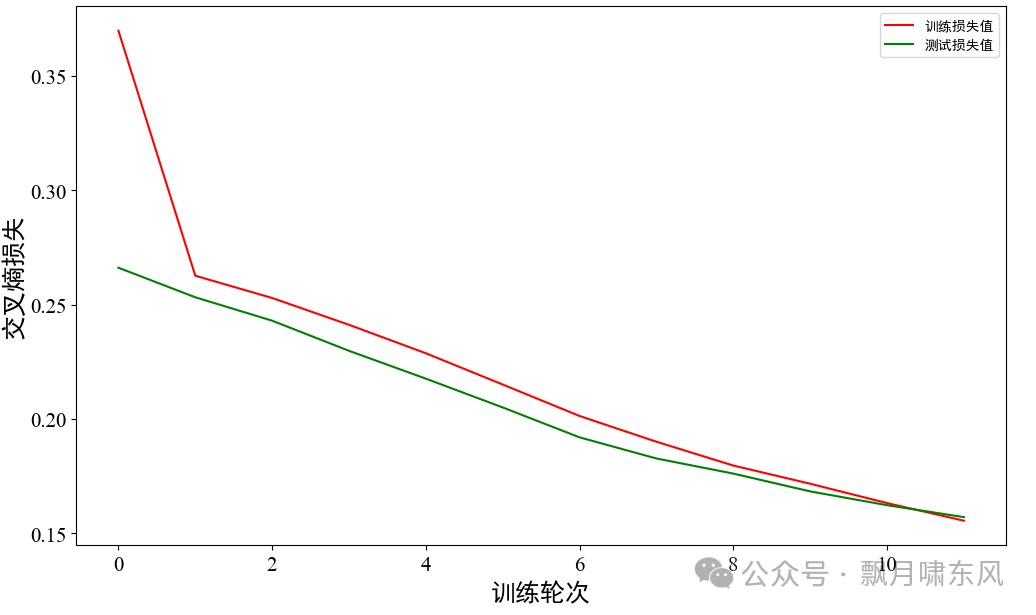
LSTM学习曲线:
5. 评估结果
得到了从输入到输出的方程组及所有未知数的解,就可以输入新的内容,让它计算输出。
-
把
testA的description列填充成长度为104的向量 -
y_pre_testA = model(x_test)得到模型的输出 -
y_pre_testA_p = torch.sigmoid(y_pre_testA),因为模型最后一步没有sigmoid,要先对model的输出做sigmoid,得到17维向量表示的概率。 -
按照要求保存并提交csv文件,注意分隔符是
,|,。
提交结果评估:
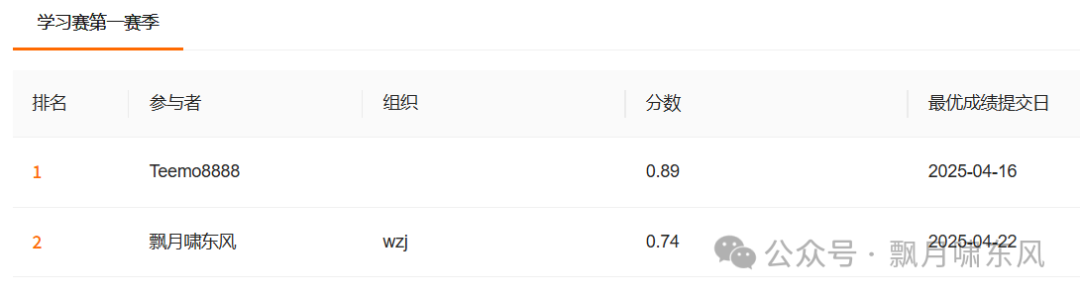
排行榜上只能看到自己和第一名的成绩。通常情况下,损失函数的值越小,模型性能越好。题目设定的分数是1-loss。第一名0.89分,我的提交是0.74分,即loss是0.26。
更多思考
loss是交叉熵,单看数值无法比较好坏。我把预测概率调成了随机数,用相同的损失函数在本地测试算得loss为0.8,预测无一正确(该样本17个类别都正确的为正确)。17个类别有2的17次方(131072)种组合,随便乱撞要撞中1个,理论上样本数要大于等于131072。
如果测的概率值调成固定的17类全为0,本地测试集loss是0.8,预测准确率为24%,但这个指标不具有参考价值,因为测试数据本身就存在类别不平衡的问题,只要全预测出现最多的类别,就能得到相对高的准确度。
代入场景解释,就是一个人去做了CT检测,影像结果说检测的所有器官都没有异常,他信以为真(前提他自我感觉良好),但要告诉他心肝脾肺肾都有问题,他肯定会去找医生要个解释,甚至还会投诉。人类医生解读CT报告,也有一个置信值,当他不是太自信时,就倾向于告诉患者未发现异常。
我们可以把全部预测为0看成一个最差的模型,如果经过训练后的模型,比它还差,就没有训练的意义了。全部预测0的模型,提交后loss显示为2.73,远高于本地计算的0.8。
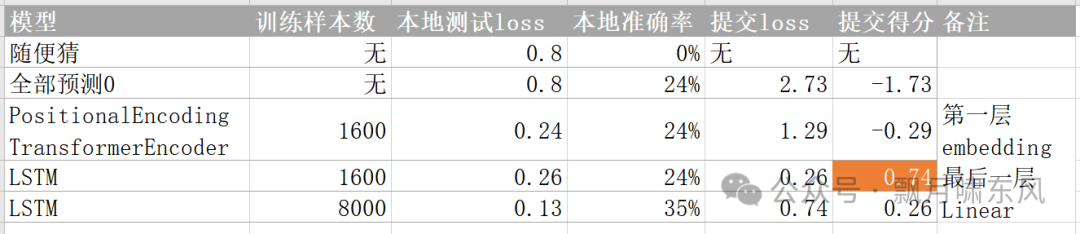
经过几轮测试,表现最好的是LSTM(长短期记忆网络),大语言模型的底层算法Transformer分数都偏低,估计是因为模型太复杂,把参数降到最低还是多,在小数据量上无法很好的训练。但LSTM加大样本量或增加模型参数后,虽然在本地取得更好的表现,但提交后分数反而变低,需要进一步优化,以获得更好的泛化性。
测试方案及结果对比(准确率为阈值=0.5时计算得出):
今天就先分享到这里,本文仅代表个人观点,部分表述不严谨,对深度学习有兴趣的伙伴请翻看专业书籍。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









